 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSteering LLMs toward Korean Local Speech: Iterative Refinement Framework for Faithful Dialect Translation
Nov 10, 2025Standard-to-dialect machine translation remains challenging due to a persistent dialect gap in large language models and evaluation distortions inherent in n-gram metrics, which favor source copying over authentic dialect translation. In this paper, we propose the dialect refinement (DIA-REFINE) framework, which guides LLMs toward faithful target dialect outputs through an iterative loop of translation, verification, and feedback using external dialect classifiers. To address the limitations of n-gram-based metrics, we introduce the dialect fidelity score (DFS) to quantify linguistic shift and the target dialect ratio (TDR) to measure the success of dialect translation. Experiments on Korean dialects across zero-shot and in-context learning baselines demonstrate that DIA-REFINE consistently enhances dialect fidelity. The proposed metrics distinguish between False Success cases, where high n-gram scores obscure failures in dialectal translation, and True Attempt cases, where genuine attempts at dialectal translation yield low n-gram scores. We also observed that models exhibit varying degrees of responsiveness to the framework, and that integrating in-context examples further improves the translation of dialectal expressions. Our work establishes a robust framework for goal-directed, inclusive dialect translation, providing both rigorous evaluation and critical insights into model performance.
From Ground Trust to Truth: Disparities in Offensive Language Judgments on Contemporary Korean Political Discourse
Sep 18, 2025Although offensive language continually evolves over time, even recent studies using LLMs have predominantly relied on outdated datasets and rarely evaluated the generalization ability on unseen texts. In this study, we constructed a large-scale dataset of contemporary political discourse and employed three refined judgments in the absence of ground truth. Each judgment reflects a representative offensive language detection method and is carefully designed for optimal conditions. We identified distinct patterns for each judgment and demonstrated tendencies of label agreement using a leave-one-out strategy. By establishing pseudo-labels as ground trust for quantitative performance assessment, we observed that a strategically designed single prompting achieves comparable performance to more resource-intensive methods. This suggests a feasible approach applicable in real-world settings with inherent constraints.
Delving into Multilingual Ethical Bias: The MSQAD with Statistical Hypothesis Tests for Large Language Models
May 25, 2025Despite the recent strides in large language models, studies have underscored the existence of social biases within these systems. In this paper, we delve into the validation and comparison of the ethical biases of LLMs concerning globally discussed and potentially sensitive topics, hypothesizing that these biases may arise from language-specific distinctions. Introducing the Multilingual Sensitive Questions & Answers Dataset (MSQAD), we collected news articles from Human Rights Watch covering 17 topics, and generated socially sensitive questions along with corresponding responses in multiple languages. We scrutinized the biases of these responses across languages and topics, employing two statistical hypothesis tests. The results showed that the null hypotheses were rejected in most cases, indicating biases arising from cross-language differences. It demonstrates that ethical biases in responses are widespread across various languages, and notably, these biases were prevalent even among different LLMs. By making the proposed MSQAD openly available, we aim to facilitate future research endeavors focused on examining cross-language biases in LLMs and their variant models.
VolDoGer: LLM-assisted Datasets for Domain Generalization in Vision-Language Tasks
Jul 29, 2024



Domain generalizability is a crucial aspect of a deep learning model since it determines the capability of the model to perform well on data from unseen domains. However, research on the domain generalizability of deep learning models for vision-language tasks remains limited, primarily because of the lack of required datasets. To address these challenges, we propose VolDoGer: Vision-Language Dataset for Domain Generalization, a dedicated dataset designed for domain generalization that addresses three vision-language tasks: image captioning, visual question answering, and visual entailment. We constructed VolDoGer by extending LLM-based data annotation techniques to vision-language tasks, thereby alleviating the burden of recruiting human annotators. We evaluated the domain generalizability of various models, ranging from fine-tuned models to a recent multimodal large language model, through VolDoGer.
UniGen: Universal Domain Generalization for Sentiment Classification via Zero-shot Dataset Generation
May 02, 2024Although pre-trained language models have exhibited great flexibility and versatility with prompt-based few-shot learning, they suffer from the extensive parameter size and limited applicability for inference. Recent studies have suggested that PLMs be used as dataset generators and a tiny task-specific model be trained to achieve efficient inference. However, their applicability to various domains is limited because they tend to generate domain-specific datasets. In this work, we propose a novel approach to universal domain generalization that generates a dataset regardless of the target domain. This allows for generalization of the tiny task model to any domain that shares the label space, thus enhancing the real-world applicability of the dataset generation paradigm. Our experiments indicate that the proposed method accomplishes generalizability across various domains while using a parameter set that is orders of magnitude smaller than PLMs.
Don't be a Fool: Pooling Strategies in Offensive Language Detection from User-Intended Adversarial Attacks
Mar 20, 2024


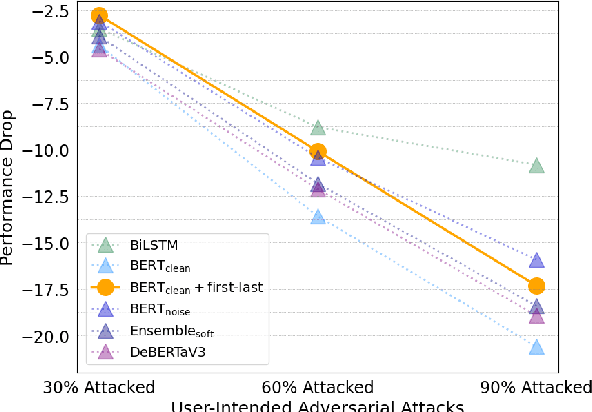
Offensive language detection is an important task for filtering out abusive expressions and improving online user experiences. However, malicious users often attempt to avoid filtering systems through the involvement of textual noises. In this paper, we propose these evasions as user-intended adversarial attacks that insert special symbols or leverage the distinctive features of the Korean language. Furthermore, we introduce simple yet effective pooling strategies in a layer-wise manner to defend against the proposed attacks, focusing on the preceding layers not just the last layer to capture both offensiveness and token embeddings. We demonstrate that these pooling strategies are more robust to performance degradation even when the attack rate is increased, without directly training of such patterns. Notably, we found that models pre-trained on clean texts could achieve a comparable performance in detecting attacked offensive language, to models pre-trained on noisy texts by employing these pooling strategies.