 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemiparametric count data regression for self-reported mental health
Paper and Code
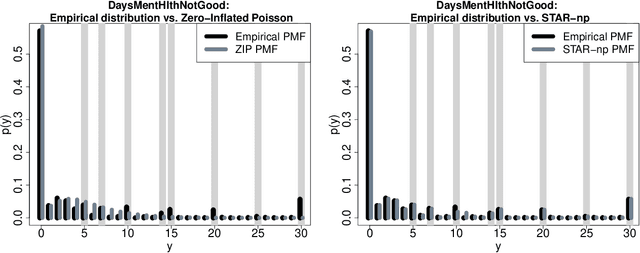


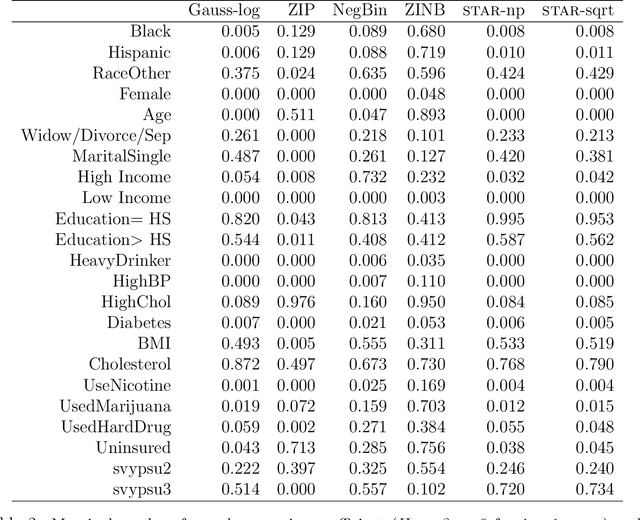
"For how many days during the past 30 days was your mental health not good?" The responses to this question measure self-reported mental health and can be linked to important covariates in the National Health and Nutrition Examination Survey (NHANES). However, these count variables present major distributional challenges: the data are overdispersed, zero-inflated, bounded by 30, and heaped in five- and seven-day increments. To meet these challenges, we design a semiparametric estimation and inference framework for count data regression. The data-generating process is defined by simultaneously transforming and rounding (STAR) a latent Gaussian regression model. The transformation is estimated nonparametrically and the rounding operator ensures the correct support for the discrete and bounded data. Maximum likelihood estimators are computed using an EM algorithm that is compatible with any continuous data model estimable by least squares. STAR regression includes asymptotic hypothesis testing and confidence intervals, variable selection via information criteria, and customized diagnostics. Simulation studies validate the utility of this framework. STAR is deployed to study the factors associated with self-reported mental health and demonstrates substantial improvements in goodness-of-fit compared to existing count data regression models.