 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the Validity and Practical Usefulness of AI/ML Evaluations Using an Estimands Framework
Paper and Code
Jun 14, 2024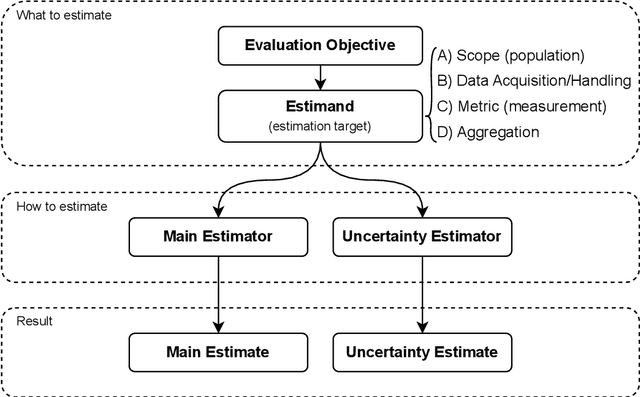
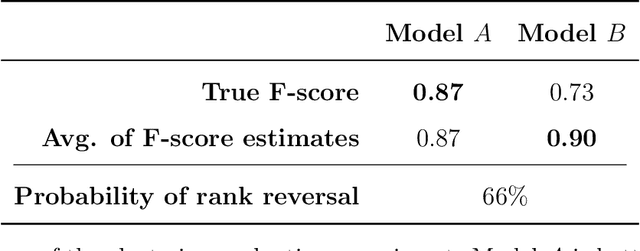
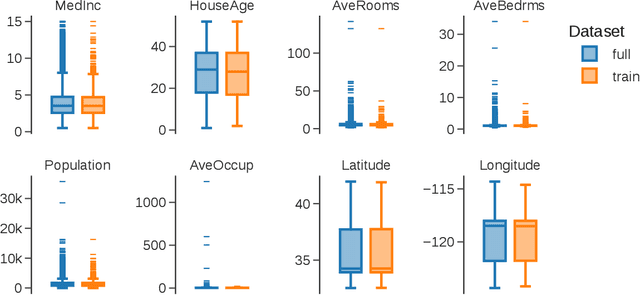

Commonly, AI or machine learning (ML) models are evaluated on benchmark datasets. This practice supports innovative methodological research, but benchmark performance can be poorly correlated with performance in real-world applications -- a construct validity issue. To improve the validity and practical usefulness of evaluations, we propose using an estimands framework adapted from international clinical trials guidelines. This framework provides a systematic structure for inference and reporting in evaluations, emphasizing the importance of a well-defined estimation target. We illustrate our proposal on examples of commonly used evaluation methodologies - involving cross-validation, clustering evaluation, and LLM benchmarking - that can lead to incorrect rankings of competing models (rank reversals) with high probability, even when performance differences are large. We demonstrate how the estimands framework can help uncover underlying issues, their causes, and potential solutions. Ultimately, we believe this framework can improve the validity of evaluations through better-aligned inference, and help decision-makers and model users interpret reported results more effectively.