 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibrating Self-supervised Monocular Depth Estimation
Paper and Code
Sep 16, 2020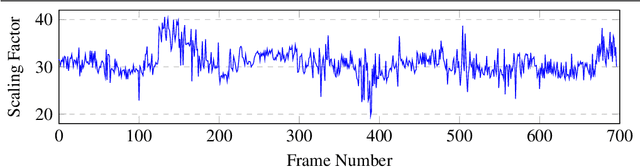

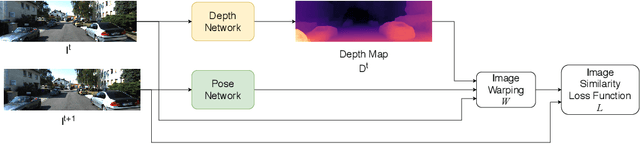
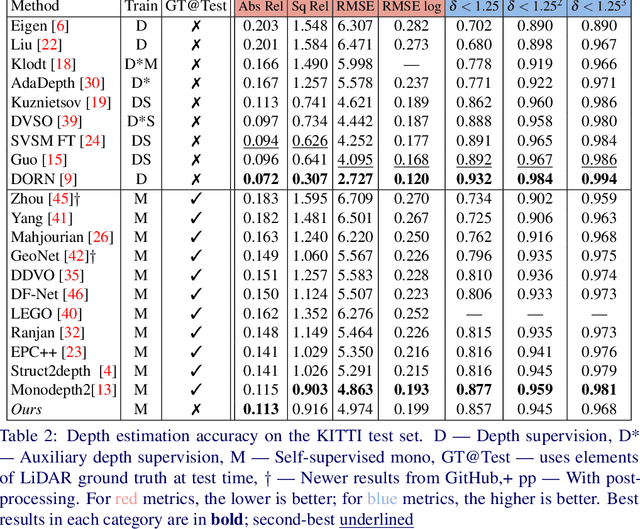
In the recent years, many methods demonstrated the ability of neural networks tolearn depth and pose changes in a sequence of images, using only self-supervision as thetraining signal. Whilst the networks achieve good performance, the often over-lookeddetail is that due to the inherent ambiguity of monocular vision they predict depth up to aunknown scaling factor. The scaling factor is then typically obtained from the LiDARground truth at test time, which severely limits practical applications of these methods.In this paper, we show that incorporating prior information about the camera configu-ration and the environment, we can remove the scale ambiguity and predict depth directly,still using the self-supervised formulation and not relying on any additional sensors.