 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen and why vision-language models behave like bags-of-words, and what to do about it?
Paper and Code
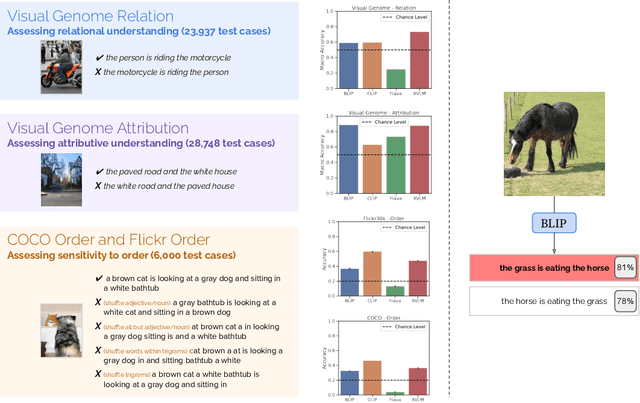

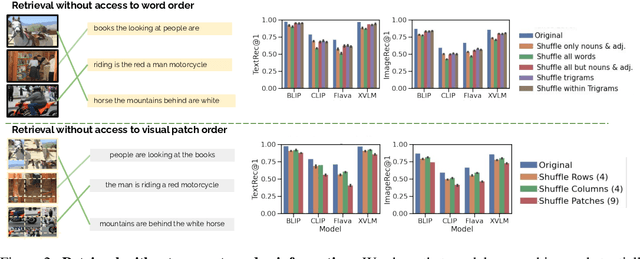
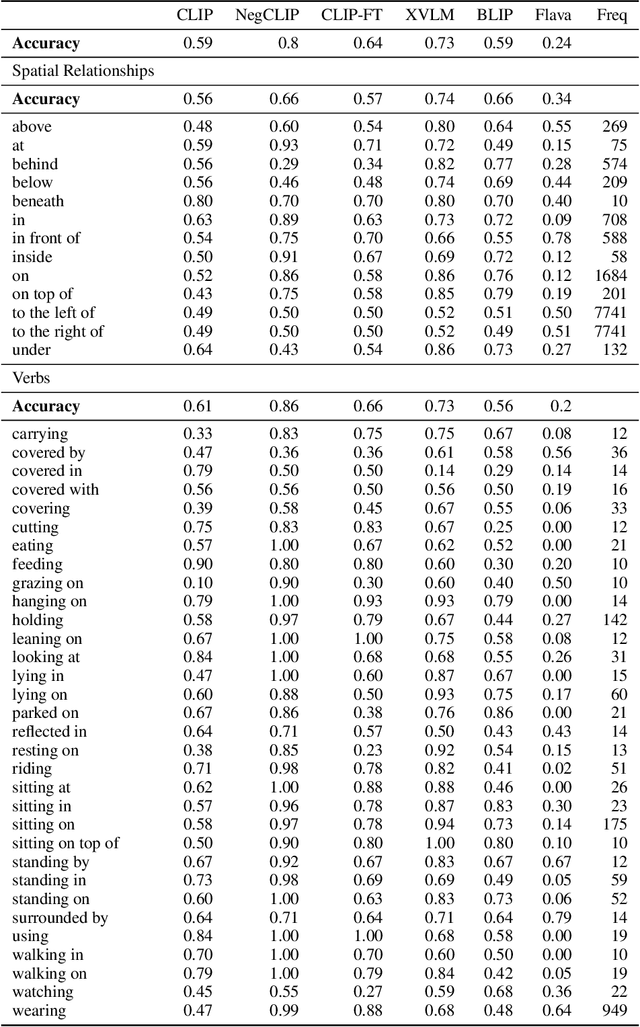
Despite the success of large vision and language models (VLMs) in many downstream applications, it is unclear how well they encode compositional information. Here, we create the Attribution, Relation, and Order (ARO) benchmark to systematically evaluate the ability of VLMs to understand different types of relationships, attributes, and order. ARO consists of Visual Genome Attribution, to test the understanding of objects' properties; Visual Genome Relation, to test for relational understanding; and COCO & Flickr30k-Order, to test for order sensitivity. ARO is orders of magnitude larger than previous benchmarks of compositionality, with more than 50,000 test cases. We show where state-of-the-art VLMs have poor relational understanding, can blunder when linking objects to their attributes, and demonstrate a severe lack of order sensitivity. VLMs are predominantly trained and evaluated on large datasets with rich compositional structure in the images and captions. Yet, training on these datasets has not been enough to address the lack of compositional understanding, and evaluating on these datasets has failed to surface this deficiency. To understand why these limitations emerge and are not represented in the standard tests, we zoom into the evaluation and training procedures. We demonstrate that it is possible to perform well on retrieval over existing datasets without using the composition and order information. Given that contrastive pretraining optimizes for retrieval on datasets with similar shortcuts, we hypothesize that this can explain why the models do not need to learn to represent compositional information. This finding suggests a natural solution: composition-aware hard negative mining. We show that a simple-to-implement modification of contrastive learning significantly improves the performance on tasks requiring understanding of order and compositionality.