 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEasy to Learn, Yet Hard to Forget: Towards Robust Unlearning Under Bias
Feb 25, 2026Machine unlearning, which enables a model to forget specific data, is crucial for ensuring data privacy and model reliability. However, its effectiveness can be severely undermined in real-world scenarios where models learn unintended biases from spurious correlations within the data. This paper investigates the unique challenges of unlearning from such biased models. We identify a novel phenomenon we term ``shortcut unlearning," where models exhibit an ``easy to learn, yet hard to forget" tendency. Specifically, models struggle to forget easily-learned, bias-aligned samples; instead of forgetting the class attribute, they unlearn the bias attribute, which can paradoxically improve accuracy on the class intended to be forgotten. To address this, we propose CUPID, a new unlearning framework inspired by the observation that samples with different biases exhibit distinct loss landscape sharpness. Our method first partitions the forget set into causal- and bias-approximated subsets based on sample sharpness, then disentangles model parameters into causal and bias pathways, and finally performs a targeted update by routing refined causal and bias gradients to their respective pathways. Extensive experiments on biased datasets including Waterbirds, BAR, and Biased NICO++ demonstrate that our method achieves state-of-the-art forgetting performance and effectively mitigates the shortcut unlearning problem.
Proceedings of 1st Workshop on Advancing Artificial Intelligence through Theory of Mind
Apr 28, 2025



This volume includes a selection of papers presented at the Workshop on Advancing Artificial Intelligence through Theory of Mind held at AAAI 2025 in Philadelphia US on 3rd March 2025. The purpose of this volume is to provide an open access and curated anthology for the ToM and AI research community.
See-Saw Modality Balance: See Gradient, and Sew Impaired Vision-Language Balance to Mitigate Dominant Modality Bias
Mar 18, 2025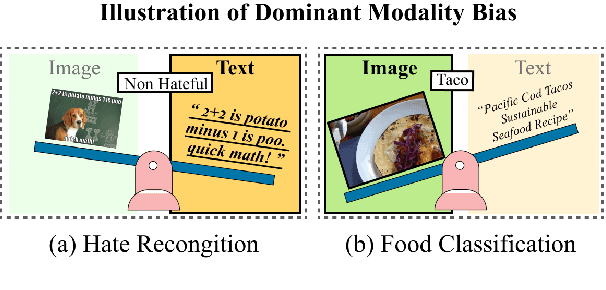
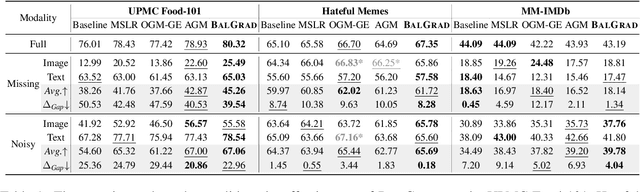
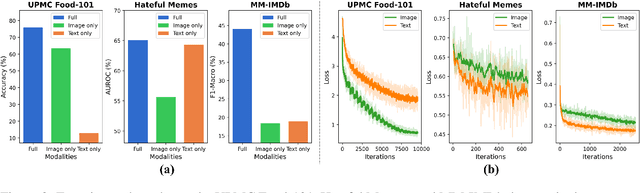
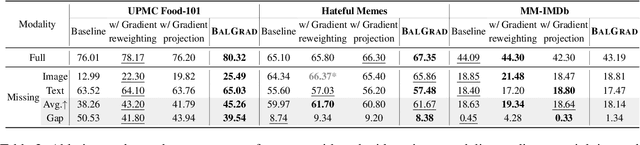
Vision-language (VL) models have demonstrated strong performance across various tasks. However, these models often rely on a specific modality for predictions, leading to "dominant modality bias.'' This bias significantly hurts performance, especially when one modality is impaired. In this study, we analyze model behavior under dominant modality bias and theoretically show that unaligned gradients or differences in gradient magnitudes prevent balanced convergence of the loss. Based on these findings, we propose a novel framework, BalGrad to mitigate dominant modality bias. Our approach includes inter-modality gradient reweighting, adjusting the gradient of KL divergence based on each modality's contribution, and inter-task gradient projection to align task directions in a non-conflicting manner. Experiments on UPMC Food-101, Hateful Memes, and MM-IMDb datasets confirm that BalGrad effectively alleviates over-reliance on specific modalities when making predictions.
DIAL: Dense Image-text ALignment for Weakly Supervised Semantic Segmentation
Sep 24, 2024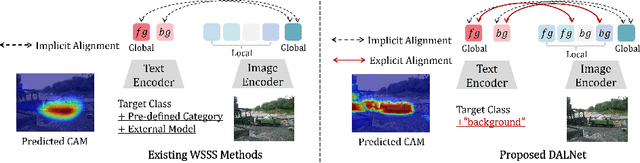
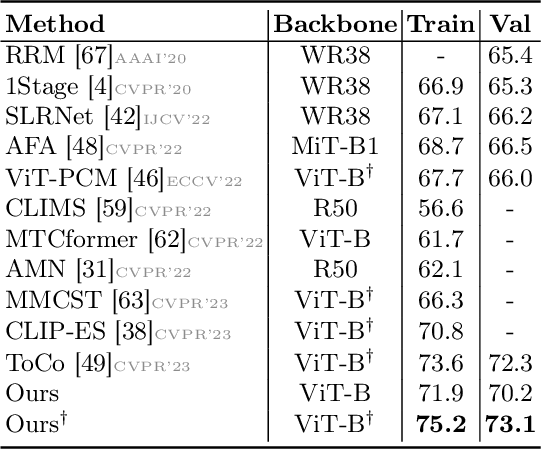
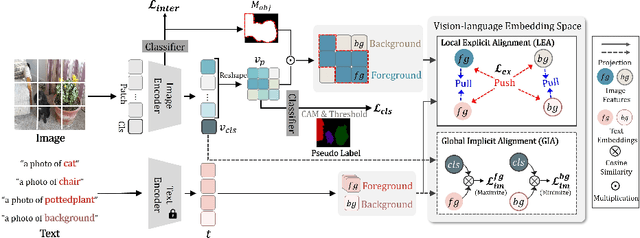
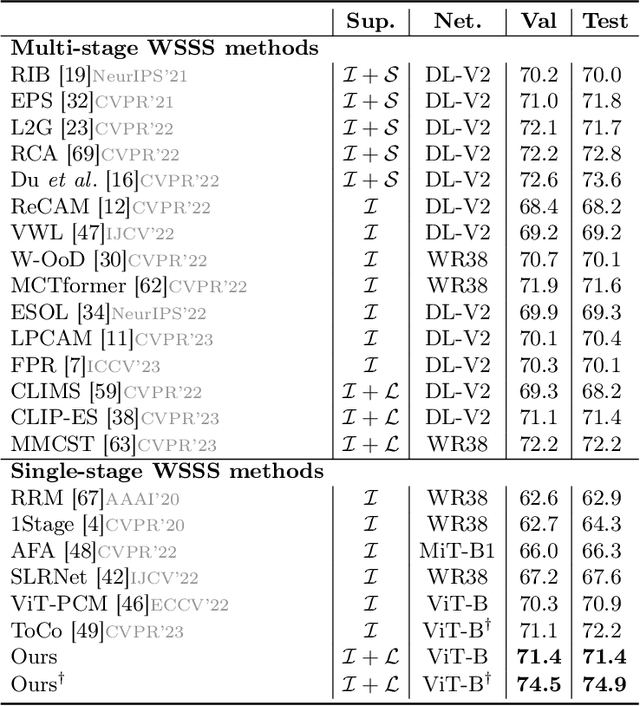
Weakly supervised semantic segmentation (WSSS) approaches typically rely on class activation maps (CAMs) for initial seed generation, which often fail to capture global context due to limited supervision from image-level labels. To address this issue, we introduce DALNet, Dense Alignment Learning Network that leverages text embeddings to enhance the comprehensive understanding and precise localization of objects across different levels of granularity. Our key insight is to employ a dual-level alignment strategy: (1) Global Implicit Alignment (GIA) to capture global semantics by maximizing the similarity between the class token and the corresponding text embeddings while minimizing the similarity with background embeddings, and (2) Local Explicit Alignment (LEA) to improve object localization by utilizing spatial information from patch tokens. Moreover, we propose a cross-contrastive learning approach that aligns foreground features between image and text modalities while separating them from the background, encouraging activation in missing regions and suppressing distractions. Through extensive experiments on the PASCAL VOC and MS COCO datasets, we demonstrate that DALNet significantly outperforms state-of-the-art WSSS methods. Our approach, in particular, allows for more efficient end-to-end process as a single-stage method.
Learning to Detour: Shortcut Mitigating Augmentation for Weakly Supervised Semantic Segmentation
May 28, 2024Weakly supervised semantic segmentation (WSSS) employing weak forms of labels has been actively studied to alleviate the annotation cost of acquiring pixel-level labels. However, classifiers trained on biased datasets tend to exploit shortcut features and make predictions based on spurious correlations between certain backgrounds and objects, leading to a poor generalization performance. In this paper, we propose shortcut mitigating augmentation (SMA) for WSSS, which generates synthetic representations of object-background combinations not seen in the training data to reduce the use of shortcut features. Our approach disentangles the object-relevant and background features. We then shuffle and combine the disentangled representations to create synthetic features of diverse object-background combinations. SMA-trained classifier depends less on contexts and focuses more on the target object when making predictions. In addition, we analyzed the behavior of the classifier on shortcut usage after applying our augmentation using an attribution method-based metric. The proposed method achieved the improved performance of semantic segmentation result on PASCAL VOC 2012 and MS COCO 2014 datasets.
GPTs Are Multilingual Annotators for Sequence Generation Tasks
Feb 08, 2024Data annotation is an essential step for constructing new datasets. However, the conventional approach of data annotation through crowdsourcing is both time-consuming and expensive. In addition, the complexity of this process increases when dealing with low-resource languages owing to the difference in the language pool of crowdworkers. To address these issues, this study proposes an autonomous annotation method by utilizing large language models, which have been recently demonstrated to exhibit remarkable performance. Through our experiments, we demonstrate that the proposed method is not just cost-efficient but also applicable for low-resource language annotation. Additionally, we constructed an image captioning dataset using our approach and are committed to open this dataset for future study. We have opened our source code for further study and reproducibility.