 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussian Copula Models for Nonignorable Missing Data Using Auxiliary Marginal Quantiles
Jun 05, 2024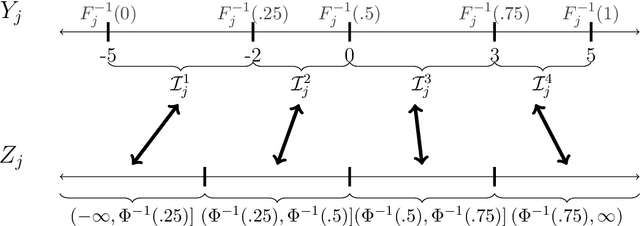

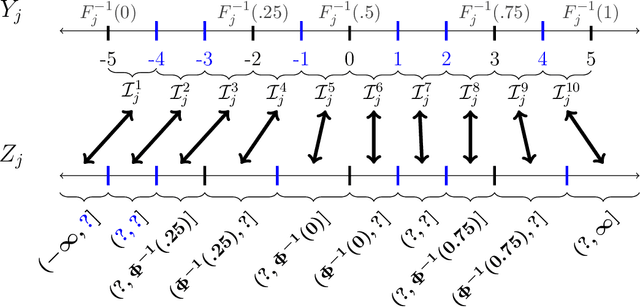

We present an approach for modeling and imputation of nonignorable missing data under Gaussian copulas. The analyst posits a set of quantiles of the marginal distributions of the study variables, for example, reflecting information from external data sources or elicited expert opinion. When these quantiles are accurately specified, we prove it is possible to consistently estimate the copula correlation and perform multiple imputation in the presence of nonignorable missing data. We develop algorithms for estimation and imputation that are computationally efficient, which we evaluate in simulation studies of multiple imputation inferences. We apply the model to analyze associations between lead exposure levels and end-of-grade test scores for 170,000 students in North Carolina. These measurements are not missing at random, as children deemed at-risk for high lead exposure are more likely to be measured. We construct plausible marginal quantiles for lead exposure using national statistics provided by the Centers for Disease Control and Prevention. Complete cases and missing at random analyses appear to underestimate the relationships between certain variables and end-of-grade test scores, while multiple imputation inferences under our model support stronger adverse associations between lead exposure and educational outcomes.
Monte Carlo inference for semiparametric Bayesian regression
Jun 08, 2023Data transformations are essential for broad applicability of parametric regression models. However, for Bayesian analysis, joint inference of the transformation and model parameters typically involves restrictive parametric transformations or nonparametric representations that are computationally inefficient and cumbersome for implementation and theoretical analysis, which limits their usability in practice. This paper introduces a simple, general, and efficient strategy for joint posterior inference of an unknown transformation and all regression model parameters. The proposed approach directly targets the posterior distribution of the transformation by linking it with the marginal distributions of the independent and dependent variables, and then deploys a Bayesian nonparametric model via the Bayesian bootstrap. Crucially, this approach delivers (1) joint posterior consistency under general conditions, including multiple model misspecifications, and (2) efficient Monte Carlo (not Markov chain Monte Carlo) inference for the transformation and all parameters for important special cases. These tools apply across a variety of data domains, including real-valued, integer-valued, compactly-supported, and positive data. Simulation studies and an empirical application demonstrate the effectiveness and efficiency of this strategy for semiparametric Bayesian analysis with linear models, quantile regression, and Gaussian processes.
Bayesian adaptive and interpretable functional regression for exposure profiles
Mar 01, 2022
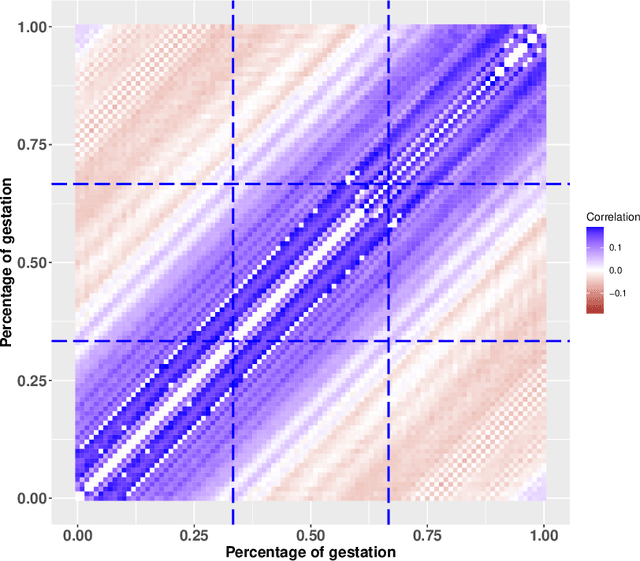


Pollutant exposures during gestation are a known and adverse factor for birth and health outcomes. However, the links between prenatal air pollution exposures and educational outcomes are less clear, in particular the critical windows of susceptibility during pregnancy. Using a large cohort of students in North Carolina, we study prenatal $\mbox{PM}_{2.5}$ exposures recorded at near-continuous resolutions and linked to 4th end-of-grade reading scores. We develop a locally-adaptive Bayesian regression model for scalar responses with functional and scalar predictors. The proposed model pairs a B-spline basis expansion with dynamic shrinkage priors to capture both smooth and rapidly-changing features in the regression surface. The local adaptivity is manifested in more accurate point estimates and more precise uncertainty quantification than existing methods on simulated data. The model is accompanied by a highly scalable Gibbs sampler for fully Bayesian inference on large datasets. In addition, we describe broad limitations with the interpretability of scalar-on-function regression models, and introduce new decision analysis tools to guide the model interpretation. Using these methods, we identify a period within the third trimester as the critical window of susceptibility to $\mbox{PM}_{2.5}$ exposure.
Conjugate priors for count and rounded data regression
Nov 10, 2021


Discrete data are abundant and often arise as counts or rounded data. Yet even for linear regression models, conjugate priors and closed-form posteriors are typically unavailable, which necessitates approximations such as MCMC for posterior inference. For a broad class of count and rounded data regression models, we introduce conjugate priors that enable closed-form posterior inference. Key posterior and predictive functionals are computable analytically or via direct Monte Carlo simulation. Crucially, the predictive distributions are discrete to match the support of the data and can be evaluated or simulated jointly across multiple covariate values. These tools are broadly useful for linear regression, nonlinear models via basis expansions, and model and variable selection. Multiple simulation studies demonstrate significant advantages in computing, predictive modeling, and selection relative to existing alternatives.
Warped Dynamic Linear Models for Time Series of Counts
Oct 27, 2021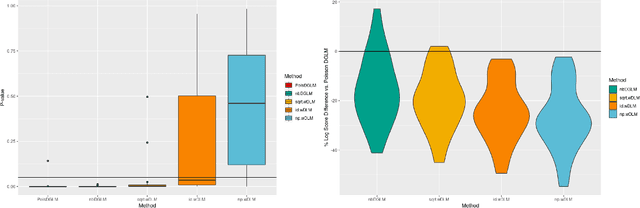
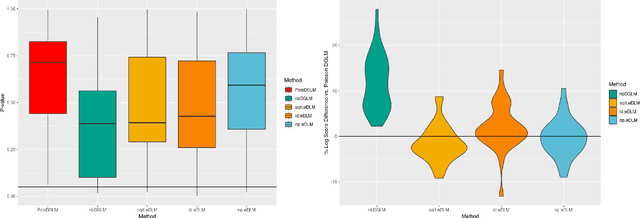
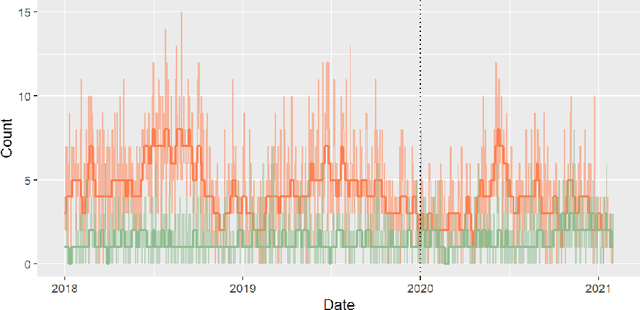
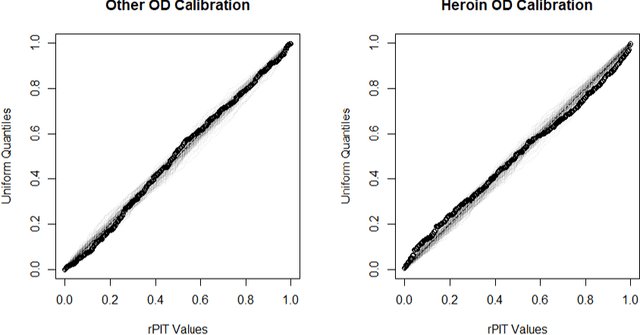
Dynamic Linear Models (DLMs) are commonly employed for time series analysis due to their versatile structure, simple recursive updating, and probabilistic forecasting. However, the options for count time series are limited: Gaussian DLMs require continuous data, while Poisson-based alternatives often lack sufficient modeling flexibility. We introduce a novel methodology for count time series by warping a Gaussian DLM. The warping function has two components: a transformation operator that provides distributional flexibility and a rounding operator that ensures the correct support for the discrete data-generating process. Importantly, we develop conjugate inference for the warped DLM, which enables analytic and recursive updates for the state space filtering and smoothing distributions. We leverage these results to produce customized and efficient computing strategies for inference and forecasting, including Monte Carlo simulation for offline analysis and an optimal particle filter for online inference. This framework unifies and extends a variety of discrete time series models and is valid for natural counts, rounded values, and multivariate observations. Simulation studies illustrate the excellent forecasting capabilities of the warped DLM. The proposed approach is applied to a multivariate time series of daily overdose counts and demonstrates both modeling and computational successes.
Subset selection for linear mixed models
Jul 27, 2021



Linear mixed models (LMMs) are instrumental for regression analysis with structured dependence, such as grouped, clustered, or multilevel data. However, selection among the covariates--while accounting for this structured dependence--remains a challenge. We introduce a Bayesian decision analysis for subset selection with LMMs. Using a Mahalanobis loss function that incorporates the structured dependence, we derive optimal linear actions for any subset of covariates and under any Bayesian LMM. Crucially, these actions inherit shrinkage or regularization and uncertainty quantification from the underlying Bayesian LMM. Rather than selecting a single "best" subset, which is often unstable and limited in its information content, we collect the acceptable family of subsets that nearly match the predictive ability of the "best" subset. The acceptable family is summarized by its smallest member and key variable importance metrics. Customized subset search and out-of-sample approximation algorithms are provided for more scalable computing. These tools are applied to simulated data and a longitudinal physical activity dataset, and in both cases demonstrate excellent prediction, estimation, and selection ability.
Semiparametric count data regression for self-reported mental health
Jun 16, 2021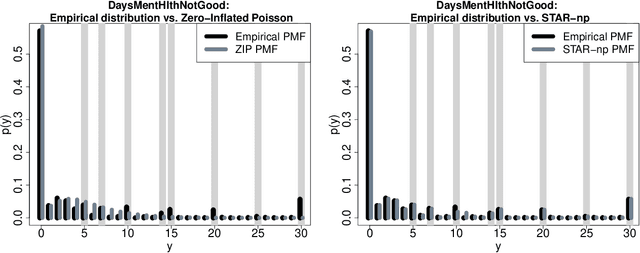


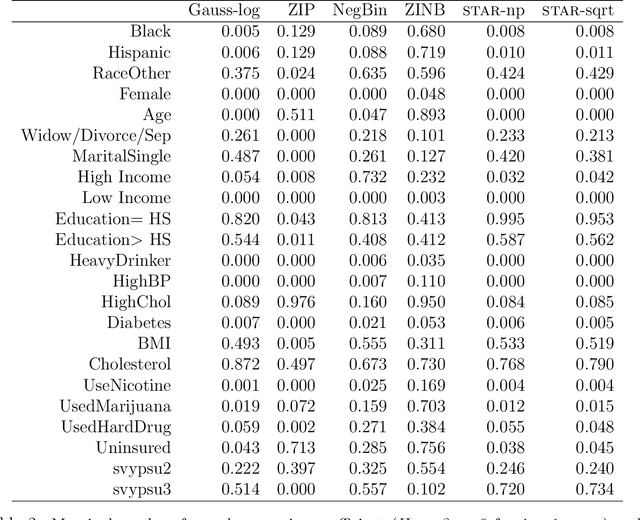
"For how many days during the past 30 days was your mental health not good?" The responses to this question measure self-reported mental health and can be linked to important covariates in the National Health and Nutrition Examination Survey (NHANES). However, these count variables present major distributional challenges: the data are overdispersed, zero-inflated, bounded by 30, and heaped in five- and seven-day increments. To meet these challenges, we design a semiparametric estimation and inference framework for count data regression. The data-generating process is defined by simultaneously transforming and rounding (STAR) a latent Gaussian regression model. The transformation is estimated nonparametrically and the rounding operator ensures the correct support for the discrete and bounded data. Maximum likelihood estimators are computed using an EM algorithm that is compatible with any continuous data model estimable by least squares. STAR regression includes asymptotic hypothesis testing and confidence intervals, variable selection via information criteria, and customized diagnostics. Simulation studies validate the utility of this framework. STAR is deployed to study the factors associated with self-reported mental health and demonstrates substantial improvements in goodness-of-fit compared to existing count data regression models.
Bayesian subset selection and variable importance for interpretable prediction and classification
Apr 20, 2021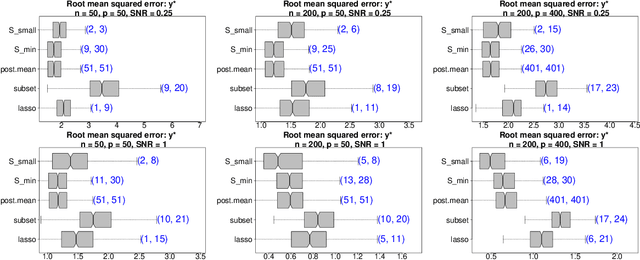


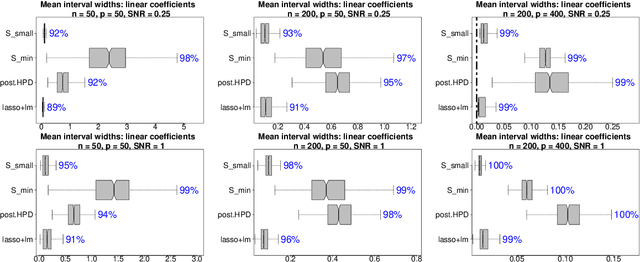
Subset selection is a valuable tool for interpretable learning, scientific discovery, and data compression. However, classical subset selection is often eschewed due to selection instability, computational bottlenecks, and lack of post-selection inference. We address these challenges from a Bayesian perspective. Given any Bayesian predictive model $\mathcal{M}$, we elicit predictively-competitive subsets using linear decision analysis. The approach is customizable for (local) prediction or classification and provides interpretable summaries of $\mathcal{M}$. A key quantity is the acceptable family of subsets, which leverages the predictive distribution from $\mathcal{M}$ to identify subsets that offer nearly-optimal prediction. The acceptable family spawns new (co-) variable importance metrics based on whether variables (co-) appear in all, some, or no acceptable subsets. Crucially, the linear coefficients for any subset inherit regularization and predictive uncertainty quantification via $\mathcal{M}$. The proposed approach exhibits excellent prediction, interval estimation, and variable selection for simulated data, including $p=400 > n$. These tools are applied to a large education dataset with highly correlated covariates, where the acceptable family is especially useful. Our analysis provides unique insights into the combination of environmental, socioeconomic, and demographic factors that predict educational outcomes, and features highly competitive prediction with remarkable stability.
Fast and Optimal Bayesian Approximations for Targeted Prediction
Jun 23, 2020



Prediction is critical for decision-making under uncertainty and lends validity to statistical inference. With targeted prediction, the goal is to optimize predictions for specific decision tasks of interest, which we represent via functionals. Using tools for predictive decision analysis, we design a framework for constructing optimal, scalable, and simple approximations for targeted prediction under a Bayesian model. For a wide variety of approximations and (penalized) loss functions, we derive a convenient representation of the optimal targeted approximation that yields efficient and interpretable solutions. Customized out-of-sample predictive metrics are developed to evaluate and compare among targeted predictors. Through careful use of the posterior predictive distribution, we introduce a procedure that identifies a set of near-optimal predictors. These acceptable models can include different model forms or subsets of covariates and provide unique insights into the features and level of complexity needed for accurate targeted prediction. Simulations demonstrate excellent prediction, estimation, and variable selection capabilities. Targeted approximations are constructed for physical activity data from the National Health and Nutrition Examination Survey (NHANES) to better predict and understand the characteristics of intraday physical activity.
A Simultaneous Transformation and Rounding Approach for Modeling Integer-Valued Data
Jun 27, 2019



We propose a simple yet powerful framework for modeling integer-valued data. The integer-valued data are modeled by Simultaneously Transforming And Rounding (STAR) a continuous-valued process, where the transformation may be known or learned from the data. Implicitly, STAR formalizes the commonly-applied yet incoherent procedure of (i) transforming integer-valued data and subsequently (ii) modeling the transformed data using Gaussian models. Importantly, STAR is well-defined for integer-valued data, which is reflected in predictive accuracy, and is designed to account for zero-inflation, bounded or censored data, and over- or underdispersion. Efficient computation is available via an MCMC algorithm, which provides a mechanism for direct adaptation of successful Bayesian methods for continuous data to the integer-valued data setting. Using the STAR framework, we develop new linear regression models, additive models, and Bayesian Additive Regression Trees (BART) for integer-valued data, which demonstrate substantial improvements in performance relative to existing regression models for a variety of simulated and real datasets.