 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Label Variation in Large Language Models for Zero-Shot Text Classification
Paper and Code

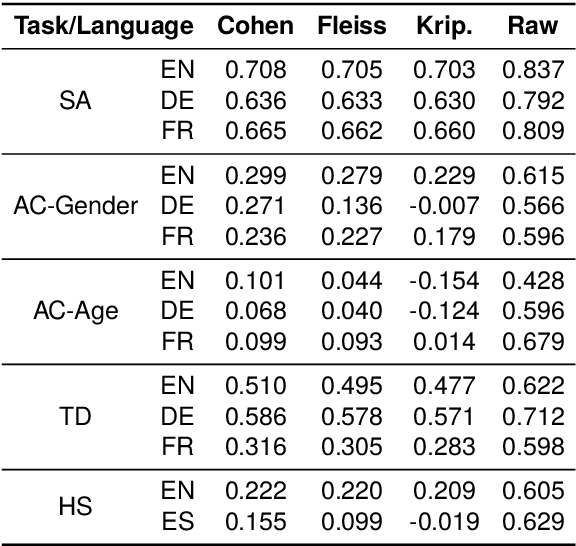

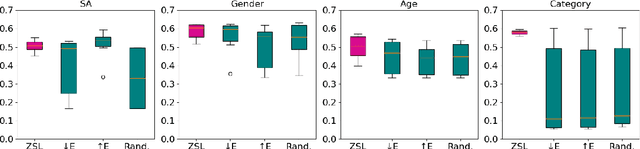
The zero-shot learning capabilities of large language models (LLMs) make them ideal for text classification without annotation or supervised training. Many studies have shown impressive results across multiple tasks. While tasks, data, and results differ widely, their similarities to human annotation can aid us in tackling new tasks with minimal expenses. We evaluate using 5 state-of-the-art LLMs as "annotators" on 5 different tasks (age, gender, topic, sentiment prediction, and hate speech detection), across 4 languages: English, French, German, and Spanish. No single model excels at all tasks, across languages, or across all labels within a task. However, aggregation techniques designed for human annotators perform substantially better than any one individual model. Overall, though, LLMs do not rival even simple supervised models, so they do not (yet) replace the need for human annotation. We also discuss the tradeoffs between speed, accuracy, cost, and bias when it comes to aggregated model labeling versus human annotation.