 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Summarize Videos by Contrasting Clips
Jan 13, 2023


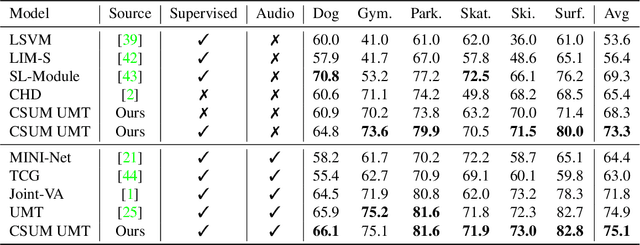
Video summarization aims at choosing parts of a video that narrate a story as close as possible to the original one. Most of the existing video summarization approaches focus on hand-crafted labels. As the number of videos grows exponentially, there emerges an increasing need for methods that can learn meaningful summarizations without labeled annotations. In this paper, we aim to maximally exploit unsupervised video summarization while concentrating the supervision to a few, personalized labels as an add-on. To do so, we formulate the key requirements for the informative video summarization. Then, we propose contrastive learning as the answer to both questions. To further boost Contrastive video Summarization (CSUM), we propose to contrast top-k features instead of a mean video feature as employed by the existing method, which we implement with a differentiable top-k feature selector. Our experiments on several benchmarks demonstrate, that our approach allows for meaningful and diverse summaries when no labeled data is provided.