 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Evaluate Entity Resolution Systems: An Entity-Centric Framework with Application to Inventor Name Disambiguation
Apr 08, 2024



Entity resolution (record linkage, microclustering) systems are notoriously difficult to evaluate. Looking for a needle in a haystack, traditional evaluation methods use sophisticated, application-specific sampling schemes to find matching pairs of records among an immense number of non-matches. We propose an alternative that facilitates the creation of representative, reusable benchmark data sets without necessitating complex sampling schemes. These benchmark data sets can then be used for model training and a variety of evaluation tasks. Specifically, we propose an entity-centric data labeling methodology that integrates with a unified framework for monitoring summary statistics, estimating key performance metrics such as cluster and pairwise precision and recall, and analyzing root causes for errors. We validate the framework in an application to inventor name disambiguation and through simulation studies. Software: https://github.com/OlivierBinette/er-evaluation/
Asymptotics of Bayesian Uncertainty Estimation in Random Features Regression
Jun 06, 2023In this paper we compare and contrast the behavior of the posterior predictive distribution to the risk of the maximum a posteriori estimator for the random features regression model in the overparameterized regime. We will focus on the variance of the posterior predictive distribution (Bayesian model average) and compare its asymptotics to that of the risk of the MAP estimator. In the regime where the model dimensions grow faster than any constant multiple of the number of samples, asymptotic agreement between these two quantities is governed by the phase transition in the signal-to-noise ratio. They also asymptotically agree with each other when the number of samples grow faster than any constant multiple of model dimensions. Numerical simulations illustrate finer distributional properties of the two quantities for finite dimensions. We conjecture they have Gaussian fluctuations and exhibit similar properties as found by previous authors in a Gaussian sequence model, which is of independent theoretical interest.
Estimating the Performance of Entity Resolution Algorithms: Lessons Learned Through PatentsView.org
Oct 03, 2022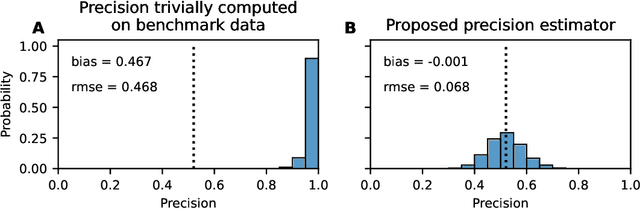
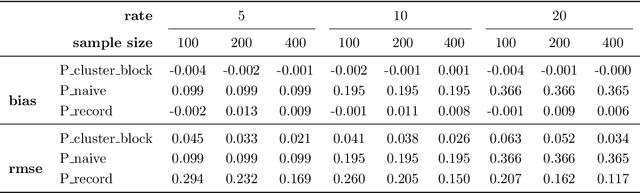
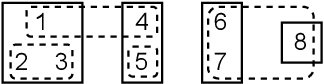
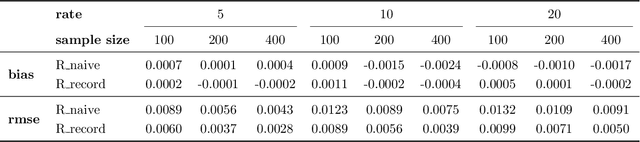
This paper introduces a novel evaluation methodology for entity resolution algorithms. It is motivated by PatentsView.org, a U.S. Patents and Trademarks Office patent data exploration tool that disambiguates patent inventors using an entity resolution algorithm. We provide a data collection methodology and tailored performance estimators that account for sampling biases. Our approach is simple, practical and principled -- key characteristics that allow us to paint the first representative picture of PatentsView's disambiguation performance. This approach is used to inform PatentsView's users of the reliability of the data and to allow the comparison of competing disambiguation algorithms.