 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the Validity and Practical Usefulness of AI/ML Evaluations Using an Estimands Framework
Jun 14, 2024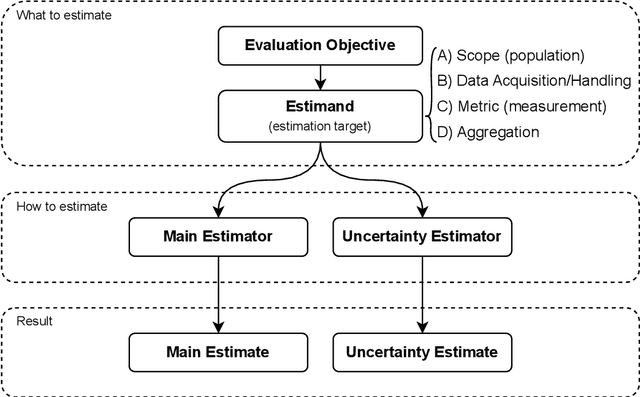
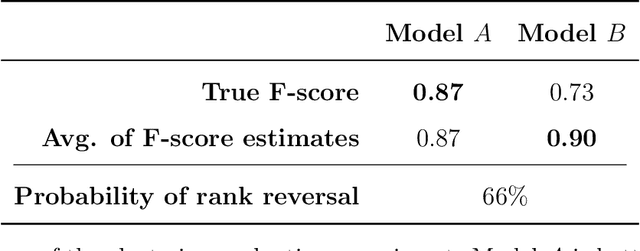

Commonly, AI or machine learning (ML) models are evaluated on benchmark datasets. This practice supports innovative methodological research, but benchmark performance can be poorly correlated with performance in real-world applications -- a construct validity issue. To improve the validity and practical usefulness of evaluations, we propose using an estimands framework adapted from international clinical trials guidelines. This framework provides a systematic structure for inference and reporting in evaluations, emphasizing the importance of a well-defined estimation target. We illustrate our proposal on examples of commonly used evaluation methodologies - involving cross-validation, clustering evaluation, and LLM benchmarking - that can lead to incorrect rankings of competing models (rank reversals) with high probability, even when performance differences are large. We demonstrate how the estimands framework can help uncover underlying issues, their causes, and potential solutions. Ultimately, we believe this framework can improve the validity of evaluations through better-aligned inference, and help decision-makers and model users interpret reported results more effectively.
How to Evaluate Entity Resolution Systems: An Entity-Centric Framework with Application to Inventor Name Disambiguation
Apr 08, 2024



Entity resolution (record linkage, microclustering) systems are notoriously difficult to evaluate. Looking for a needle in a haystack, traditional evaluation methods use sophisticated, application-specific sampling schemes to find matching pairs of records among an immense number of non-matches. We propose an alternative that facilitates the creation of representative, reusable benchmark data sets without necessitating complex sampling schemes. These benchmark data sets can then be used for model training and a variety of evaluation tasks. Specifically, we propose an entity-centric data labeling methodology that integrates with a unified framework for monitoring summary statistics, estimating key performance metrics such as cluster and pairwise precision and recall, and analyzing root causes for errors. We validate the framework in an application to inventor name disambiguation and through simulation studies. Software: https://github.com/OlivierBinette/er-evaluation/
PatentsView-Evaluation: Evaluation Datasets and Tools to Advance Research on Inventor Name Disambiguation
Jan 09, 2023

We present PatentsView-Evaluation, a Python package that enables researchers to evaluate the performance of inventor name disambiguation systems such as PatentsView.org. The package includes benchmark datasets and evaluation tools, and aims to advance research on inventor name disambiguation by providing access to high-quality evaluation data and improving evaluation standards.
Estimating the Performance of Entity Resolution Algorithms: Lessons Learned Through PatentsView.org
Oct 03, 2022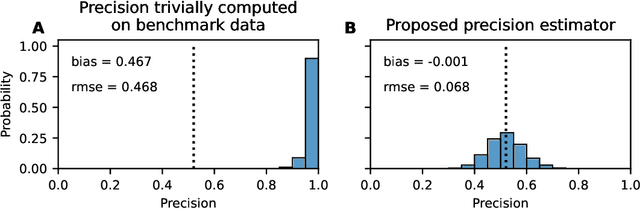
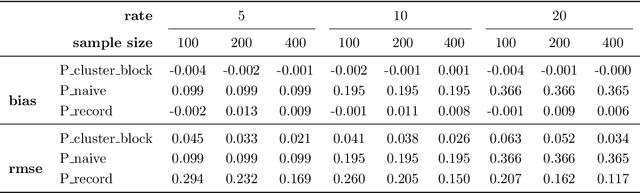
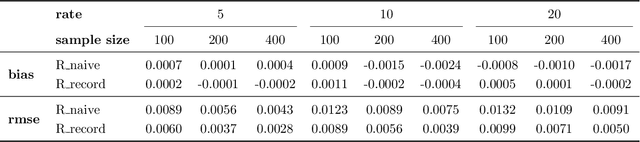
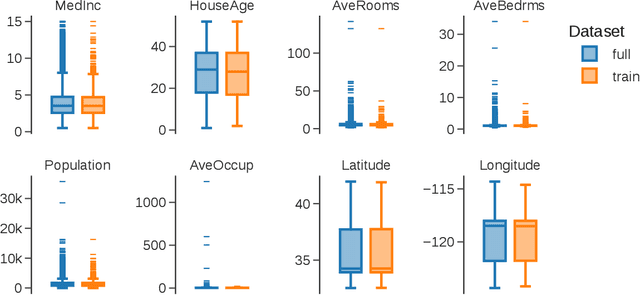
This paper introduces a novel evaluation methodology for entity resolution algorithms. It is motivated by PatentsView.org, a U.S. Patents and Trademarks Office patent data exploration tool that disambiguates patent inventors using an entity resolution algorithm. We provide a data collection methodology and tailored performance estimators that account for sampling biases. Our approach is simple, practical and principled -- key characteristics that allow us to paint the first representative picture of PatentsView's disambiguation performance. This approach is used to inform PatentsView's users of the reliability of the data and to allow the comparison of competing disambiguation algorithms.
(Almost) All of Entity Resolution
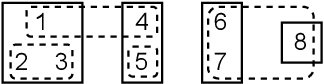
Aug 10, 2020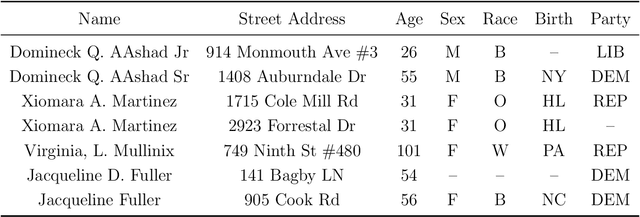


Whether the goal is to estimate the number of people that live in a congressional district, to estimate the number of individuals that have died in an armed conflict, or to disambiguate individual authors using bibliographic data, all these applications have a common theme - integrating information from multiple sources. Before such questions can be answered, databases must be cleaned and integrated in a systematic and accurate way, commonly known as record linkage, de-duplication, or entity resolution. In this article, we review motivational applications and seminal papers that have led to the growth of this area. Specifically, we review the foundational work that began in the 1940's and 50's that have led to modern probabilistic record linkage. We review clustering approaches to entity resolution, semi- and fully supervised methods, and canonicalization, which are being used throughout industry and academia in applications such as human rights, official statistics, medicine, citation networks, among others. Finally, we discuss current research topics of practical importance.