 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBefore Forgetting, Learn to Remember: Revisiting Foundational Learning Failures in LVLM Unlearning Benchmarks
May 05, 2026While Large Vision-Language Models (LVLMs) offer powerful capabilities, they pose privacy risks by unintentionally memorizing sensitive personal information. Current unlearning benchmarks attempt to mitigate this using fictitious identities but overlook a critical stage 1 failure: models fail to effectively memorize target information initially, rendering subsequent unlearning evaluations unreliable. Diagnosing under-memorization and the multi-hop curse as root causes, we introduce ReMem, a Reliable Multi-hop and Multi-image Memorization Benchmark. ReMem ensures robust foundational learning through principled data scaling, reasoning-aware QA pairs, and diverse visual contexts. Additionally, we propose a novel Exposure metric to quantify the depth of information erasure from the model's internal probability distribution. Extensive experiments demonstrate that ReMem provides a rigorous and trustworthy framework for diagnosing both learning and unlearning behaviors in LVLMs.
Erase Persona, Forget Lore: Benchmarking Multimodal Copyright Unlearning in Large Vision Language Models
May 05, 2026Large Vision-Language Models (LVLMs), trained on web-scale data, risk memorizing and regenerating copyrighted visual content such as characters and logos, creating significant challenges. Machine unlearning offers a path to mitigate these risks by removing specific content post-training, but evaluating its effectiveness, especially in the complex multimodal setting of LVLMs, remains an open problem. Current evaluation methods often lack robustness or fail to capture the nuances of cross-modal concept erasure. To address this critical gap, we introduce the CoVUBench benchmark, the first framework specifically designed for evaluating copyright content unlearning in LVLMs. CoVUBench utilizes procedurally generated, legally safe synthetic data coupled with systematic visual variations spanning compositional changes and diverse domain manifestations to ensure realistic and robust evaluation of unlearning generalization. Our comprehensive multimodal evaluation protocol assesses both forgetting efficacy from the copyright holder perspective and the preservation of general model utility from the deployer viewpoint. By rigorously measuring this crucial trade-off, CoVUBench provides a standardized tool to advance the development of responsible and effective unlearning methods for LVLMs.
Aligning with Your Own Voice: Self-Corrected Preference Learning for Hallucination Mitigation in LVLMs
Apr 27, 2026Large Vision-Language Models (LVLMs) frequently suffer from hallucinations. Existing preference learning-based approaches largely rely on proprietary models to construct preference datasets. We identify that this reliance introduces a distributional mismatch between the proprietary and target models that hinders efficient alignment. To address this, we propose Alignment via VErified Self-correction DPO (AVES-DPO), a framework that aligns LVLMs using in-distribution data derived from the model's intrinsic knowledge. Our approach employs a consensus-based verification mechanism to diagnose diverse hallucinations and guides the model to self-correct, thereby generating preference pairs strictly compatible with its internal distribution. Extensive experiments demonstrate that AVES-DPO surpasses existing baselines in hallucination mitigation while requiring only 5.2k samples.
VG-CoT: Towards Trustworthy Visual Reasoning via Grounded Chain-of-Thought
Apr 23, 2026The advancement of Large Vision-Language Models (LVLMs) requires precise local region-based reasoning that faithfully grounds the model's logic in actual visual evidence. However, existing datasets face limitations in scalability due to extensive manual annotation and lack of explicit alignment between multi-step reasoning and corresponding image regions, which constrains the evaluation of model trustworthiness. To address these challenges, we propose the Visual Grounding Chain-of-Thought (VG-CoT) dataset, which explicitly links each reasoning step to real visual evidence within the image through a fully automated three-stage pipeline. The pipeline first extracts object- and text-level visual evidence using state-of-the-art detection and OCR models, then generates step-by-step grounded reasoning with GPT-4o, and finally refines the grounding through a rationale-driven open-set detection process. In addition, we introduce a new benchmark that comprehensively evaluates LVLMs reasoning across three complementary dimensions: Rationale Quality, Answer Accuracy, and Reasoning-Answer Alignment. Experiments with representative LVLMs, including LLaVA-1.5 and Qwen2-VL, demonstrate consistent improvements on most evaluation metrics, confirming that VG-CoT effectively enhances trustworthy, evidence-based reasoning while maintaining scalable and cost-efficient dataset construction. The dataset and code will be released publicly upon acceptance to facilitate further research.
Position on LLM-Assisted Peer Review: Addressing Reviewer Gap through Mentoring and Feedback
Jan 14, 2026The rapid expansion of AI research has intensified the Reviewer Gap, threatening the peer-review sustainability and perpetuating a cycle of low-quality evaluations. This position paper critiques existing LLM approaches that automatically generate reviews and argues for a paradigm shift that positions LLMs as tools for assisting and educating human reviewers. We define the core principles of high-quality peer review and propose two complementary systems grounded in these foundations: (i) an LLM-assisted mentoring system that cultivates reviewers' long-term competencies, and (ii) an LLM-assisted feedback system that helps reviewers refine the quality of their reviews. This human-centered approach aims to strengthen reviewer expertise and contribute to building a more sustainable scholarly ecosystem.
SUMMPILOT: Bridging Efficiency and Customization for Interactive Summarization System
Jan 13, 2026This paper incorporates the efficiency of automatic summarization and addresses the challenge of generating personalized summaries tailored to individual users' interests and requirements. To tackle this challenge, we introduce SummPilot, an interaction-based customizable summarization system. SummPilot leverages a large language model to facilitate both automatic and interactive summarization. Users can engage with the system to understand document content and personalize summaries through interactive components such as semantic graphs, entity clustering, and explainable evaluation. Our demo and user studies demonstrate SummPilot's adaptability and usefulness for customizable summarization.
Beyond Single-User Dialogue: Assessing Multi-User Dialogue State Tracking Capabilities of Large Language Models
Jun 12, 2025Large language models (LLMs) have demonstrated remarkable performance in zero-shot dialogue state tracking (DST), reducing the need for task-specific training. However, conventional DST benchmarks primarily focus on structured user-agent conversations, failing to capture the complexities of real-world multi-user interactions. In this study, we assess the robustness of LLMs in multi-user DST while minimizing dataset construction costs. Inspired by recent advances in LLM-based data annotation, we extend an existing DST dataset by generating utterances of a second user based on speech act theory. Our methodology systematically incorporates a second user's utterances into conversations, enabling a controlled evaluation of LLMs in multi-user settings. Experimental results reveal a significant performance drop compared to single-user DST, highlighting the limitations of current LLMs in extracting and tracking dialogue states amidst multiple speakers. Our findings emphasize the need for future research to enhance LLMs for multi-user DST scenarios, paving the way for more realistic and robust DST models.
VolDoGer: LLM-assisted Datasets for Domain Generalization in Vision-Language Tasks
Jul 29, 2024



Domain generalizability is a crucial aspect of a deep learning model since it determines the capability of the model to perform well on data from unseen domains. However, research on the domain generalizability of deep learning models for vision-language tasks remains limited, primarily because of the lack of required datasets. To address these challenges, we propose VolDoGer: Vision-Language Dataset for Domain Generalization, a dedicated dataset designed for domain generalization that addresses three vision-language tasks: image captioning, visual question answering, and visual entailment. We constructed VolDoGer by extending LLM-based data annotation techniques to vision-language tasks, thereby alleviating the burden of recruiting human annotators. We evaluated the domain generalizability of various models, ranging from fine-tuned models to a recent multimodal large language model, through VolDoGer.
UniGen: Universal Domain Generalization for Sentiment Classification via Zero-shot Dataset Generation
May 02, 2024
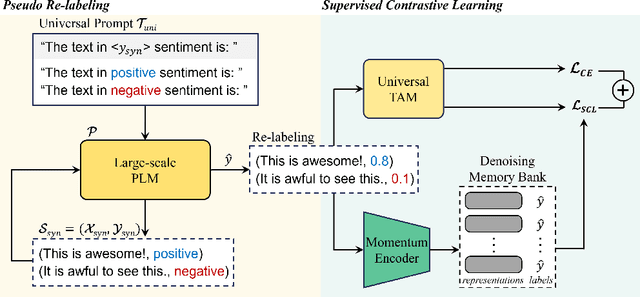
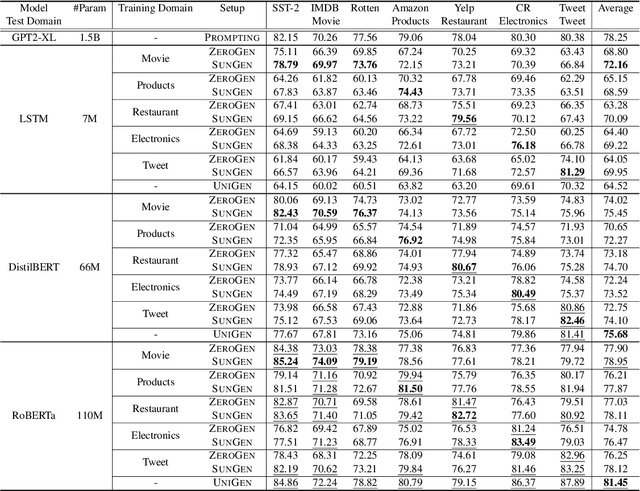
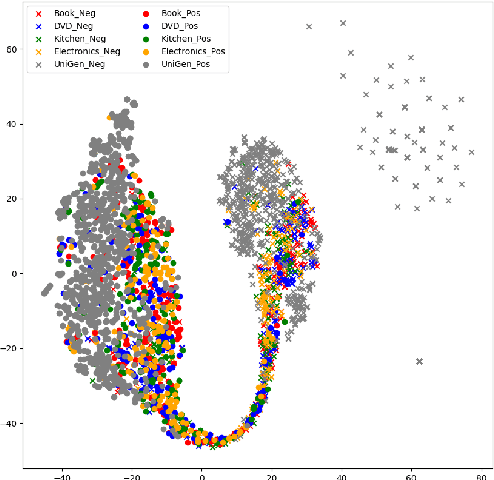
Although pre-trained language models have exhibited great flexibility and versatility with prompt-based few-shot learning, they suffer from the extensive parameter size and limited applicability for inference. Recent studies have suggested that PLMs be used as dataset generators and a tiny task-specific model be trained to achieve efficient inference. However, their applicability to various domains is limited because they tend to generate domain-specific datasets. In this work, we propose a novel approach to universal domain generalization that generates a dataset regardless of the target domain. This allows for generalization of the tiny task model to any domain that shares the label space, thus enhancing the real-world applicability of the dataset generation paradigm. Our experiments indicate that the proposed method accomplishes generalizability across various domains while using a parameter set that is orders of magnitude smaller than PLMs.