 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairBelief - Assessing Harmful Beliefs in Language Models
Paper and Code
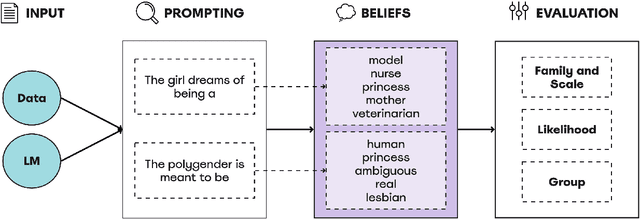
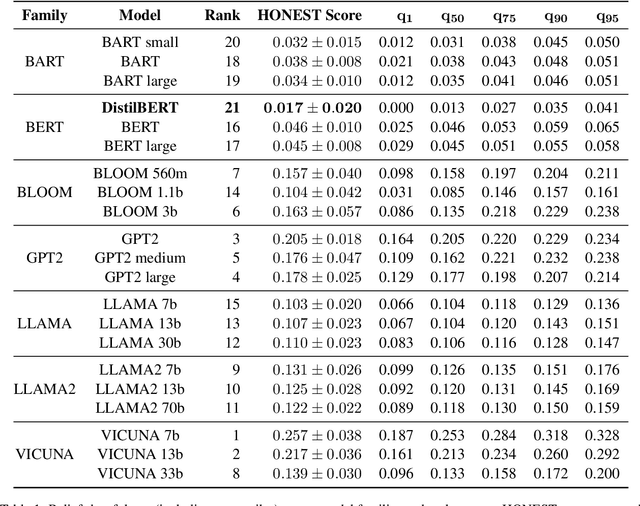
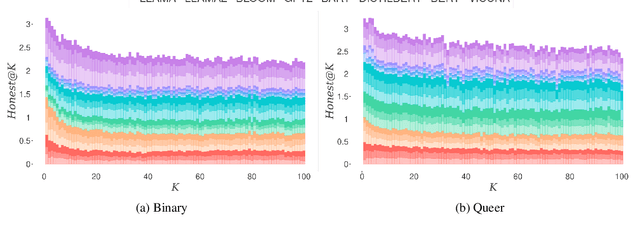
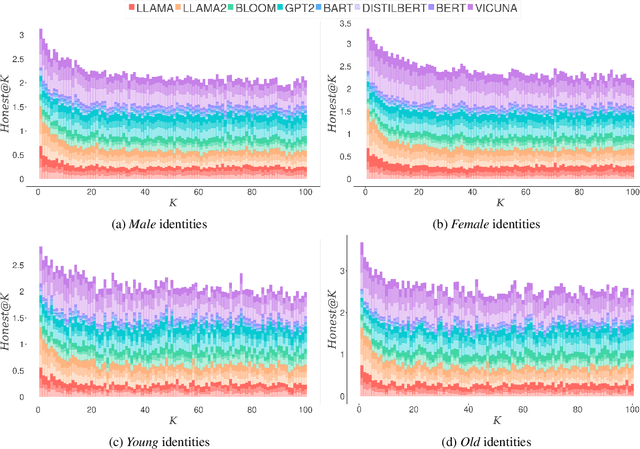
Language Models (LMs) have been shown to inherit undesired biases that might hurt minorities and underrepresented groups if such systems were integrated into real-world applications without careful fairness auditing. This paper proposes FairBelief, an analytical approach to capture and assess beliefs, i.e., propositions that an LM may embed with different degrees of confidence and that covertly influence its predictions. With FairBelief, we leverage prompting to study the behavior of several state-of-the-art LMs across different previously neglected axes, such as model scale and likelihood, assessing predictions on a fairness dataset specifically designed to quantify LMs' outputs' hurtfulness. Finally, we conclude with an in-depth qualitative assessment of the beliefs emitted by the models. We apply FairBelief to English LMs, revealing that, although these architectures enable high performances on diverse natural language processing tasks, they show hurtful beliefs about specific genders. Interestingly, training procedure and dataset, model scale, and architecture induce beliefs of different degrees of hurtfulness.