 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian subset selection and variable importance for interpretable prediction and classification
Paper and Code
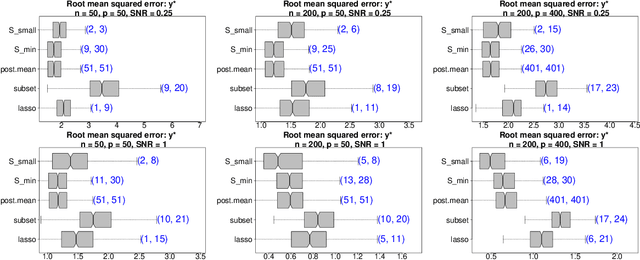


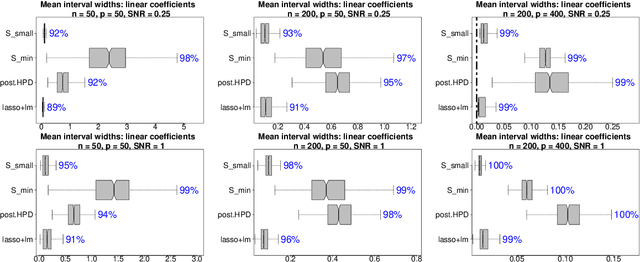
Subset selection is a valuable tool for interpretable learning, scientific discovery, and data compression. However, classical subset selection is often eschewed due to selection instability, computational bottlenecks, and lack of post-selection inference. We address these challenges from a Bayesian perspective. Given any Bayesian predictive model $\mathcal{M}$, we elicit predictively-competitive subsets using linear decision analysis. The approach is customizable for (local) prediction or classification and provides interpretable summaries of $\mathcal{M}$. A key quantity is the acceptable family of subsets, which leverages the predictive distribution from $\mathcal{M}$ to identify subsets that offer nearly-optimal prediction. The acceptable family spawns new (co-) variable importance metrics based on whether variables (co-) appear in all, some, or no acceptable subsets. Crucially, the linear coefficients for any subset inherit regularization and predictive uncertainty quantification via $\mathcal{M}$. The proposed approach exhibits excellent prediction, interval estimation, and variable selection for simulated data, including $p=400 > n$. These tools are applied to a large education dataset with highly correlated covariates, where the acceptable family is especially useful. Our analysis provides unique insights into the combination of environmental, socioeconomic, and demographic factors that predict educational outcomes, and features highly competitive prediction with remarkable stability.