 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEasy to Learn, Yet Hard to Forget: Towards Robust Unlearning Under Bias
Feb 25, 2026Machine unlearning, which enables a model to forget specific data, is crucial for ensuring data privacy and model reliability. However, its effectiveness can be severely undermined in real-world scenarios where models learn unintended biases from spurious correlations within the data. This paper investigates the unique challenges of unlearning from such biased models. We identify a novel phenomenon we term ``shortcut unlearning," where models exhibit an ``easy to learn, yet hard to forget" tendency. Specifically, models struggle to forget easily-learned, bias-aligned samples; instead of forgetting the class attribute, they unlearn the bias attribute, which can paradoxically improve accuracy on the class intended to be forgotten. To address this, we propose CUPID, a new unlearning framework inspired by the observation that samples with different biases exhibit distinct loss landscape sharpness. Our method first partitions the forget set into causal- and bias-approximated subsets based on sample sharpness, then disentangles model parameters into causal and bias pathways, and finally performs a targeted update by routing refined causal and bias gradients to their respective pathways. Extensive experiments on biased datasets including Waterbirds, BAR, and Biased NICO++ demonstrate that our method achieves state-of-the-art forgetting performance and effectively mitigates the shortcut unlearning problem.
Position on LLM-Assisted Peer Review: Addressing Reviewer Gap through Mentoring and Feedback
Jan 14, 2026The rapid expansion of AI research has intensified the Reviewer Gap, threatening the peer-review sustainability and perpetuating a cycle of low-quality evaluations. This position paper critiques existing LLM approaches that automatically generate reviews and argues for a paradigm shift that positions LLMs as tools for assisting and educating human reviewers. We define the core principles of high-quality peer review and propose two complementary systems grounded in these foundations: (i) an LLM-assisted mentoring system that cultivates reviewers' long-term competencies, and (ii) an LLM-assisted feedback system that helps reviewers refine the quality of their reviews. This human-centered approach aims to strengthen reviewer expertise and contribute to building a more sustainable scholarly ecosystem.
SUMMPILOT: Bridging Efficiency and Customization for Interactive Summarization System
Jan 13, 2026This paper incorporates the efficiency of automatic summarization and addresses the challenge of generating personalized summaries tailored to individual users' interests and requirements. To tackle this challenge, we introduce SummPilot, an interaction-based customizable summarization system. SummPilot leverages a large language model to facilitate both automatic and interactive summarization. Users can engage with the system to understand document content and personalize summaries through interactive components such as semantic graphs, entity clustering, and explainable evaluation. Our demo and user studies demonstrate SummPilot's adaptability and usefulness for customizable summarization.
Beyond Single-User Dialogue: Assessing Multi-User Dialogue State Tracking Capabilities of Large Language Models
Jun 12, 2025Large language models (LLMs) have demonstrated remarkable performance in zero-shot dialogue state tracking (DST), reducing the need for task-specific training. However, conventional DST benchmarks primarily focus on structured user-agent conversations, failing to capture the complexities of real-world multi-user interactions. In this study, we assess the robustness of LLMs in multi-user DST while minimizing dataset construction costs. Inspired by recent advances in LLM-based data annotation, we extend an existing DST dataset by generating utterances of a second user based on speech act theory. Our methodology systematically incorporates a second user's utterances into conversations, enabling a controlled evaluation of LLMs in multi-user settings. Experimental results reveal a significant performance drop compared to single-user DST, highlighting the limitations of current LLMs in extracting and tracking dialogue states amidst multiple speakers. Our findings emphasize the need for future research to enhance LLMs for multi-user DST scenarios, paving the way for more realistic and robust DST models.
Plug-in and Fine-tuning: Bridging the Gap between Small Language Models and Large Language Models
Jun 09, 2025Large language models (LLMs) are renowned for their extensive linguistic knowledge and strong generalization capabilities, but their high computational demands make them unsuitable for resource-constrained environments. In contrast, small language models (SLMs) are computationally efficient but often lack the broad generalization capacity of LLMs. To bridge this gap, we propose PiFi, a novel framework that combines the strengths of both LLMs and SLMs to achieve high performance while maintaining efficiency. PiFi integrates a single frozen layer from an LLM into a SLM and fine-tunes the combined model for specific tasks, boosting performance without a significant increase in computational cost. We show that PiFi delivers consistent performance improvements across a range of natural language processing tasks, including both natural language understanding and generation. Moreover, our findings demonstrate PiFi's ability to effectively leverage LLM knowledge, enhancing generalization to unseen domains and facilitating the transfer of linguistic abilities.
Proceedings of 1st Workshop on Advancing Artificial Intelligence through Theory of Mind
Apr 28, 2025



This volume includes a selection of papers presented at the Workshop on Advancing Artificial Intelligence through Theory of Mind held at AAAI 2025 in Philadelphia US on 3rd March 2025. The purpose of this volume is to provide an open access and curated anthology for the ToM and AI research community.
See-Saw Modality Balance: See Gradient, and Sew Impaired Vision-Language Balance to Mitigate Dominant Modality Bias
Mar 18, 2025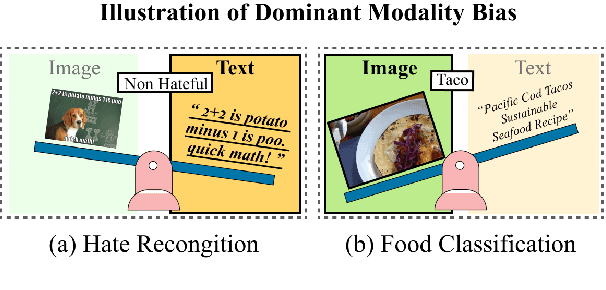
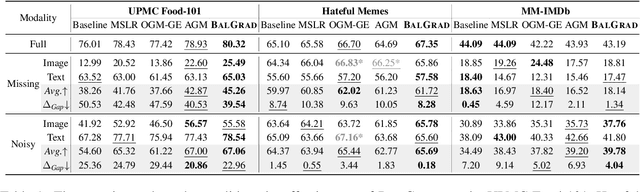
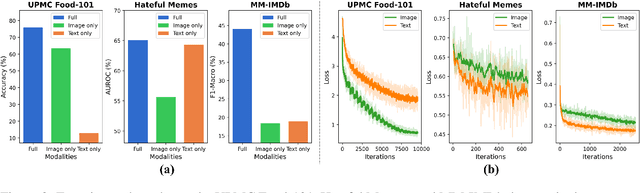
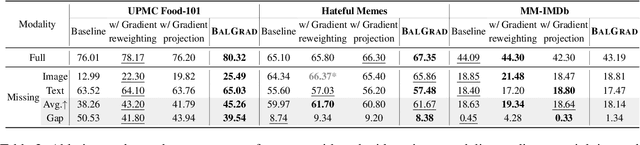
Vision-language (VL) models have demonstrated strong performance across various tasks. However, these models often rely on a specific modality for predictions, leading to "dominant modality bias.'' This bias significantly hurts performance, especially when one modality is impaired. In this study, we analyze model behavior under dominant modality bias and theoretically show that unaligned gradients or differences in gradient magnitudes prevent balanced convergence of the loss. Based on these findings, we propose a novel framework, BalGrad to mitigate dominant modality bias. Our approach includes inter-modality gradient reweighting, adjusting the gradient of KL divergence based on each modality's contribution, and inter-task gradient projection to align task directions in a non-conflicting manner. Experiments on UPMC Food-101, Hateful Memes, and MM-IMDb datasets confirm that BalGrad effectively alleviates over-reliance on specific modalities when making predictions.
Questioning Internal Knowledge Structure of Large Language Models Through the Lens of the Olympic Games
Sep 10, 2024Large language models (LLMs) have become a dominant approach in natural language processing, yet their internal knowledge structures remain largely unexplored. In this paper, we analyze the internal knowledge structures of LLMs using historical medal tallies from the Olympic Games. We task the models with providing the medal counts for each team and identifying which teams achieved specific rankings. Our results reveal that while state-of-the-art LLMs perform remarkably well in reporting medal counts for individual teams, they struggle significantly with questions about specific rankings. This suggests that the internal knowledge structures of LLMs are fundamentally different from those of humans, who can easily infer rankings from known medal counts. To support further research, we publicly release our code, dataset, and model outputs.
VolDoGer: LLM-assisted Datasets for Domain Generalization in Vision-Language Tasks
Jul 29, 2024



Domain generalizability is a crucial aspect of a deep learning model since it determines the capability of the model to perform well on data from unseen domains. However, research on the domain generalizability of deep learning models for vision-language tasks remains limited, primarily because of the lack of required datasets. To address these challenges, we propose VolDoGer: Vision-Language Dataset for Domain Generalization, a dedicated dataset designed for domain generalization that addresses three vision-language tasks: image captioning, visual question answering, and visual entailment. We constructed VolDoGer by extending LLM-based data annotation techniques to vision-language tasks, thereby alleviating the burden of recruiting human annotators. We evaluated the domain generalizability of various models, ranging from fine-tuned models to a recent multimodal large language model, through VolDoGer.
Learning to Detour: Shortcut Mitigating Augmentation for Weakly Supervised Semantic Segmentation
May 28, 2024Weakly supervised semantic segmentation (WSSS) employing weak forms of labels has been actively studied to alleviate the annotation cost of acquiring pixel-level labels. However, classifiers trained on biased datasets tend to exploit shortcut features and make predictions based on spurious correlations between certain backgrounds and objects, leading to a poor generalization performance. In this paper, we propose shortcut mitigating augmentation (SMA) for WSSS, which generates synthetic representations of object-background combinations not seen in the training data to reduce the use of shortcut features. Our approach disentangles the object-relevant and background features. We then shuffle and combine the disentangled representations to create synthetic features of diverse object-background combinations. SMA-trained classifier depends less on contexts and focuses more on the target object when making predictions. In addition, we analyzed the behavior of the classifier on shortcut usage after applying our augmentation using an attribution method-based metric. The proposed method achieved the improved performance of semantic segmentation result on PASCAL VOC 2012 and MS COCO 2014 datasets.