 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReference-Based Post-OCR Processing with LLM for Diacritic Languages
Paper and Code

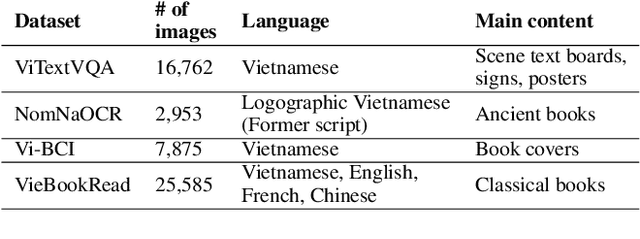

Extracting fine-grained OCR text from aged documents in diacritic languages remains challenging due to unexpected artifacts, time-induced degradation, and lack of datasets. While standalone spell correction approaches have been proposed, they show limited performance for historical documents due to numerous possible OCR error combinations and differences between modern and classical corpus distributions. We propose a method utilizing available content-focused ebooks as a reference base to correct imperfect OCR-generated text, supported by large language models. This technique generates high-precision pseudo-page-to-page labels for diacritic languages, where small strokes pose significant challenges in historical conditions. The pipeline eliminates various types of noise from aged documents and addresses issues such as missing characters, words, and disordered sequences. Our post-processing method, which generated a large OCR dataset of classical Vietnamese books, achieved a mean grading score of 8.72 on a 10-point scale. This outperformed the state-of-the-art transformer-based Vietnamese spell correction model, which scored 7.03 when evaluated on a sampled subset of the dataset. We also trained a baseline OCR model to assess and compare it with well-known engines. Experimental results demonstrate the strength of our baseline model compared to widely used open-source solutions. The resulting dataset will be released publicly to support future studies.