 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUSPR: Learning a Unified Solver for Profiled Routing
May 08, 2025The Profiled Vehicle Routing Problem (PVRP) extends the classical VRP by incorporating vehicle-client-specific preferences and constraints, reflecting real-world requirements such as zone restrictions and service-level preferences. While recent reinforcement learning (RL) solvers have shown promise, they require retraining for each new profile distribution, suffer from poor representation ability, and struggle to generalize to out-of-distribution instances. In this paper, we address these limitations by introducing USPR (Unified Solver for Profiled Routing), a novel framework that natively handles arbitrary profile types. USPR introduces three key innovations: (i) Profile Embeddings (PE) to encode any combination of profile types; (ii) Multi-Head Profiled Attention (MHPA), an attention mechanism that models rich interactions between vehicles and clients; (iii) Profile-aware Score Reshaping (PSR), which dynamically adjusts decoder logits using profile scores to improve generalization. Empirical results on diverse PVRP benchmarks demonstrate that USPR achieves state-of-the-art results among learning-based methods while offering significant gains in flexibility and computational efficiency. We make our source code publicly available to foster future research at https://github.com/ai4co/uspr.
Neural Combinatorial Optimization for Real-World Routing
Mar 20, 2025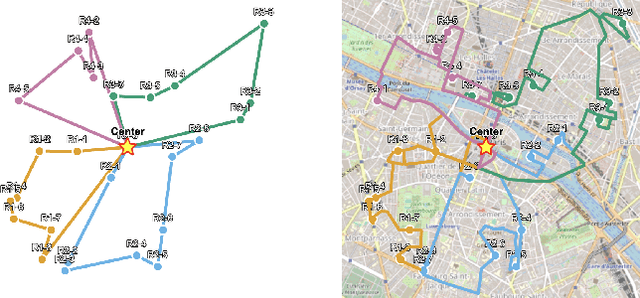



Vehicle Routing Problems (VRPs) are a class of NP-hard problems ubiquitous in several real-world logistics scenarios that pose significant challenges for optimization. Neural Combinatorial Optimization (NCO) has emerged as a promising alternative to classical approaches, as it can learn fast heuristics to solve VRPs. However, most research works in NCO for VRPs focus on simplified settings, which do not account for asymmetric distances and travel durations that cannot be derived by simple Euclidean distances and unrealistic data distributions, hindering real-world deployment. This work introduces RRNCO (Real Routing NCO) to bridge the gap of NCO between synthetic and real-world VRPs in the critical aspects of both data and modeling. First, we introduce a new, openly available dataset with real-world data containing a diverse dataset of locations, distances, and duration matrices from 100 cities, considering realistic settings with actual routing distances and durations obtained from Open Source Routing Machine (OSRM). Second, we propose a novel approach that efficiently processes both node and edge features through contextual gating, enabling the construction of more informed node embedding, and we finally incorporate an Adaptation Attention Free Module (AAFM) with neural adaptive bias mechanisms that effectively integrates not only distance matrices but also angular relationships between nodes, allowing our model to capture rich structural information. RRNCO achieves state-of-the-art results in real-world VRPs among NCO methods. We make our dataset and code publicly available at https://github.com/ai4co/real-routing-nco.
CAMP: Collaborative Attention Model with Profiles for Vehicle Routing Problems
Jan 06, 2025The profiled vehicle routing problem (PVRP) is a generalization of the heterogeneous capacitated vehicle routing problem (HCVRP) in which the objective is to optimize the routes of vehicles to serve client demands subject to different vehicle profiles, with each having a preference or constraint on a per-client basis. While existing learning methods have shown promise for solving the HCVRP in real-time, no learning method exists to solve the more practical and challenging PVRP. In this paper, we propose a Collaborative Attention Model with Profiles (CAMP), a novel approach that learns efficient solvers for PVRP using multi-agent reinforcement learning. CAMP employs a specialized attention-based encoder architecture to embed profiled client embeddings in parallel for each vehicle profile. We design a communication layer between agents for collaborative decision-making across profiled embeddings at each decoding step and a batched pointer mechanism to attend to the profiled embeddings to evaluate the likelihood of the next actions. We evaluate CAMP on two variants of PVRPs: PVRP with preferences, which explicitly influence the reward function, and PVRP with zone constraints with different numbers of agents and clients, demonstrating that our learned solvers achieve competitive results compared to both classical state-of-the-art neural multi-agent models in terms of solution quality and computational efficiency. We make our code openly available at https://github.com/ai4co/camp.
PARCO: Learning Parallel Autoregressive Policies for Efficient Multi-Agent Combinatorial Optimization
Sep 05, 2024



Multi-agent combinatorial optimization problems such as routing and scheduling have great practical relevance but present challenges due to their NP-hard combinatorial nature, hard constraints on the number of possible agents, and hard-to-optimize objective functions. This paper introduces PARCO (Parallel AutoRegressive Combinatorial Optimization), a novel approach that learns fast surrogate solvers for multi-agent combinatorial problems with reinforcement learning by employing parallel autoregressive decoding. We propose a model with a Multiple Pointer Mechanism to efficiently decode multiple decisions simultaneously by different agents, enhanced by a Priority-based Conflict Handling scheme. Moreover, we design specialized Communication Layers that enable effective agent collaboration, thus enriching decision-making. We evaluate PARCO in representative multi-agent combinatorial problems in routing and scheduling and demonstrate that our learned solvers offer competitive results against both classical and neural baselines in terms of both solution quality and speed. We make our code openly available at https://github.com/ai4co/parco.
Ant Colony Sampling with GFlowNets for Combinatorial Optimization
Mar 11, 2024



This paper introduces the Generative Flow Ant Colony Sampler (GFACS), a novel neural-guided meta-heuristic algorithm for combinatorial optimization. GFACS integrates generative flow networks (GFlowNets) with the ant colony optimization (ACO) methodology. GFlowNets, a generative model that learns a constructive policy in combinatorial spaces, enhance ACO by providing an informed prior distribution of decision variables conditioned on input graph instances. Furthermore, we introduce a novel combination of training tricks, including search-guided local exploration, energy normalization, and energy shaping to improve GFACS. Our experimental results demonstrate that GFACS outperforms baseline ACO algorithms in seven CO tasks and is competitive with problem-specific heuristics for vehicle routing problems. The source code is available at \url{https://github.com/ai4co/gfacs}.
RL4CO: an Extensive Reinforcement Learning for Combinatorial Optimization Benchmark
Jun 29, 2023
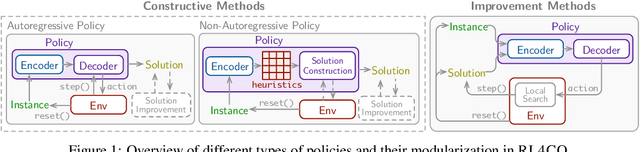

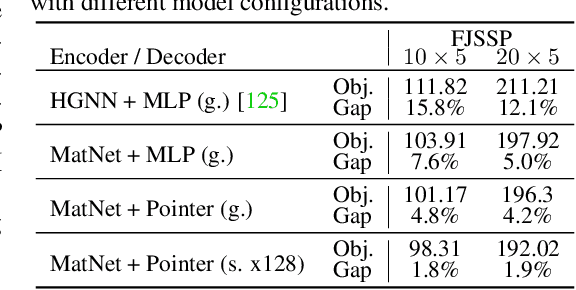
We introduce RL4CO, an extensive reinforcement learning (RL) for combinatorial optimization (CO) benchmark. RL4CO employs state-of-the-art software libraries as well as best practices in implementation, such as modularity and configuration management, to be efficient and easily modifiable by researchers for adaptations of neural network architecture, environments, and algorithms. Contrary to the existing focus on specific tasks like the traveling salesman problem (TSP) for performance assessment, we underline the importance of scalability and generalization capabilities for diverse optimization tasks. We also systematically benchmark sample efficiency, zero-shot generalization, and adaptability to changes in data distributions of various models. Our experiments show that some recent state-of-the-art methods fall behind their predecessors when evaluated using these new metrics, suggesting the necessity for a more balanced view of the performance of neural CO solvers. We hope RL4CO will encourage the exploration of novel solutions to complex real-world tasks, allowing to compare with existing methods through a standardized interface that decouples the science from the software engineering. We make our library publicly available at https://github.com/kaist-silab/rl4co.
Meta-SAGE: Scale Meta-Learning Scheduled Adaptation with Guided Exploration for Mitigating Scale Shift on Combinatorial Optimization
Jun 07, 2023This paper proposes Meta-SAGE, a novel approach for improving the scalability of deep reinforcement learning models for combinatorial optimization (CO) tasks. Our method adapts pre-trained models to larger-scale problems in test time by suggesting two components: a scale meta-learner (SML) and scheduled adaptation with guided exploration (SAGE). First, SML transforms the context embedding for subsequent adaptation of SAGE based on scale information. Then, SAGE adjusts the model parameters dedicated to the context embedding for a specific instance. SAGE introduces locality bias, which encourages selecting nearby locations to determine the next location. The locality bias gradually decays as the model is adapted to the target instance. Results show that Meta-SAGE outperforms previous adaptation methods and significantly improves scalability in representative CO tasks. Our source code is available at https://github.com/kaist-silab/meta-sage
Solving NP-hard Min-max Routing Problems as Sequential Generation with Equity Context
Jun 07, 2023



Min-max routing problems aim to minimize the maximum tour length among agents as they collaboratively visit all cities, i.e., the completion time. These problems include impactful real-world applications but are known as NP-hard. Existing methods are facing challenges, particularly in large-scale problems that require the coordination of numerous agents to cover thousands of cities. This paper proposes a new deep-learning framework to solve large-scale min-max routing problems. We model the simultaneous decision-making of multiple agents as a sequential generation process, allowing the utilization of scalable deep-learning models for sequential decision-making. In the sequentially approximated problem, we propose a scalable contextual Transformer model, Equity-Transformer, which generates sequential actions considering an equitable workload among other agents. The effectiveness of Equity-Transformer is demonstrated through its superior performance in two representative min-max routing tasks: the min-max multiple traveling salesman problem (min-max mTSP) and the min-max multiple pick-up and delivery problem (min-max mPDP). Notably, our method achieves significant reductions of runtime, approximately 335 times, and cost values of about 53% compared to a competitive heuristic (LKH3) in the case of 100 vehicles with 1,000 cities of mTSP. We provide reproducible source code: https://github.com/kaist-silab/equity-transformer