 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIt's a TRAP! Task-Redirecting Agent Persuasion Benchmark for Web Agents
Dec 29, 2025Web-based agents powered by large language models are increasingly used for tasks such as email management or professional networking. Their reliance on dynamic web content, however, makes them vulnerable to prompt injection attacks: adversarial instructions hidden in interface elements that persuade the agent to divert from its original task. We introduce the Task-Redirecting Agent Persuasion Benchmark (TRAP), an evaluation for studying how persuasion techniques misguide autonomous web agents on realistic tasks. Across six frontier models, agents are susceptible to prompt injection in 25\% of tasks on average (13\% for GPT-5 to 43\% for DeepSeek-R1), with small interface or contextual changes often doubling success rates and revealing systemic, psychologically driven vulnerabilities in web-based agents. We also provide a modular social-engineering injection framework with controlled experiments on high-fidelity website clones, allowing for further benchmark expansion.
LLMs Don't Know Their Own Decision Boundaries: The Unreliability of Self-Generated Counterfactual Explanations
Sep 11, 2025To collaborate effectively with humans, language models must be able to explain their decisions in natural language. We study a specific type of self-explanation: self-generated counterfactual explanations (SCEs), where a model explains its prediction by modifying the input such that it would have predicted a different outcome. We evaluate whether LLMs can produce SCEs that are valid, achieving the intended outcome, and minimal, modifying the input no more than necessary. When asked to generate counterfactuals, we find that LLMs typically produce SCEs that are valid, but far from minimal, offering little insight into their decision-making behaviour. Worryingly, when asked to generate minimal counterfactuals, LLMs typically make excessively small edits that fail to change predictions. The observed validity-minimality trade-off is consistent across several LLMs, datasets, and evaluation settings. Our findings suggest that SCEs are, at best, an ineffective explainability tool and, at worst, can provide misleading insights into model behaviour. Proposals to deploy LLMs in high-stakes settings must consider the impact of unreliable self-explanations on downstream decision-making. Our code is available at https://github.com/HarryMayne/SCEs.
Robust LLM Unlearning with MUDMAN: Meta-Unlearning with Disruption Masking And Normalization
Jun 14, 2025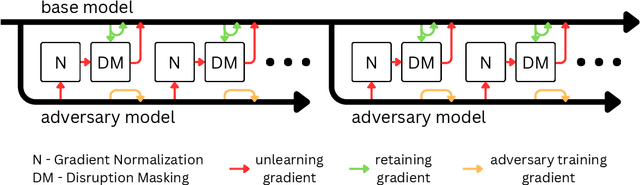
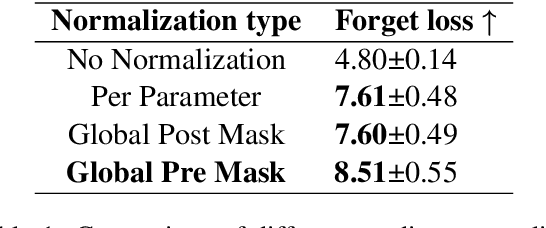
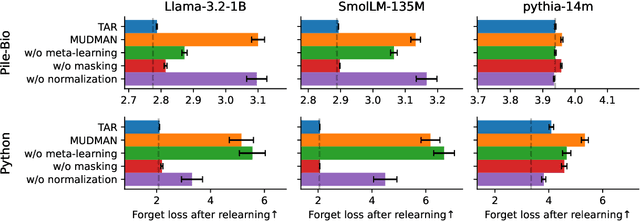
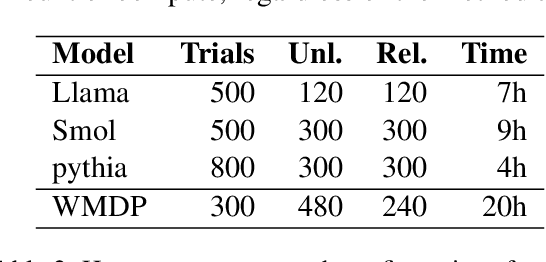
Language models can retain dangerous knowledge and skills even after extensive safety fine-tuning, posing both misuse and misalignment risks. Recent studies show that even specialized unlearning methods can be easily reversed. To address this, we systematically evaluate many existing and novel components of unlearning methods and identify ones crucial for irreversible unlearning. We introduce Disruption Masking, a technique in which we only allow updating weights, where the signs of the unlearning gradient and the retaining gradient are the same. This ensures all updates are non-disruptive. Additionally, we identify the need for normalizing the unlearning gradients, and also confirm the usefulness of meta-learning. We combine these insights into MUDMAN (Meta-Unlearning with Disruption Masking and Normalization) and validate its effectiveness at preventing the recovery of dangerous capabilities. MUDMAN outperforms the prior TAR method by 40\%, setting a new state-of-the-art for robust unlearning.
Can sparse autoencoders be used to decompose and interpret steering vectors?
Nov 13, 2024Steering vectors are a promising approach to control the behaviour of large language models. However, their underlying mechanisms remain poorly understood. While sparse autoencoders (SAEs) may offer a potential method to interpret steering vectors, recent findings show that SAE-reconstructed vectors often lack the steering properties of the original vectors. This paper investigates why directly applying SAEs to steering vectors yields misleading decompositions, identifying two reasons: (1) steering vectors fall outside the input distribution for which SAEs are designed, and (2) steering vectors can have meaningful negative projections in feature directions, which SAEs are not designed to accommodate. These limitations hinder the direct use of SAEs for interpreting steering vectors.
Ablation is Not Enough to Emulate DPO: How Neuron Dynamics Drive Toxicity Reduction
Nov 10, 2024Safety fine-tuning algorithms are commonly used to fine-tune language models to reduce harmful outputs, but the exact internal mechanisms of how those models achieve this remain unclear. In studying direct preference optimisation (DPO) for toxicity reduction, current explanations claim that DPO works by dampening the most toxic MLP neurons to learn an offset to avert toxic regions in the residual stream. However, by ablating the most toxic neurons and applying activation patching, we find this explanation incomplete. By projecting neuron activation changes onto a toxicity probe, we find that only 31.8\% of toxicity reduction comes from dampened toxic neurons. Instead, DPO reduces toxicity by accumulating effects across multiple neuron groups, both reducing writing in the toxic direction and promoting anti-toxicity in the residual stream. Moreover, DPO gives noisy adjustments to neuron activations, with many neurons actually increasing toxicity. This indicates that DPO is a balancing process between opposing neuron effects to achieve toxicity reduction.
Fine-tuning Large Language Models with Human-inspired Learning Strategies in Medical Question Answering
Aug 15, 2024



Training Large Language Models (LLMs) incurs substantial data-related costs, motivating the development of data-efficient training methods through optimised data ordering and selection. Human-inspired learning strategies, such as curriculum learning, offer possibilities for efficient training by organising data according to common human learning practices. Despite evidence that fine-tuning with curriculum learning improves the performance of LLMs for natural language understanding tasks, its effectiveness is typically assessed using a single model. In this work, we extend previous research by evaluating both curriculum-based and non-curriculum-based learning strategies across multiple LLMs, using human-defined and automated data labels for medical question answering. Our results indicate a moderate impact of using human-inspired learning strategies for fine-tuning LLMs, with maximum accuracy gains of 1.77% per model and 1.81% per dataset. Crucially, we demonstrate that the effectiveness of these strategies varies significantly across different model-dataset combinations, emphasising that the benefits of a specific human-inspired strategy for fine-tuning LLMs do not generalise. Additionally, we find evidence that curriculum learning using LLM-defined question difficulty outperforms human-defined difficulty, highlighting the potential of using model-generated measures for optimal curriculum design.