Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCaveats in Generating Medical Imaging Labels from Radiology Reports
May 06, 2019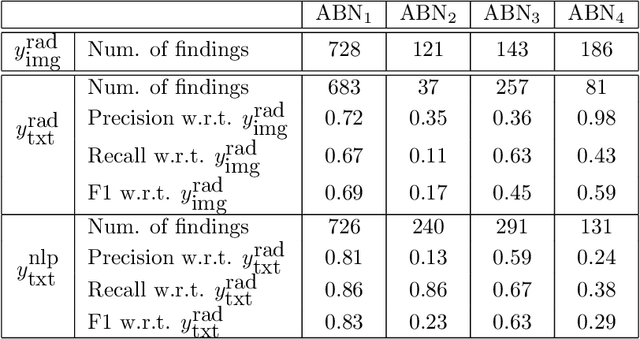
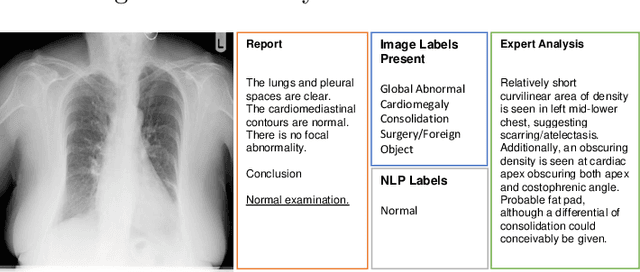
Acquiring high-quality annotations in medical imaging is usually a costly process. Automatic label extraction with natural language processing (NLP) has emerged as a promising workaround to bypass the need of expert annotation. Despite the convenience, the limitation of such an approximation has not been carefully examined and is not well understood. With a challenging set of 1,000 chest X-ray studies and their corresponding radiology reports, we show that there exists a surprisingly large discrepancy between what radiologists visually perceive and what they clinically report. Furthermore, with inherently flawed report as ground truth, the state-of-the-art medical NLP fails to produce high-fidelity labels.
* Accepted workshop contribution for Medical Imaging with Deep Learning
(MIDL), 2019
Via