 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Editing for Large Language Model with Knowledge Neuronal Ensemble
Dec 30, 2024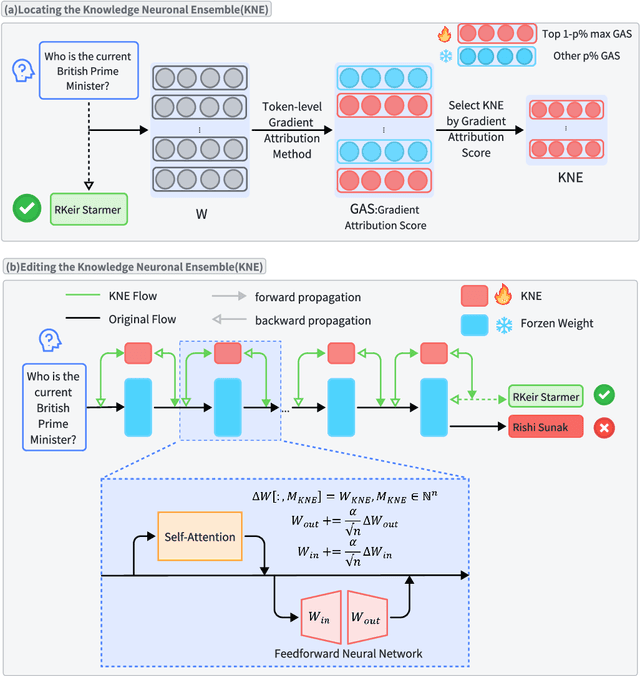
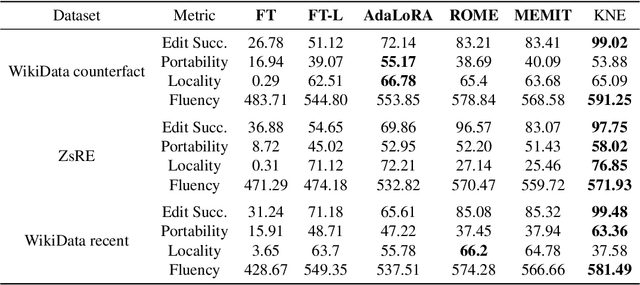
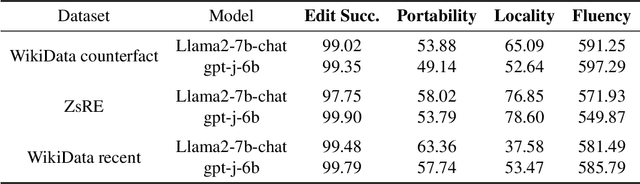
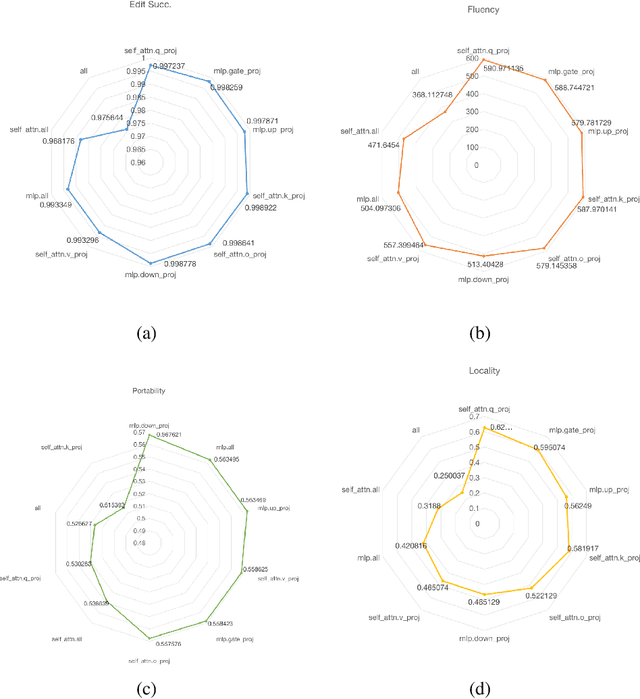
As real-world knowledge is constantly evolving, ensuring the timeliness and accuracy of a model's knowledge is crucial. This has made knowledge editing in large language models increasingly important. However, existing knowledge editing methods face several challenges, including parameter localization coupling, imprecise localization, and a lack of dynamic interaction across layers. In this paper, we propose a novel knowledge editing method called Knowledge Neuronal Ensemble (KNE). A knowledge neuronal ensemble represents a group of neurons encoding specific knowledge, thus mitigating the issue of frequent parameter modification caused by coupling in parameter localization. The KNE method enhances the precision and accuracy of parameter localization by computing gradient attribution scores for each parameter at each layer. During the editing process, only the gradients and losses associated with the knowledge neuronal ensemble are computed, with error backpropagation performed accordingly, ensuring dynamic interaction and collaborative updates among parameters. Experimental results on three widely used knowledge editing datasets show that the KNE method significantly improves the accuracy of knowledge editing and achieves, or even exceeds, the performance of the best baseline methods in portability and locality metrics.
T3: A Novel Zero-shot Transfer Learning Framework Iteratively Training on an Assistant Task for a Target Task
Sep 26, 2024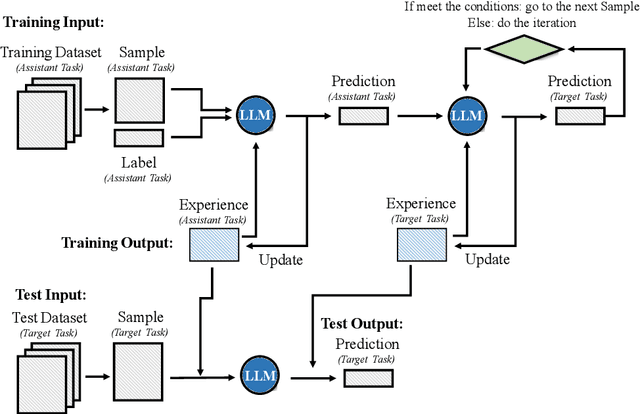
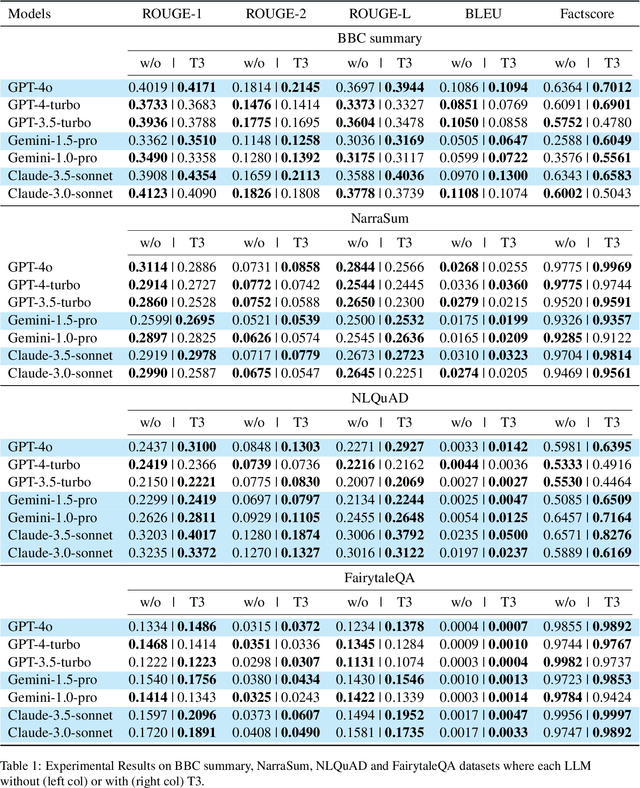
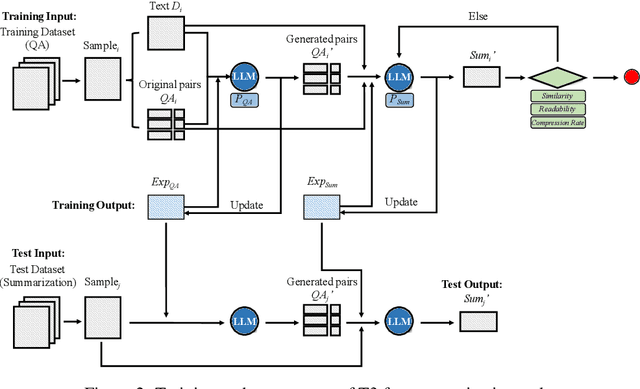
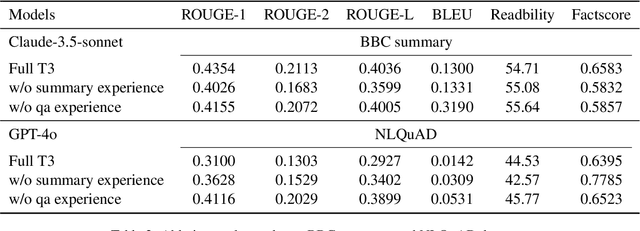
Long text summarization, gradually being essential for efficiently processing large volumes of information, stays challenging for Large Language Models (LLMs) such as GPT and LLaMA families because of the insufficient open-sourced training datasets and the high requirement of contextual details dealing. To address the issue, we design a novel zero-shot transfer learning framework, abbreviated as T3, to iteratively training a baseline LLM on an assistant task for the target task, where the former should own richer data resources and share structural or semantic similarity with the latter. In practice, T3 is approached to deal with the long text summarization task by utilizing question answering as the assistant task, and further validated its effectiveness on the BBC summary, NarraSum, FairytaleQA, and NLQuAD datasets, with up to nearly 14% improvement in ROUGE, 35% improvement in BLEU, and 16% improvement in Factscore compared to three baseline LLMs, demonstrating its potential for more assistant-target task combinations.