 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowing When to Answer: Adaptive Confidence Refinement for Reliable Audio-Visual Question Answering
Feb 04, 2026We present a formal problem formulation for \textit{Reliable} Audio-Visual Question Answering ($\mathcal{R}$-AVQA), where we prefer abstention over answering incorrectly. While recent AVQA models have high accuracy, their ability to identify when they are likely wrong and their consequent abstention from answering remain underexplored areas of research. To fill this gap, we explore several approaches and then propose Adaptive Confidence Refinement (ACR), a lightweight method to further enhance the performance of $\mathcal{R}$-AVQA. Our key insight is that the Maximum Softmax Probability (MSP) is Bayes-optimal only under strong calibration, a condition usually not met in deep neural networks, particularly in multimodal models. Instead of replacing MSP, our ACR maintains it as a primary confidence signal and applies input-adaptive residual corrections when MSP is deemed unreliable. ACR introduces two learned heads: i) a Residual Risk Head that predicts low-magnitude correctness residuals that MSP does not capture, and ii) a Confidence Gating Head to determine MSP trustworthiness. Our experiments and theoretical analysis show that ACR consistently outperforms existing methods on in- and out-of-disrtibution, and data bias settings across three different AVQA architectures, establishing a solid foundation for $\mathcal{R}$-AVQA task. The code and checkpoints will be available upon acceptance \href{https://github.com/PhuTran1005/R-AVQA}{at here}
Reference-Based Post-OCR Processing with LLM for Diacritic Languages
Oct 17, 2024
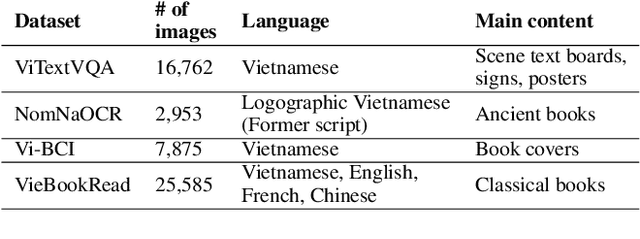

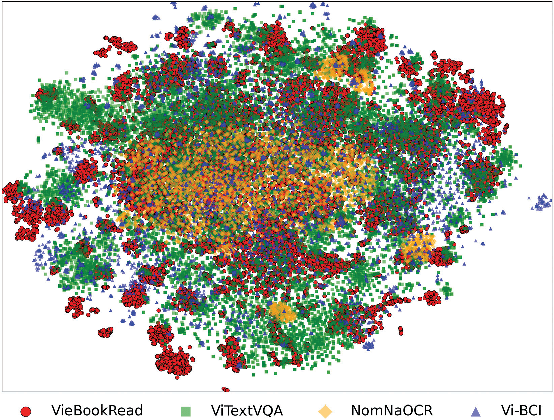
Extracting fine-grained OCR text from aged documents in diacritic languages remains challenging due to unexpected artifacts, time-induced degradation, and lack of datasets. While standalone spell correction approaches have been proposed, they show limited performance for historical documents due to numerous possible OCR error combinations and differences between modern and classical corpus distributions. We propose a method utilizing available content-focused ebooks as a reference base to correct imperfect OCR-generated text, supported by large language models. This technique generates high-precision pseudo-page-to-page labels for diacritic languages, where small strokes pose significant challenges in historical conditions. The pipeline eliminates various types of noise from aged documents and addresses issues such as missing characters, words, and disordered sequences. Our post-processing method, which generated a large OCR dataset of classical Vietnamese books, achieved a mean grading score of 8.72 on a 10-point scale. This outperformed the state-of-the-art transformer-based Vietnamese spell correction model, which scored 7.03 when evaluated on a sampled subset of the dataset. We also trained a baseline OCR model to assess and compare it with well-known engines. Experimental results demonstrate the strength of our baseline model compared to widely used open-source solutions. The resulting dataset will be released publicly to support future studies.
QuickBrowser: A Unified Model to Detect and Read Simple Object in Real-time
Feb 15, 2021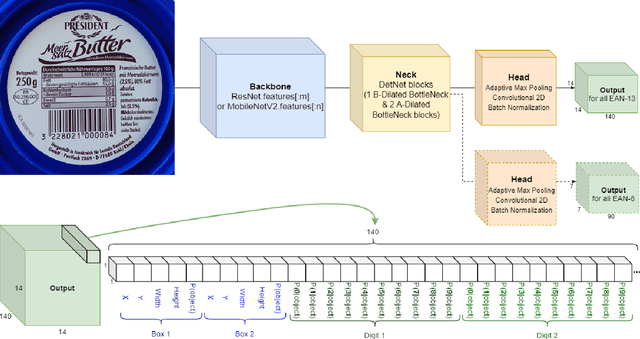

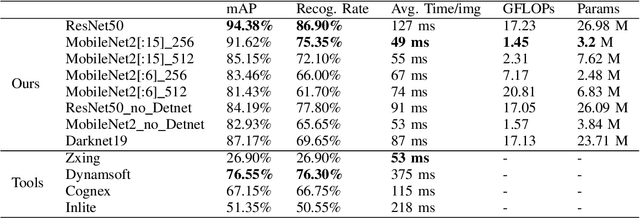

There are many real-life use cases such as barcode scanning or billboard reading where people need to detect objects and read the object contents. Commonly existing methods are first trying to localize object regions, then determine layout and lastly classify content units. However, for simple fixed structured objects like license plates, this approach becomes overkill and lengthy to run. This work aims to solve this detect-and-read problem in a lightweight way by integrating multi-digit recognition into a one-stage object detection model. Our unified method not only eliminates the duplication in feature extraction (one for localizing, one again for classifying) but also provides useful contextual information around object regions for classification. Additionally, our choice of backbones and modifications in architecture, loss function, data augmentation and training make the method robust, efficient and speedy. Secondly, we made a public benchmark dataset of diverse real-life 1D barcodes for a reliable evaluation, which we collected, annotated and checked carefully. Eventually, experimental results prove the method's efficiency on the barcode problem by outperforming industrial tools in both detecting and decoding rates with a real-time fps at a VGA-similar resolution. It also did a great job expectedly on the license-plate recognition task (on the AOLP dataset) by outperforming the current state-of-the-art method significantly in terms of recognition rate and inference time.
Smart Inference for Multidigit Convolutional Neural Network based Barcode Decoding
Apr 14, 2020
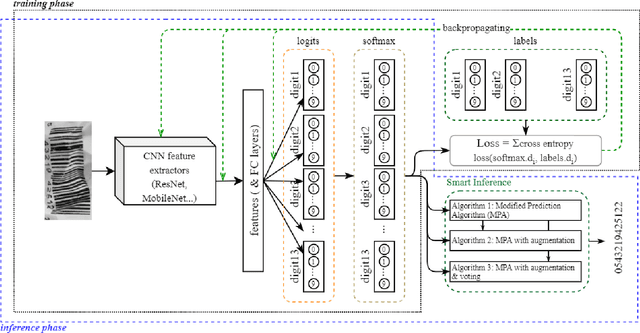
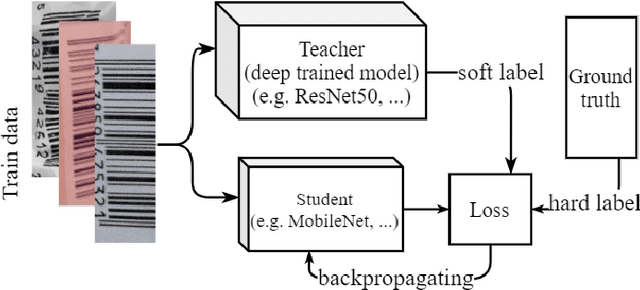
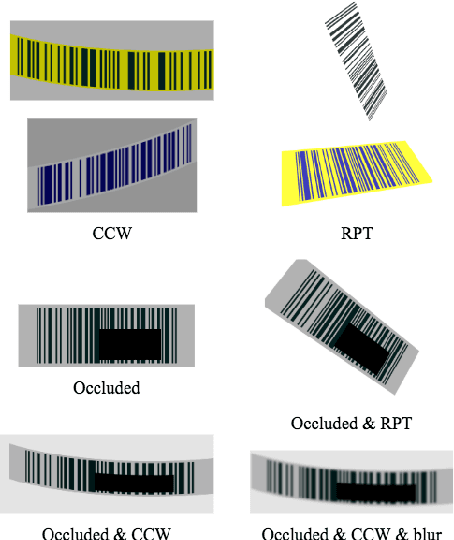
Barcodes are ubiquitous and have been used in most of critical daily activities for decades. However, most of traditional decoders require well-founded barcode under a relatively standard condition. While wilder conditioned barcodes such as underexposed, occluded, blurry, wrinkled and rotated are commonly captured in reality, those traditional decoders show weakness of recognizing. Several works attempted to solve those challenging barcodes, but many limitations still exist. This work aims to solve the decoding problem using deep convolutional neural network with the possibility of running on portable devices. Firstly, we proposed a special modification of inference based on the feature of having checksum and test-time augmentation, named as Smart Inference (SI) in prediction phase of a trained model. SI considerably boosts accuracy and reduces the false prediction for trained models. Secondly, we have created a large practical evaluation dataset of real captured 1D barcode under various challenging conditions to test our methods vigorously, which is publicly available for other researchers. The experiments' results demonstrated the SI effectiveness with the highest accuracy of 95.85% which outperformed many existing decoders on the evaluation set. Finally, we successfully minimized the best model by knowledge distillation to a shallow model which is shown to have high accuracy (90.85%) with good inference speed of 34.2 ms per image on a real edge device.
Dissecting Catastrophic Forgetting in Continual Learning by Deep Visualization
Jan 07, 2020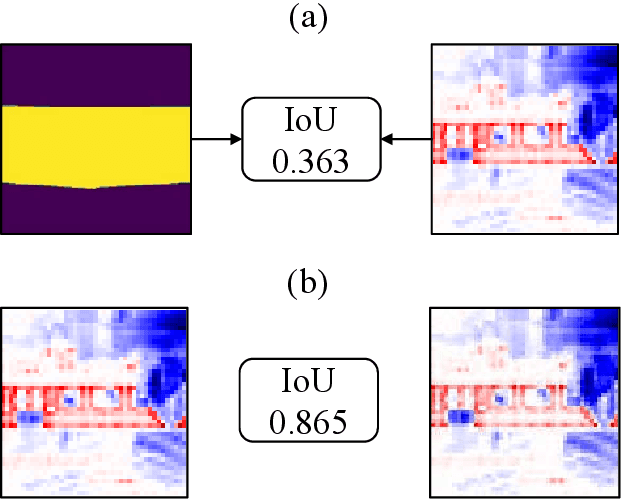

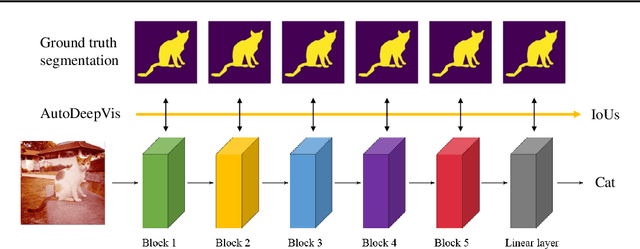
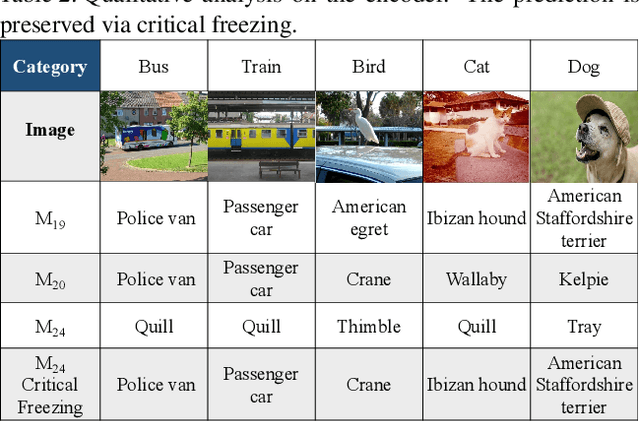
Interpreting the behaviors of Deep Neural Networks (usually considered as a black box) is critical especially when they are now being widely adopted over diverse aspects of human life. Taking the advancements from Explainable Artificial Intelligent, this paper proposes a novel technique called Auto DeepVis to dissect catastrophic forgetting in continual learning. A new method to deal with catastrophic forgetting named critical freezing is also introduced upon investigating the dilemma by Auto DeepVis. Experiments on a captioning model meticulously present how catastrophic forgetting happens, particularly showing which components are forgetting or changing. The effectiveness of our technique is then assessed; and more precisely, critical freezing claims the best performance on both previous and coming tasks over baselines, proving the capability of the investigation. Our techniques could not only be supplementary to existing solutions for completely eradicating catastrophic forgetting for life-long learning but also explainable.