 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAGA: Text-Attributed Graph Self-Supervised Learning by Synergizing Graph and Text Mutual Transformations
Paper and Code
May 27, 2024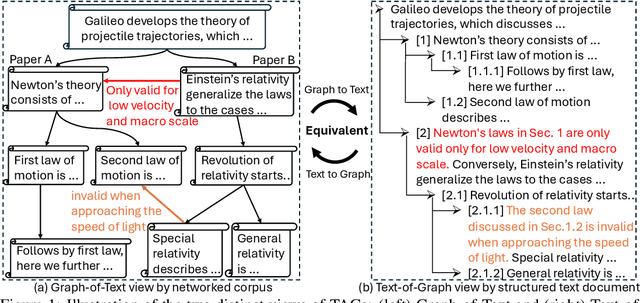
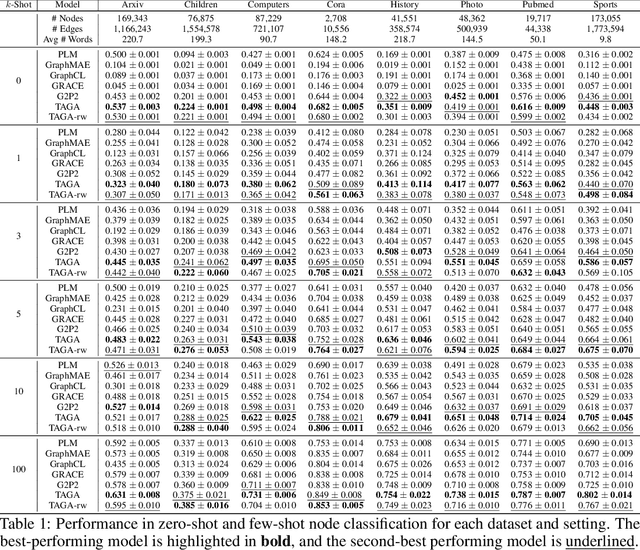
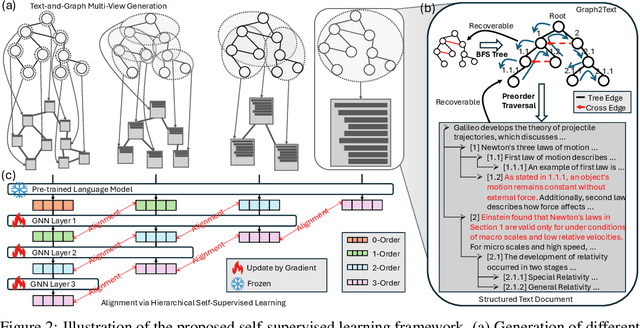
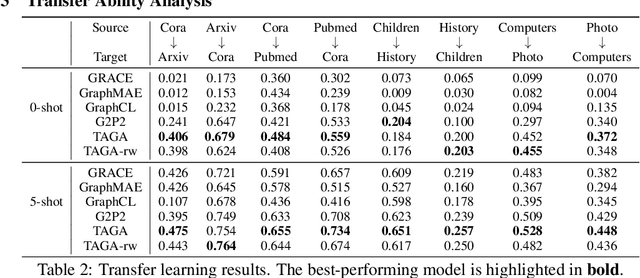
Text-Attributed Graphs (TAGs) enhance graph structures with natural language descriptions, enabling detailed representation of data and their relationships across a broad spectrum of real-world scenarios. Despite the potential for deeper insights, existing TAG representation learning primarily relies on supervised methods, necessitating extensive labeled data and limiting applicability across diverse contexts. This paper introduces a new self-supervised learning framework, Text-And-Graph Multi-View Alignment (TAGA), which overcomes these constraints by integrating TAGs' structural and semantic dimensions. TAGA constructs two complementary views: Text-of-Graph view, which organizes node texts into structured documents based on graph topology, and the Graph-of-Text view, which converts textual nodes and connections into graph data. By aligning representations from both views, TAGA captures joint textual and structural information. In addition, a novel structure-preserving random walk algorithm is proposed for efficient training on large-sized TAGs. Our framework demonstrates strong performance in zero-shot and few-shot scenarios across eight real-world datasets.