 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Ray Neural Radiance Fields for Novel-view Synthesis from Unconstrained Image Collections
Jul 16, 2023



Neural Radiance Fields (NeRF) is a revolutionary approach for rendering scenes by sampling a single ray per pixel and it has demonstrated impressive capabilities in novel-view synthesis from static scene images. However, in practice, we usually need to recover NeRF from unconstrained image collections, which poses two challenges: 1) the images often have dynamic changes in appearance because of different capturing time and camera settings; 2) the images may contain transient objects such as humans and cars, leading to occlusion and ghosting artifacts. Conventional approaches seek to address these challenges by locally utilizing a single ray to synthesize a color of a pixel. In contrast, humans typically perceive appearance and objects by globally utilizing information across multiple pixels. To mimic the perception process of humans, in this paper, we propose Cross-Ray NeRF (CR-NeRF) that leverages interactive information across multiple rays to synthesize occlusion-free novel views with the same appearances as the images. Specifically, to model varying appearances, we first propose to represent multiple rays with a novel cross-ray feature and then recover the appearance by fusing global statistics, i.e., feature covariance of the rays and the image appearance. Moreover, to avoid occlusion introduced by transient objects, we propose a transient objects handler and introduce a grid sampling strategy for masking out the transient objects. We theoretically find that leveraging correlation across multiple rays promotes capturing more global information. Moreover, extensive experimental results on large real-world datasets verify the effectiveness of CR-NeRF.
Attention Guided Network for Retinal Image Segmentation
Jul 25, 2019
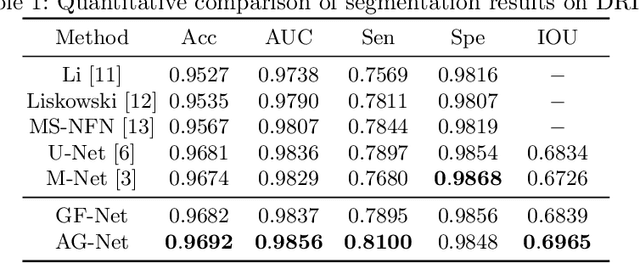
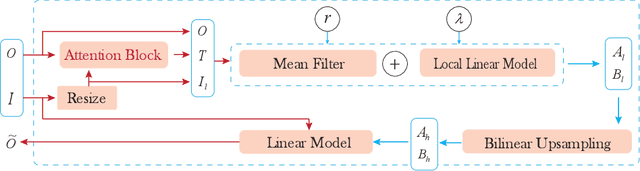

Learning structural information is critical for producing an ideal result in retinal image segmentation. Recently, convolutional neural networks have shown a powerful ability to extract effective representations. However, convolutional and pooling operations filter out some useful structural information. In this paper, we propose an Attention Guided Network (AG-Net) to preserve the structural information and guide the expanding operation. In our AG-Net, the guided filter is exploited as a structure sensitive expanding path to transfer structural information from previous feature maps, and an attention block is introduced to exclude the noise and reduce the negative influence of background further. The extensive experiments on two retinal image segmentation tasks (i.e., blood vessel segmentation, optic disc and cup segmentation) demonstrate the effectiveness of our proposed method.