 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Single-User Dialogue: Assessing Multi-User Dialogue State Tracking Capabilities of Large Language Models
Jun 12, 2025Large language models (LLMs) have demonstrated remarkable performance in zero-shot dialogue state tracking (DST), reducing the need for task-specific training. However, conventional DST benchmarks primarily focus on structured user-agent conversations, failing to capture the complexities of real-world multi-user interactions. In this study, we assess the robustness of LLMs in multi-user DST while minimizing dataset construction costs. Inspired by recent advances in LLM-based data annotation, we extend an existing DST dataset by generating utterances of a second user based on speech act theory. Our methodology systematically incorporates a second user's utterances into conversations, enabling a controlled evaluation of LLMs in multi-user settings. Experimental results reveal a significant performance drop compared to single-user DST, highlighting the limitations of current LLMs in extracting and tracking dialogue states amidst multiple speakers. Our findings emphasize the need for future research to enhance LLMs for multi-user DST scenarios, paving the way for more realistic and robust DST models.
Enhancing Effectiveness and Robustness in a Low-Resource Regime via Decision-Boundary-aware Data Augmentation
Mar 22, 2024Efforts to leverage deep learning models in low-resource regimes have led to numerous augmentation studies. However, the direct application of methods such as mixup and cutout to text data, is limited due to their discrete characteristics. While methods using pretrained language models have exhibited efficiency, they require additional considerations for robustness. Inspired by recent studies on decision boundaries, this paper proposes a decision-boundary-aware data augmentation strategy to enhance robustness using pretrained language models. The proposed technique first focuses on shifting the latent features closer to the decision boundary, followed by reconstruction to generate an ambiguous version with a soft label. Additionally, mid-K sampling is suggested to enhance the diversity of the generated sentences. This paper demonstrates the performance of the proposed augmentation strategy compared to other methods through extensive experiments. Furthermore, the ablation study reveals the effect of soft labels and mid-K sampling and the extensibility of the method with curriculum data augmentation.
SoftEDA: Rethinking Rule-Based Data Augmentation with Soft Labels
Feb 08, 2024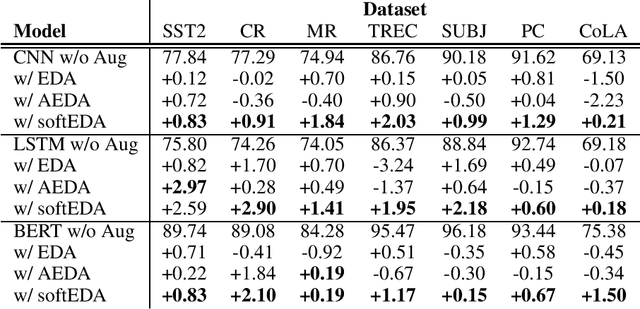
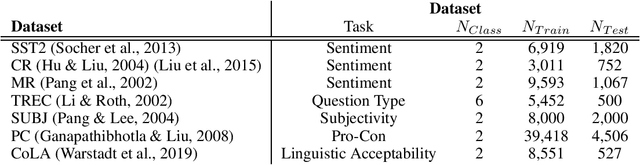
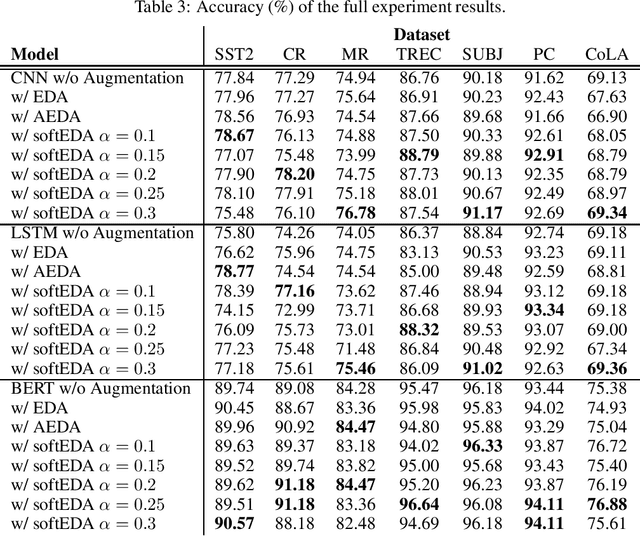
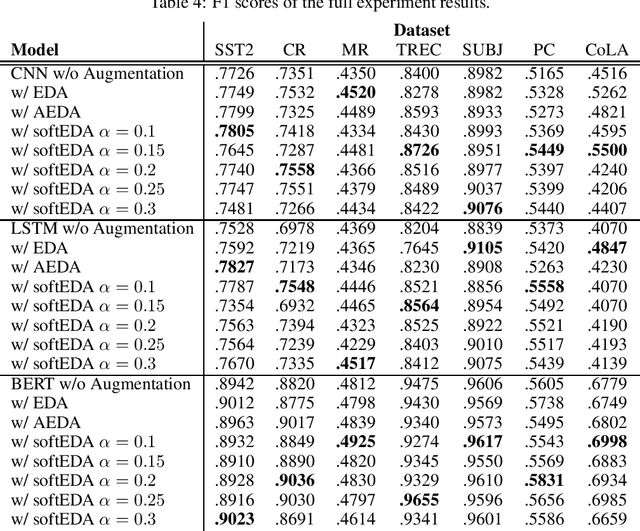
Rule-based text data augmentation is widely used for NLP tasks due to its simplicity. However, this method can potentially damage the original meaning of the text, ultimately hurting the performance of the model. To overcome this limitation, we propose a straightforward technique for applying soft labels to augmented data. We conducted experiments across seven different classification tasks and empirically demonstrated the effectiveness of our proposed approach. We have publicly opened our source code for reproducibility.
AutoAugment Is What You Need: Enhancing Rule-based Augmentation Methods in Low-resource Regimes
Feb 08, 2024


Text data augmentation is a complex problem due to the discrete nature of sentences. Although rule-based augmentation methods are widely adopted in real-world applications because of their simplicity, they suffer from potential semantic damage. Previous researchers have suggested easy data augmentation with soft labels (softEDA), employing label smoothing to mitigate this problem. However, finding the best factor for each model and dataset is challenging; therefore, using softEDA in real-world applications is still difficult. In this paper, we propose adapting AutoAugment to solve this problem. The experimental results suggest that the proposed method can boost existing augmentation methods and that rule-based methods can enhance cutting-edge pre-trained language models. We offer the source code.