 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM Benchmark Datasets Should Be Contamination-Resistant
May 19, 2026Benchmark datasets are critical for reproducible, reliable, and discriminative evaluation of LLMs. However, recent studies reveal that many benchmark datasets are included in pretraining corpora, i.e., $\textit{contaminated}$, which diminishes their value as reliable measures of model generalization. In this paper, we argue that benchmark datasets should be $\textit{contamination-resistant}$, i.e., $\textit{unlearnable}$, but support $\textit{inference}$. To accomplish this, we first highlight the wide prevalence of benchmark dataset contamination and outline the properties of contamination-resistant datasets. Second, we highlight how the asymmetry between the inference and training pipelines in the Transformer architecture can be leveraged to support contamination-resistance. Third, we outline mathematical advancements to make these datasets interoperable across various LLM architectures. Based on the above, we call on the community to ensure the reliability of LLM benchmarking by: (i) advancing novel contamination-resistant methodologies, (ii) developing supporting methods and platforms, and (iii) adopting contamination-resistant benchmarks into existing evaluation pipelines.
Moltbook Moderation: Uncovering Hidden Intent Through Multi-Turn Dialogue
May 14, 2026The emergence of multi-agent systems introduces novel moderation challenges that extend beyond content filtering. Agents with malicious intent may contribute harmful content that appears benign to evade content-based moderation, while compromising the system through exploitative and malicious behavior manifested across their overall interaction patterns within the community. To address this, we introduce BOT-MOD (BOT-MODeration), a moderation framework that grounds detection in agent intent rather than traditional content level signals. BOT-MOD identifies the underlying intent by engaging with the target agent in a multi-turn exchange guided by Gibbs-based sampling over candidate intent hypotheses. This progressively narrows the space of plausible agent objectives to identify the underlying behavior. To evaluate our approach, we construct a dataset derived from Moltbook that encompasses diverse benign and malicious behaviors based on actual community structures, posts, and comments. Results demonstrate that BOT-MOD reliably identifies agent intent across a range of adversarial configurations, while maintaining a low false positive rate on benign behaviors. This work advances the foundation for scalable, intent-aware moderation of agents in open multi-agent environments.
DIA-HARM: Dialectal Disparities in Harmful Content Detection Across 50 English Dialects
Apr 07, 2026Harmful content detectors-particularly disinformation classifiers-are predominantly developed and evaluated on Standard American English (SAE), leaving their robustness to dialectal variation unexplored. We present DIA-HARM, the first benchmark for evaluating disinformation detection robustness across 50 English dialects spanning U.S., British, African, Caribbean, and Asia-Pacific varieties. Using Multi-VALUE's linguistically grounded transformations, we introduce D3 (Dialectal Disinformation Detection), a corpus of 195K samples derived from established disinformation benchmarks. Our evaluation of 16 detection models reveals systematic vulnerabilities: human-written dialectal content degrades detection by 1.4-3.6% F1, while AI-generated content remains stable. Fine-tuned transformers substantially outperform zero-shot LLMs (96.6% vs. 78.3% best-case F1), with some models exhibiting catastrophic failures exceeding 33% degradation on mixed content. Cross-dialectal transfer analysis across 2,450 dialect pairs shows that multilingual models (mDeBERTa: 97.2% average F1) generalize effectively, while monolingual models like RoBERTa and XLM-RoBERTa fail on dialectal inputs. These findings demonstrate that current disinformation detectors may systematically disadvantage hundreds of millions of non-SAE speakers worldwide. We release the DIA-HARM framework, D3 corpus, and evaluation tools: https://github.com/jsl5710/dia-harm
BLUFF: Benchmarking the Detection of False and Synthetic Content across 58 Low-Resource Languages
Feb 28, 2026Multilingual falsehoods threaten information integrity worldwide, yet detection benchmarks remain confined to English or a few high-resource languages, leaving low-resource linguistic communities without robust defense tools. We introduce BLUFF, a comprehensive benchmark for detecting false and synthetic content, spanning 79 languages with over 202K samples, combining human-written fact-checked content (122K+ samples across 57 languages) and LLM-generated content (79K+ samples across 71 languages). BLUFF uniquely covers both high-resource "big-head" (20) and low-resource "long-tail" (59) languages, addressing critical gaps in multilingual research on detecting false and synthetic content. Our dataset features four content types (human-written, LLM-generated, LLM-translated, and hybrid human-LLM text), bidirectional translation (English$\leftrightarrow$X), 39 textual modification techniques (36 manipulation tactics for fake news, 3 AI-editing strategies for real news), and varying edit intensities generated using 19 diverse LLMs. We present AXL-CoI (Adversarial Cross-Lingual Agentic Chainof-Interactions), a novel multi-agentic framework for controlled fake/real news generation, paired with mPURIFY, a quality filtering pipeline ensuring dataset integrity. Experiments reveal state-of-theart detectors suffer up to 25.3% F1 degradation on low-resource versus high-resource languages. BLUFF provides the research community with a multilingual benchmark, extensive linguistic-oriented benchmark evaluation, comprehensive documentation, and opensource tools to advance equitable falsehood detection. Dataset and code are available at: https://jsl5710.github.io/BLUFF/
A Systemic Evaluation of Multimodal RAG Privacy
Jan 27, 2026The growing adoption of multimodal Retrieval-Augmented Generation (mRAG) pipelines for vision-centric tasks (e.g. visual QA) introduces important privacy challenges. In particular, while mRAG provides a practical capability to connect private datasets to improve model performance, it risks the leakage of private information from these datasets during inference. In this paper, we perform an empirical study to analyze the privacy risks inherent in the mRAG pipeline observed through standard model prompting. Specifically, we implement a case study that attempts to infer the inclusion of a visual asset, e.g. image, in the mRAG, and if present leak the metadata, e.g. caption, related to it. Our findings highlight the need for privacy-preserving mechanisms and motivate future research on mRAG privacy.
Graph-based Molecular In-context Learning Grounded on Morgan Fingerprints
Feb 08, 2025



In-context learning (ICL) effectively conditions large language models (LLMs) for molecular tasks, such as property prediction and molecule captioning, by embedding carefully selected demonstration examples into the input prompt. This approach avoids the computational overhead of extensive pertaining and fine-tuning. However, current prompt retrieval methods for molecular tasks have relied on molecule feature similarity, such as Morgan fingerprints, which do not adequately capture the global molecular and atom-binding relationships. As a result, these methods fail to represent the full complexity of molecular structures during inference. Moreover, small-to-medium-sized LLMs, which offer simpler deployment requirements in specialized systems, have remained largely unexplored in the molecular ICL literature. To address these gaps, we propose a self-supervised learning technique, GAMIC (Graph-Aligned Molecular In-Context learning, which aligns global molecular structures, represented by graph neural networks (GNNs), with textual captions (descriptions) while leveraging local feature similarity through Morgan fingerprints. In addition, we introduce a Maximum Marginal Relevance (MMR) based diversity heuristic during retrieval to optimize input prompt demonstration samples. Our experimental findings using diverse benchmark datasets show GAMIC outperforms simple Morgan-based ICL retrieval methods across all tasks by up to 45%.
Semantic Captioning: Benchmark Dataset and Graph-Aware Few-Shot In-Context Learning for SQL2Text
Jan 06, 2025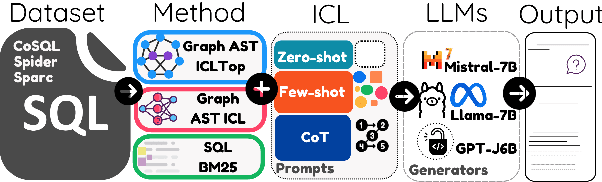
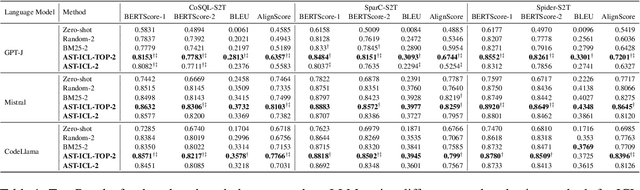

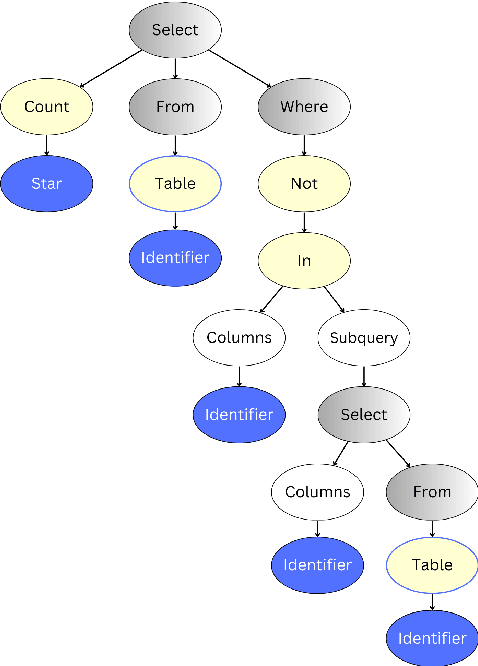
Large Language Models (LLMs) have demonstrated remarkable performance in various NLP tasks, including semantic parsing, which trans lates natural language into formal code representations. However, the reverse process, translating code into natural language, termed semantic captioning, has received less attention. This task is becoming increasingly important as LLMs are integrated into platforms for code generation, security analysis, and educational purposes. In this paper, we focus on the captioning of SQL query (SQL2Text) to address the critical need for understanding and explaining SQL queries in an era where LLM-generated code poses potential security risks. We repurpose Text2SQL datasets for SQL2Text by introducing an iterative ICL prompt using GPT-4o to generate multiple additional utterances, which enhances the robustness of the datasets for the reverse task. We conduct our experiments using in-context learning (ICL) based on different sample selection methods, emphasizing smaller, more computationally efficient LLMs. Our findings demonstrate that leveraging the inherent graph properties of SQL for ICL sample selection significantly outperforms random selection by up to 39% on BLEU score and provides better results than alternative methods. Dataset and codes are published: \url{https://github.com/aliwister/ast-icl}.
WildGraph: Realistic Graph-based Trajectory Generation for Wildlife
Apr 11, 2024



Trajectory generation is an important task in movement studies; it circumvents the privacy, ethical, and technical challenges of collecting real trajectories from the target population. In particular, real trajectories in the wildlife domain are scarce as a result of ethical and environmental constraints of the collection process. In this paper, we consider the problem of generating long-horizon trajectories, akin to wildlife migration, based on a small set of real samples. We propose a hierarchical approach to learn the global movement characteristics of the real dataset and recursively refine localized regions. Our solution, WildGraph, discretizes the geographic path into a prototype network of H3 (https://www.uber.com/blog/h3/) regions and leverages a recurrent variational auto-encoder to probabilistically generate paths over the regions, based on occupancy. WildGraph successfully generates realistic months-long trajectories using a sample size as small as 60. Experiments performed on two wildlife migration datasets demonstrate that our proposed method improves the generalization of the generated trajectories in comparison to existing work while achieving superior or comparable performance in several benchmark metrics. Our code is published on the following repository: \url{https://github.com/aliwister/wildgraph}.
WildGEN: Long-horizon Trajectory Generation for Wildlife
Dec 30, 2023Trajectory generation is an important concern in pedestrian, vehicle, and wildlife movement studies. Generated trajectories help enrich the training corpus in relation to deep learning applications, and may be used to facilitate simulation tasks. This is especially significant in the wildlife domain, where the cost of obtaining additional real data can be prohibitively expensive, time-consuming, and bear ethical considerations. In this paper, we introduce WildGEN: a conceptual framework that addresses this challenge by employing a Variational Auto-encoders (VAEs) based method for the acquisition of movement characteristics exhibited by wild geese over a long horizon using a sparse set of truth samples. A subsequent post-processing step of the generated trajectories is performed based on smoothing filters to reduce excessive wandering. Our evaluation is conducted through visual inspection and the computation of the Hausdorff distance between the generated and real trajectories. In addition, we utilize the Pearson Correlation Coefficient as a way to measure how realistic the trajectories are based on the similarity of clusters evaluated on the generated and real trajectories.