 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequence-Augmented SE(3)-Flow Matching For Conditional Protein Backbone Generation
May 30, 2024Proteins are essential for almost all biological processes and derive their diverse functions from complex 3D structures, which are in turn determined by their amino acid sequences. In this paper, we exploit the rich biological inductive bias of amino acid sequences and introduce FoldFlow-2, a novel sequence-conditioned SE(3)-equivariant flow matching model for protein structure generation. FoldFlow-2 presents substantial new architectural features over the previous FoldFlow family of models including a protein large language model to encode sequence, a new multi-modal fusion trunk that combines structure and sequence representations, and a geometric transformer based decoder. To increase diversity and novelty of generated samples -- crucial for de-novo drug design -- we train FoldFlow-2 at scale on a new dataset that is an order of magnitude larger than PDB datasets of prior works, containing both known proteins in PDB and high-quality synthetic structures achieved through filtering. We further demonstrate the ability to align FoldFlow-2 to arbitrary rewards, e.g. increasing secondary structures diversity, by introducing a Reinforced Finetuning (ReFT) objective. We empirically observe that FoldFlow-2 outperforms previous state-of-the-art protein structure-based generative models, improving over RFDiffusion in terms of unconditional generation across all metrics including designability, diversity, and novelty across all protein lengths, as well as exhibiting generalization on the task of equilibrium conformation sampling. Finally, we demonstrate that a fine-tuned FoldFlow-2 makes progress on challenging conditional design tasks such as designing scaffolds for the VHH nanobody.
Long-Time Convergence and Propagation of Chaos for Nonlinear MCMC
Feb 11, 2022
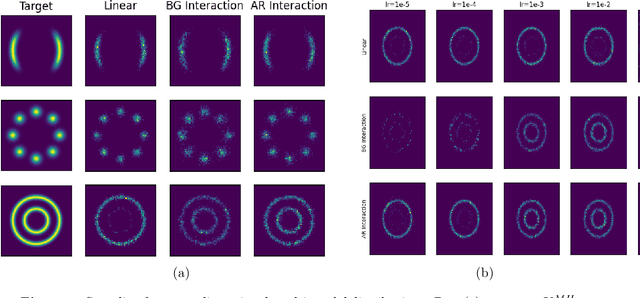

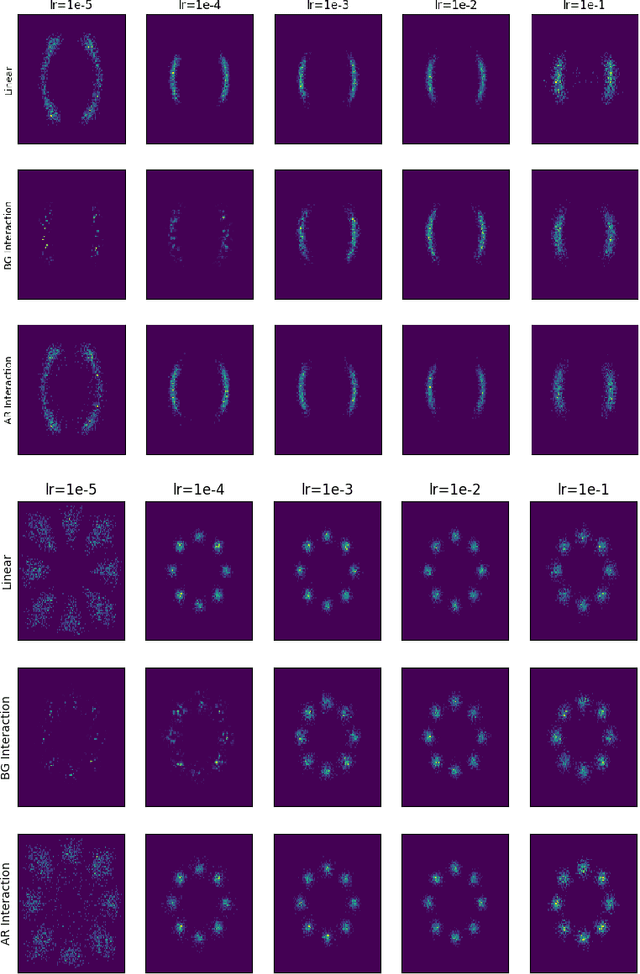
In this paper, we study the long-time convergence and uniform strong propagation of chaos for a class of nonlinear Markov chains for Markov chain Monte Carlo (MCMC). Our technique is quite simple, making use of recent contraction estimates for linear Markov kernels and basic techniques from Markov theory and analysis. Moreover, the same proof strategy applies to both the long-time convergence and propagation of chaos. We also show, via some experiments, that these nonlinear MCMC techniques are viable for use in real-world high-dimensional inference such as Bayesian neural networks.
On the Regularity of Attention
Feb 10, 2021Attention is a powerful component of modern neural networks across a wide variety of domains. In this paper, we seek to quantify the regularity (i.e. the amount of smoothness) of the attention operation. To accomplish this goal, we propose a new mathematical framework that uses measure theory and integral operators to model attention. We show that this framework is consistent with the usual definition, and that it captures the essential properties of attention. Then we use this framework to prove that, on compact domains, the attention operation is Lipschitz continuous and provide an estimate of its Lipschitz constant. Additionally, by focusing on a specific type of attention, we extend these Lipschitz continuity results to non-compact domains. We also discuss the effects regularity can have on NLP models, and applications to invertible and infinitely-deep networks.
A Mathematical Theory of Attention
Jul 06, 2020Attention is a powerful component of modern neural networks across a wide variety of domains. However, despite its ubiquity in machine learning, there is a gap in our understanding of attention from a theoretical point of view. We propose a framework to fill this gap by building a mathematically equivalent model of attention using measure theory. With this model, we are able to interpret self-attention as a system of self-interacting particles, we shed light on self-attention from a maximum entropy perspective, and we show that attention is actually Lipschitz-continuous (with an appropriate metric) under suitable assumptions. We then apply these insights to the problem of mis-specified input data; infinitely-deep, weight-sharing self-attention networks; and more general Lipschitz estimates for a specific type of attention studied in concurrent work.
Kalman Gradient Descent: Adaptive Variance Reduction in Stochastic Optimization
Oct 29, 2018
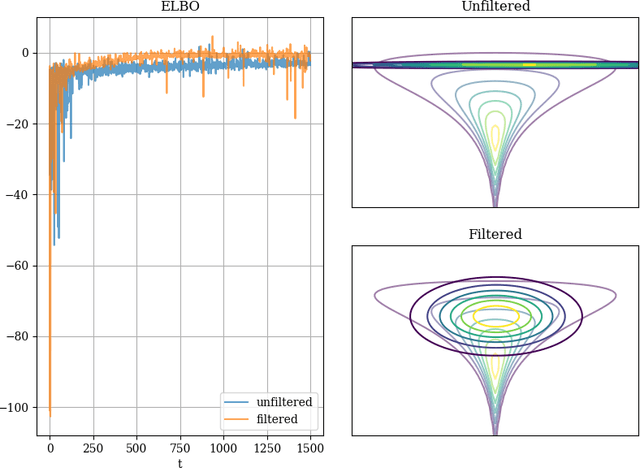
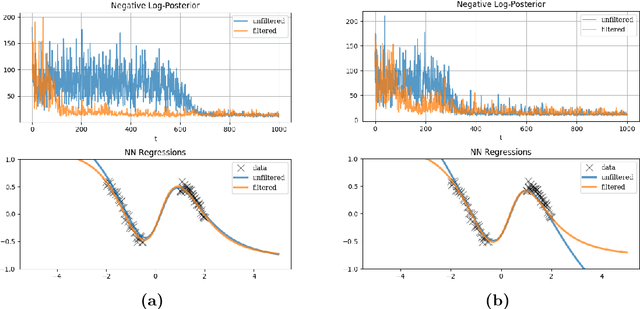
We introduce Kalman Gradient Descent, a stochastic optimization algorithm that uses Kalman filtering to adaptively reduce gradient variance in stochastic gradient descent by filtering the gradient estimates. We present both a theoretical analysis of convergence in a non-convex setting and experimental results which demonstrate improved performance on a variety of machine learning areas including neural networks and black box variational inference. We also present a distributed version of our algorithm that enables large-dimensional optimization, and we extend our algorithm to SGD with momentum and RMSProp.