 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEasily Accessible Text-to-Image Generation Amplifies Demographic Stereotypes at Large Scale
Nov 07, 2022



Machine learning models are now able to convert user-written text descriptions into naturalistic images. These models are available to anyone online and are being used to generate millions of images a day. We investigate these models and find that they amplify dangerous and complex stereotypes. Moreover, we find that the amplified stereotypes are difficult to predict and not easily mitigated by users or model owners. The extent to which these image-generation models perpetuate and amplify stereotypes and their mass deployment is cause for serious concern.
When and why vision-language models behave like bags-of-words, and what to do about it?
Oct 06, 2022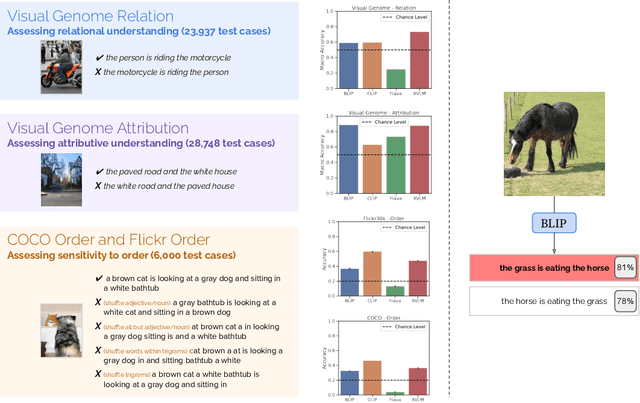

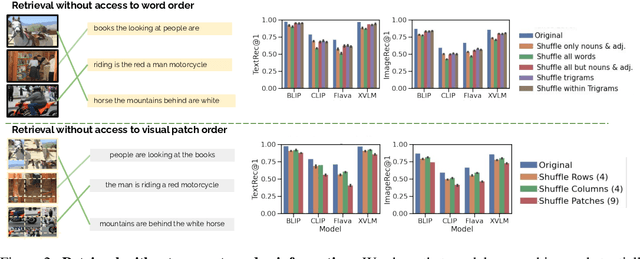
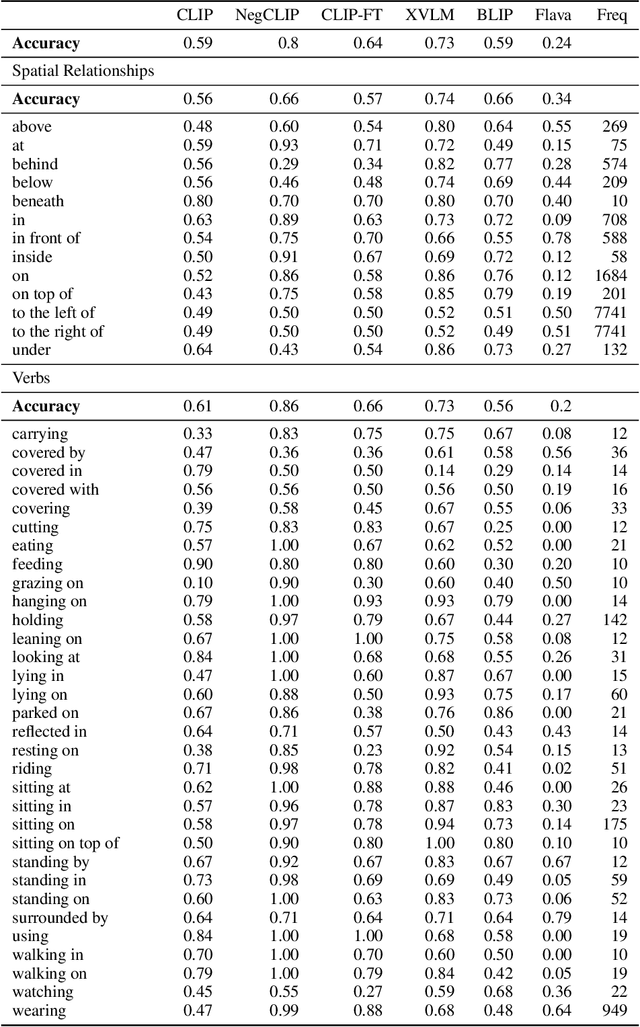
Despite the success of large vision and language models (VLMs) in many downstream applications, it is unclear how well they encode compositional information. Here, we create the Attribution, Relation, and Order (ARO) benchmark to systematically evaluate the ability of VLMs to understand different types of relationships, attributes, and order. ARO consists of Visual Genome Attribution, to test the understanding of objects' properties; Visual Genome Relation, to test for relational understanding; and COCO & Flickr30k-Order, to test for order sensitivity. ARO is orders of magnitude larger than previous benchmarks of compositionality, with more than 50,000 test cases. We show where state-of-the-art VLMs have poor relational understanding, can blunder when linking objects to their attributes, and demonstrate a severe lack of order sensitivity. VLMs are predominantly trained and evaluated on large datasets with rich compositional structure in the images and captions. Yet, training on these datasets has not been enough to address the lack of compositional understanding, and evaluating on these datasets has failed to surface this deficiency. To understand why these limitations emerge and are not represented in the standard tests, we zoom into the evaluation and training procedures. We demonstrate that it is possible to perform well on retrieval over existing datasets without using the composition and order information. Given that contrastive pretraining optimizes for retrieval on datasets with similar shortcuts, we hypothesize that this can explain why the models do not need to learn to represent compositional information. This finding suggests a natural solution: composition-aware hard negative mining. We show that a simple-to-implement modification of contrastive learning significantly improves the performance on tasks requiring understanding of order and compositionality.
On the Opportunities and Risks of Foundation Models
Aug 18, 2021



AI is undergoing a paradigm shift with the rise of models (e.g., BERT, DALL-E, GPT-3) that are trained on broad data at scale and are adaptable to a wide range of downstream tasks. We call these models foundation models to underscore their critically central yet incomplete character. This report provides a thorough account of the opportunities and risks of foundation models, ranging from their capabilities (e.g., language, vision, robotics, reasoning, human interaction) and technical principles(e.g., model architectures, training procedures, data, systems, security, evaluation, theory) to their applications (e.g., law, healthcare, education) and societal impact (e.g., inequity, misuse, economic and environmental impact, legal and ethical considerations). Though foundation models are based on standard deep learning and transfer learning, their scale results in new emergent capabilities,and their effectiveness across so many tasks incentivizes homogenization. Homogenization provides powerful leverage but demands caution, as the defects of the foundation model are inherited by all the adapted models downstream. Despite the impending widespread deployment of foundation models, we currently lack a clear understanding of how they work, when they fail, and what they are even capable of due to their emergent properties. To tackle these questions, we believe much of the critical research on foundation models will require deep interdisciplinary collaboration commensurate with their fundamentally sociotechnical nature.
The Values Encoded in Machine Learning Research
Jun 29, 2021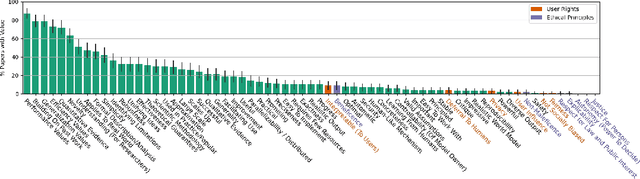


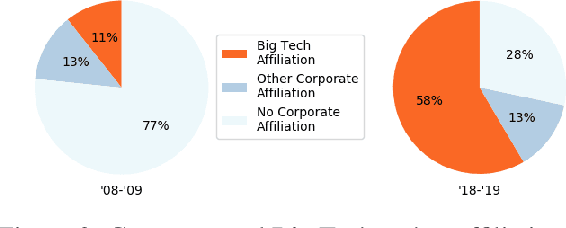
Machine learning (ML) currently exerts an outsized influence on the world, increasingly affecting communities and institutional practices. It is therefore critical that we question vague conceptions of the field as value-neutral or universally beneficial, and investigate what specific values the field is advancing. In this paper, we present a rigorous examination of the values of the field by quantitatively and qualitatively analyzing 100 highly cited ML papers published at premier ML conferences, ICML and NeurIPS. We annotate key features of papers which reveal their values: how they justify their choice of project, which aspects they uplift, their consideration of potential negative consequences, and their institutional affiliations and funding sources. We find that societal needs are typically very loosely connected to the choice of project, if mentioned at all, and that consideration of negative consequences is extremely rare. We identify 67 values that are uplifted in machine learning research, and, of these, we find that papers most frequently justify and assess themselves based on performance, generalization, efficiency, researcher understanding, novelty, and building on previous work. We present extensive textual evidence and analysis of how these values are operationalized. Notably, we find that each of these top values is currently being defined and applied with assumptions and implications generally supporting the centralization of power. Finally, we find increasingly close ties between these highly cited papers and tech companies and elite universities.
Learning Controllable Fair Representations
Dec 11, 2018
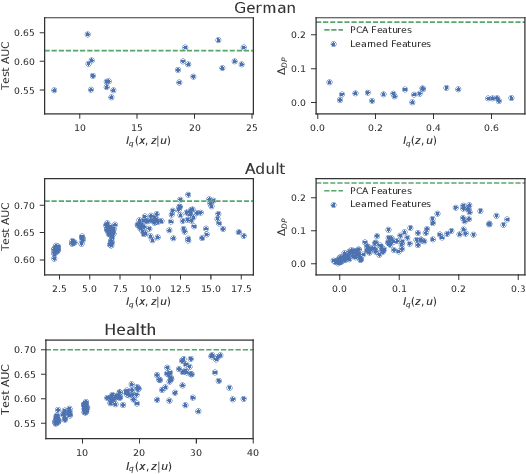
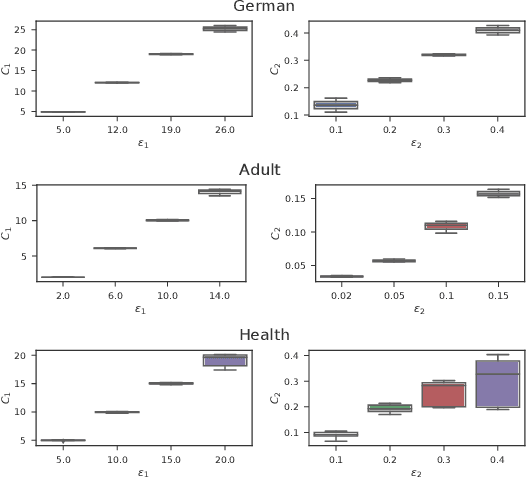
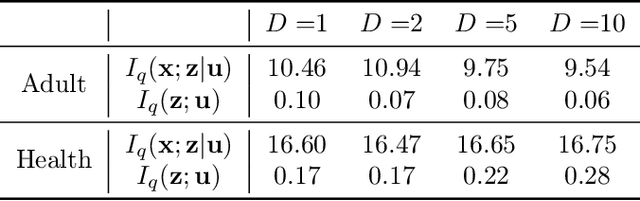
Learning data representations that are transferable and fair with respect to certain protected attributes is crucial to reducing unfair decisions made downstream, while preserving the utility of the data. We propose an information-theoretically motivated objective for learning maximally expressive representations subject to fairness constraints. We demonstrate that a range of existing approaches optimize approximations to the Lagrangian dual of our objective. In contrast to these existing approaches, our objective provides the user control over the fairness of representations by specifying limits on unfairness. We introduce a dual optimization method that optimizes the model as well as the expressiveness-fairness trade-off. Empirical evidence suggests that our proposed method can account for multiple notions of fairness and achieves higher expressiveness at a lower computational cost.