 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the Validity and Practical Usefulness of AI/ML Evaluations Using an Estimands Framework
Jun 14, 2024
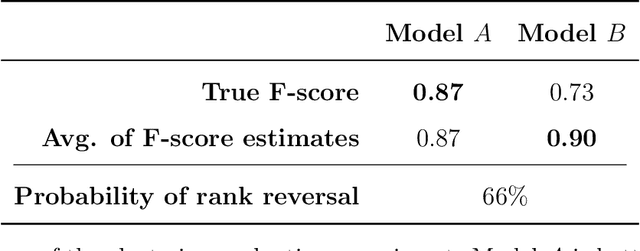

Commonly, AI or machine learning (ML) models are evaluated on benchmark datasets. This practice supports innovative methodological research, but benchmark performance can be poorly correlated with performance in real-world applications -- a construct validity issue. To improve the validity and practical usefulness of evaluations, we propose using an estimands framework adapted from international clinical trials guidelines. This framework provides a systematic structure for inference and reporting in evaluations, emphasizing the importance of a well-defined estimation target. We illustrate our proposal on examples of commonly used evaluation methodologies - involving cross-validation, clustering evaluation, and LLM benchmarking - that can lead to incorrect rankings of competing models (rank reversals) with high probability, even when performance differences are large. We demonstrate how the estimands framework can help uncover underlying issues, their causes, and potential solutions. Ultimately, we believe this framework can improve the validity of evaluations through better-aligned inference, and help decision-makers and model users interpret reported results more effectively.
Gaussian Copula Models for Nonignorable Missing Data Using Auxiliary Marginal Quantiles
Jun 05, 2024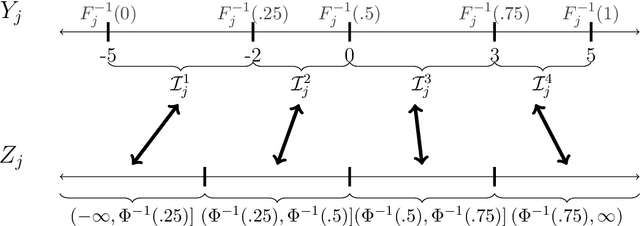

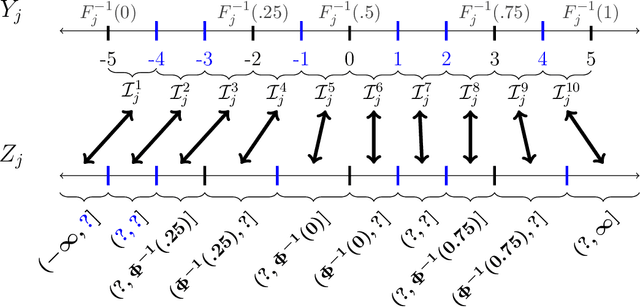

We present an approach for modeling and imputation of nonignorable missing data under Gaussian copulas. The analyst posits a set of quantiles of the marginal distributions of the study variables, for example, reflecting information from external data sources or elicited expert opinion. When these quantiles are accurately specified, we prove it is possible to consistently estimate the copula correlation and perform multiple imputation in the presence of nonignorable missing data. We develop algorithms for estimation and imputation that are computationally efficient, which we evaluate in simulation studies of multiple imputation inferences. We apply the model to analyze associations between lead exposure levels and end-of-grade test scores for 170,000 students in North Carolina. These measurements are not missing at random, as children deemed at-risk for high lead exposure are more likely to be measured. We construct plausible marginal quantiles for lead exposure using national statistics provided by the Centers for Disease Control and Prevention. Complete cases and missing at random analyses appear to underestimate the relationships between certain variables and end-of-grade test scores, while multiple imputation inferences under our model support stronger adverse associations between lead exposure and educational outcomes.
How to Evaluate Entity Resolution Systems: An Entity-Centric Framework with Application to Inventor Name Disambiguation
Apr 08, 2024



Entity resolution (record linkage, microclustering) systems are notoriously difficult to evaluate. Looking for a needle in a haystack, traditional evaluation methods use sophisticated, application-specific sampling schemes to find matching pairs of records among an immense number of non-matches. We propose an alternative that facilitates the creation of representative, reusable benchmark data sets without necessitating complex sampling schemes. These benchmark data sets can then be used for model training and a variety of evaluation tasks. Specifically, we propose an entity-centric data labeling methodology that integrates with a unified framework for monitoring summary statistics, estimating key performance metrics such as cluster and pairwise precision and recall, and analyzing root causes for errors. We validate the framework in an application to inventor name disambiguation and through simulation studies. Software: https://github.com/OlivierBinette/er-evaluation/