 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Ground Trust to Truth: Disparities in Offensive Language Judgments on Contemporary Korean Political Discourse
Sep 18, 2025Although offensive language continually evolves over time, even recent studies using LLMs have predominantly relied on outdated datasets and rarely evaluated the generalization ability on unseen texts. In this study, we constructed a large-scale dataset of contemporary political discourse and employed three refined judgments in the absence of ground truth. Each judgment reflects a representative offensive language detection method and is carefully designed for optimal conditions. We identified distinct patterns for each judgment and demonstrated tendencies of label agreement using a leave-one-out strategy. By establishing pseudo-labels as ground trust for quantitative performance assessment, we observed that a strategically designed single prompting achieves comparable performance to more resource-intensive methods. This suggests a feasible approach applicable in real-world settings with inherent constraints.
DIAL: Dense Image-text ALignment for Weakly Supervised Semantic Segmentation
Sep 24, 2024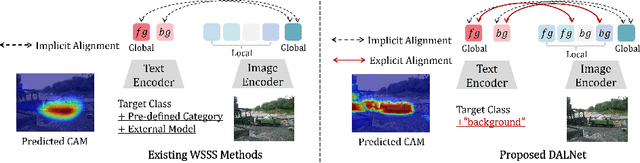
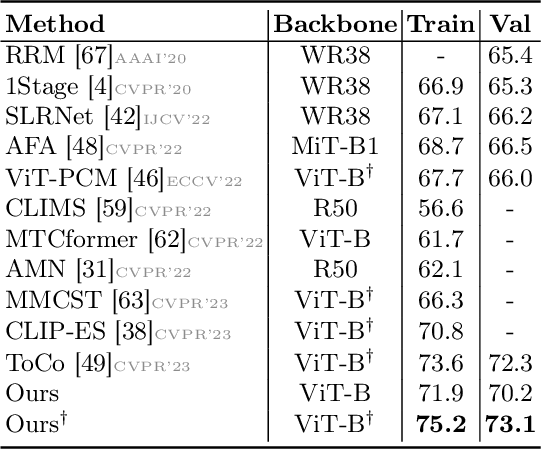
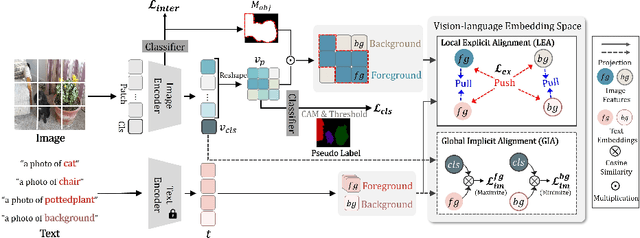
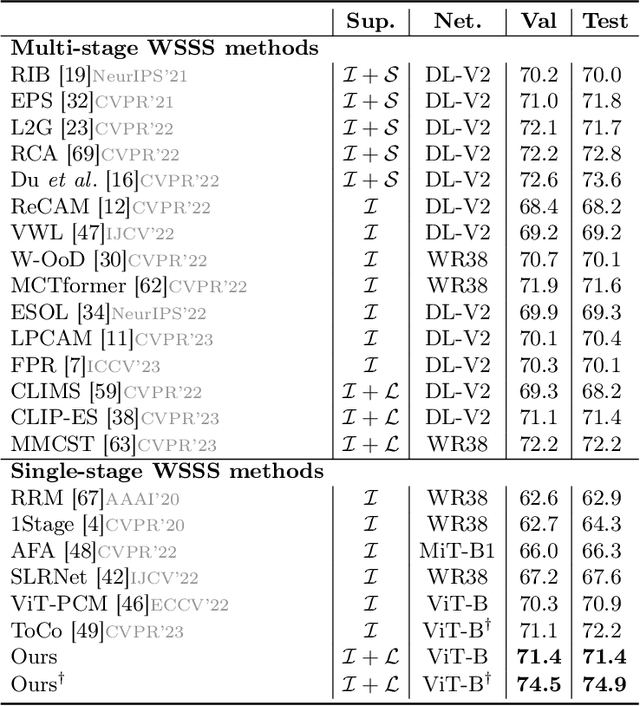
Weakly supervised semantic segmentation (WSSS) approaches typically rely on class activation maps (CAMs) for initial seed generation, which often fail to capture global context due to limited supervision from image-level labels. To address this issue, we introduce DALNet, Dense Alignment Learning Network that leverages text embeddings to enhance the comprehensive understanding and precise localization of objects across different levels of granularity. Our key insight is to employ a dual-level alignment strategy: (1) Global Implicit Alignment (GIA) to capture global semantics by maximizing the similarity between the class token and the corresponding text embeddings while minimizing the similarity with background embeddings, and (2) Local Explicit Alignment (LEA) to improve object localization by utilizing spatial information from patch tokens. Moreover, we propose a cross-contrastive learning approach that aligns foreground features between image and text modalities while separating them from the background, encouraging activation in missing regions and suppressing distractions. Through extensive experiments on the PASCAL VOC and MS COCO datasets, we demonstrate that DALNet significantly outperforms state-of-the-art WSSS methods. Our approach, in particular, allows for more efficient end-to-end process as a single-stage method.
Focus on the Core: Efficient Attention via Pruned Token Compression for Document Classification
Jun 03, 2024Transformer-based models have achieved dominant performance in numerous NLP tasks. Despite their remarkable successes, pre-trained transformers such as BERT suffer from a computationally expensive self-attention mechanism that interacts with all tokens, including the ones unfavorable to classification performance. To overcome these challenges, we propose integrating two strategies: token pruning and token combining. Token pruning eliminates less important tokens in the attention mechanism's key and value as they pass through the layers. Additionally, we adopt fuzzy logic to handle uncertainty and alleviate potential mispruning risks arising from an imbalanced distribution of each token's importance. Token combining, on the other hand, condenses input sequences into smaller sizes in order to further compress the model. By integrating these two approaches, we not only improve the model's performance but also reduce its computational demands. Experiments with various datasets demonstrate superior performance compared to baseline models, especially with the best improvement over the existing BERT model, achieving +5%p in accuracy and +5.6%p in F1 score. Additionally, memory cost is reduced to 0.61x, and a speedup of 1.64x is achieved.
Multi-News+: Cost-efficient Dataset Cleansing via LLM-based Data Annotation
Apr 15, 2024
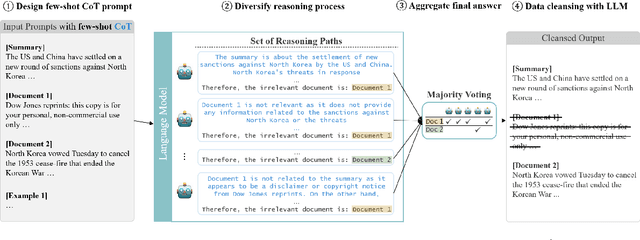
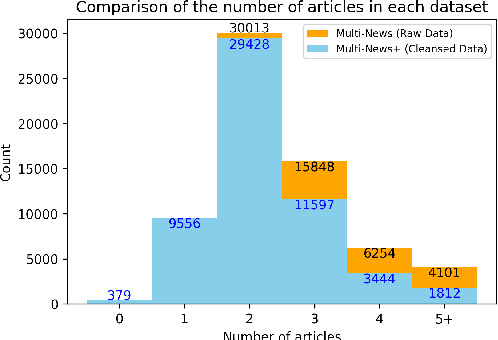
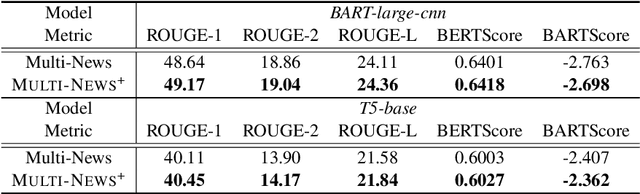
The quality of the dataset is crucial for ensuring optimal performance and reliability of downstream task models. However, datasets often contain noisy data inadvertently included during the construction process. Numerous attempts have been made to correct this issue through human annotators. However, hiring and managing human annotators is expensive and time-consuming. As an alternative, recent studies are exploring the use of large language models (LLMs) for data annotation. In this study, we present a case study that extends the application of LLM-based data annotation to enhance the quality of existing datasets through a cleansing strategy. Specifically, we leverage approaches such as chain-of-thought (CoT) and majority voting to imitate human annotation and classify unrelated documents from the Multi-News dataset, which is widely used for the multi-document summarization task. Through our proposed cleansing method, we introduce an enhanced Multi-News+. By employing LLMs for data cleansing, we demonstrate an efficient and effective approach to improving dataset quality without relying on expensive human annotation efforts.