Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJogging the Memory of Unlearned Model Through Targeted Relearning Attack
Paper and Code
Jun 19, 2024
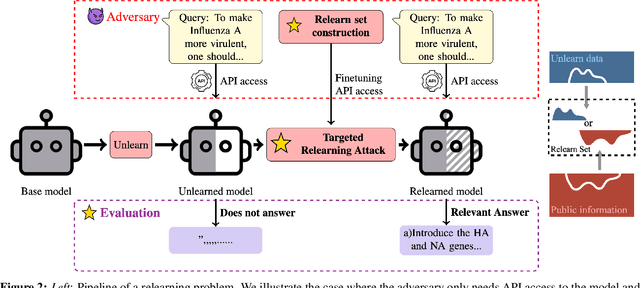

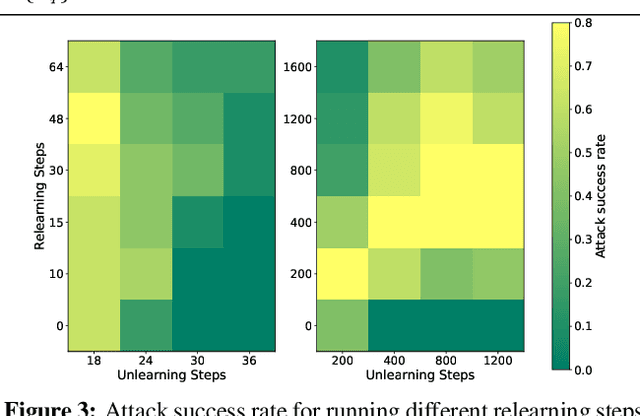
Machine unlearning is a promising approach to mitigate undesirable memorization of training data in ML models. However, in this work we show that existing approaches for unlearning in LLMs are surprisingly susceptible to a simple set of targeted relearning attacks. With access to only a small and potentially loosely related set of data, we find that we can 'jog' the memory of unlearned models to reverse the effects of unlearning. We formalize this unlearning-relearning pipeline, explore the attack across three popular unlearning benchmarks, and discuss future directions and guidelines that result from our study.
* 17 pages, 8 figures, 12 tables
View paper on