 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Counter Narrative Type Classification
Paper and Code
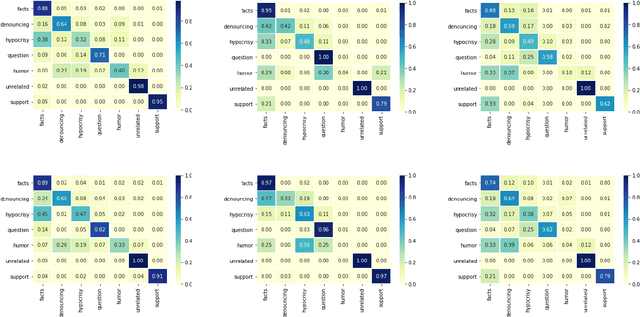

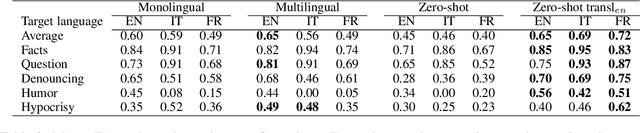

The growing interest in employing counter narratives for hatred intervention brings with it a focus on dataset creation and automation strategies. In this scenario, learning to recognize counter narrative types from natural text is expected to be useful for applications such as hate speech countering, where operators from non-governmental organizations are supposed to answer to hate with several and diverse arguments that can be mined from online sources. This paper presents the first multilingual work on counter narrative type classification, evaluating SoTA pre-trained language models in monolingual, multilingual and cross-lingual settings. When considering a fine-grained annotation of counter narrative classes, we report strong baseline classification results for the majority of the counter narrative types, especially if we translate every language to English before cross-lingual prediction. This suggests that knowledge about counter narratives can be successfully transferred across languages.