 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccurate and Fast reconstruction of Porous Media from Extremely Limited Information Using Conditional Generative Adversarial Network
Apr 04, 2019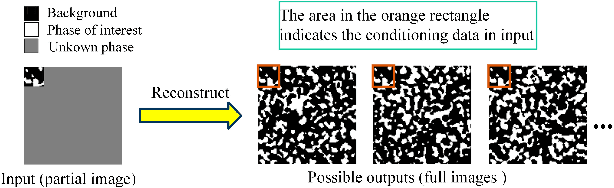
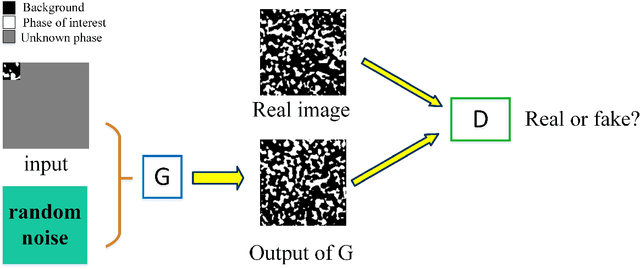
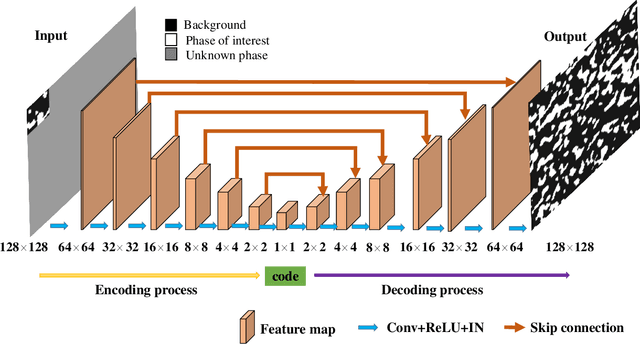
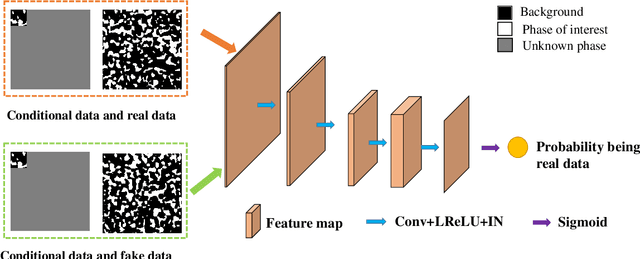
Porous media are ubiquitous in both nature and engineering applications, thus their modelling and understanding is of vital importance. In contrast to direct acquisition of three-dimensional (3D) images of such medium, obtaining its sub-region (s) like two-dimensional (2D) images or several small areas could be much feasible. Therefore, reconstructing whole images from the limited information is a primary technique in such cases. Specially, in practice the given data cannot generally be determined by users and may be incomplete or partially informed, thus making existing reconstruction methods inaccurate or even ineffective. To overcome this shortcoming, in this study we proposed a deep learning-based framework for reconstructing full image from its much smaller sub-area(s). Particularly, conditional generative adversarial network (CGAN) is utilized to learn the mapping between input (partial image) and output (full image). To preserve the reconstruction accuracy, two simple but effective objective functions are proposed and then coupled with the other two functions to jointly constrain the training procedure. Due to the inherent essence of this ill-posed problem, a Gaussian noise is introduced for producing reconstruction diversity, thus allowing for providing multiple candidate outputs. Extensively tested on a variety of porous materials and demonstrated by both visual inspection and quantitative comparison, the method is shown to be accurate, stable yet fast ($\sim0.08s$ for a $128 \times 128$ image reconstruction). We highlight that the proposed approach can be readily extended, such as incorporating any user-define conditional data and an arbitrary number of object functions into reconstruction, and being coupled with other reconstruction methods.
CT-image Super Resolution Using 3D Convolutional Neural Network
Jun 24, 2018

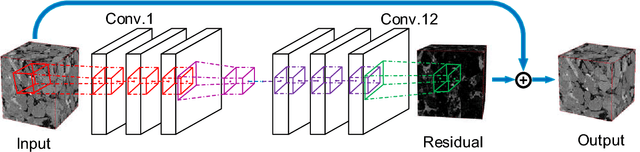
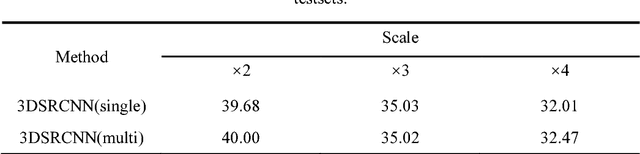
Computed Tomography (CT) imaging technique is widely used in geological exploration, medical diagnosis and other fields. In practice, however, the resolution of CT image is usually limited by scanning devices and great expense. Super resolution (SR) methods based on deep learning have achieved surprising performance in two-dimensional (2D) images. Unfortunately, there are few effective SR algorithms for three-dimensional (3D) images. In this paper, we proposed a novel network named as three-dimensional super resolution convolutional neural network (3DSRCNN) to realize voxel super resolution for CT images. To solve the practical problems in training process such as slow convergence of network training, insufficient memory, etc., we utilized adjustable learning rate, residual-learning, gradient clipping, momentum stochastic gradient descent (SGD) strategies to optimize training procedure. In addition, we have explored the empirical guidelines to set appropriate number of layers of network and how to use residual learning strategy. Additionally, previous learning-based algorithms need to separately train for different scale factors for reconstruction, yet our single model can complete the multi-scale SR. At last, our method has better performance in terms of PSNR, SSIM and efficiency compared with conventional methods.