 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStability of Mean-Field Variational Inference
Jun 09, 2025Mean-field variational inference (MFVI) is a widely used method for approximating high-dimensional probability distributions by product measures. This paper studies the stability properties of the mean-field approximation when the target distribution varies within the class of strongly log-concave measures. We establish dimension-free Lipschitz continuity of the MFVI optimizer with respect to the target distribution, measured in the 2-Wasserstein distance, with Lipschitz constant inversely proportional to the log-concavity parameter. Under additional regularity conditions, we further show that the MFVI optimizer depends differentiably on the target potential and characterize the derivative by a partial differential equation. Methodologically, we follow a novel approach to MFVI via linearized optimal transport: the non-convex MFVI problem is lifted to a convex optimization over transport maps with a fixed base measure, enabling the use of calculus of variations and functional analysis. We discuss several applications of our results to robust Bayesian inference and empirical Bayes, including a quantitative Bernstein--von Mises theorem for MFVI, as well as to distributed stochastic control.
Estimating the Rate-Distortion Function by Wasserstein Gradient Descent
Oct 29, 2023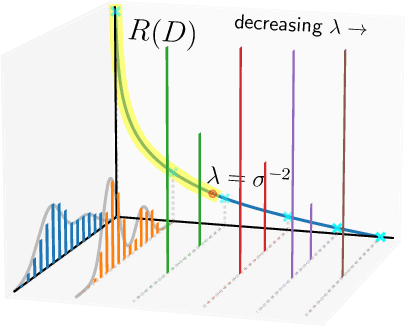

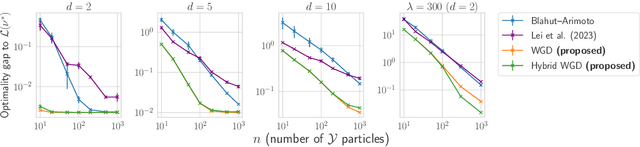
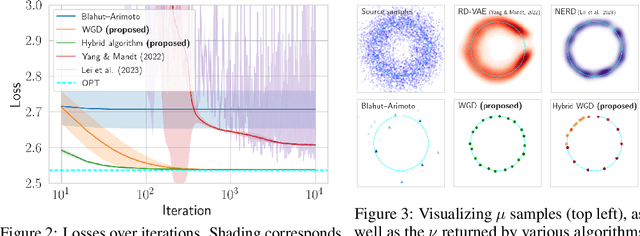
In the theory of lossy compression, the rate-distortion (R-D) function $R(D)$ describes how much a data source can be compressed (in bit-rate) at any given level of fidelity (distortion). Obtaining $R(D)$ for a given data source establishes the fundamental performance limit for all compression algorithms. We propose a new method to estimate $R(D)$ from the perspective of optimal transport. Unlike the classic Blahut--Arimoto algorithm which fixes the support of the reproduction distribution in advance, our Wasserstein gradient descent algorithm learns the support of the optimal reproduction distribution by moving particles. We prove its local convergence and analyze the sample complexity of our R-D estimator based on a connection to entropic optimal transport. Experimentally, we obtain comparable or tighter bounds than state-of-the-art neural network methods on low-rate sources while requiring considerably less tuning and computation effort. We also highlight a connection to maximum-likelihood deconvolution and introduce a new class of sources that can be used as test cases with known solutions to the R-D problem.
Convergence Rates for Regularized Optimal Transport via Quantization
Aug 31, 2022We study the convergence of divergence-regularized optimal transport as the regularization parameter vanishes. Sharp rates for general divergences including relative entropy or $L^{p}$ regularization, general transport costs and multi-marginal problems are obtained. A novel methodology using quantization and martingale couplings is suitable for non-compact marginals and achieves, in particular, the sharp leading-order term of entropically regularized 2-Wasserstein distance for all marginals with finite $(2+\delta)$-moment.