 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREDistill: Robust Estimator Distillation for Balancing Robustness and Efficiency
Feb 04, 2026Knowledge Distillation (KD) transfers knowledge from a large teacher model to a smaller student by aligning their predictive distributions. However, conventional KD formulations - typically based on Kullback-Leibler divergence - assume that the teacher provides reliable soft targets. In practice, teacher predictions are often noisy or overconfident, and existing correction-based approaches rely on ad-hoc heuristics and extensive hyper-parameter tuning, which hinders generalization. We introduce REDistill (Robust Estimator Distillation), a simple yet principled framework grounded in robust statistics. REDistill replaces the standard KD objective with a power divergence loss, a generalization of KL divergence that adaptively downweights unreliable teacher output while preserving informative logit relationships. This formulation provides a unified and interpretable treatment of teacher noise, requires only logits, integrates seamlessly into existing KD pipelines, and incurs negligible computational overhead. Extensive experiments on CIFAR-100 and ImageNet-1k demonstrate that REDistill consistently improves student accuracy in diverse teacher-student architectures. Remarkably, it achieves these gains without model-specific hyper-parameter tuning, underscoring its robustness and strong generalization to unseen teacher-student pairs.
HyDRA: Hybrid Denoising Regularization for Measurement-Only DEQ Training
Jan 03, 2026Solving image reconstruction problems of the form \(\mathbf{A} \mathbf{x} = \mathbf{y}\) remains challenging due to ill-posedness and the lack of large-scale supervised datasets. Deep Equilibrium (DEQ) models have been used successfully but typically require supervised pairs \((\mathbf{x},\mathbf{y})\). In many practical settings, only measurements \(\mathbf{y}\) are available. We introduce HyDRA (Hybrid Denoising Regularization Adaptation), a measurement-only framework for DEQ training that combines measurement consistency with an adaptive denoising regularization term, together with a data-driven early stopping criterion. Experiments on sparse-view CT demonstrate competitive reconstruction quality and fast inference.
MonoSOWA: Scalable monocular 3D Object detector Without human Annotations
Jan 16, 2025Detecting the three-dimensional position and orientation of objects using a single RGB camera is a foundational task in computer vision with many important applications. Traditionally, 3D object detection methods are trained in a fully-supervised setup, requiring vast amounts of human annotations, which are laborious, costly, and do not scale well with the ever-increasing amounts of data being captured. In this paper, we present the first method to train 3D object detectors for monocular RGB cameras without domain-specific human annotations, thus making orders of magnitude more data available for training. Thanks to newly proposed Canonical Object Space, the method can not only exploit data across a variety of datasets and camera setups to train a single 3D detector, but unlike previous work it also works out of the box in previously unseen camera setups. All this is crucial for practical applications, where the data and cameras are extremely heterogeneous. The method is evaluated on two standard autonomous driving datasets, where it outperforms previous works, which, unlike our method, still rely on 2D human annotations.
Animal Identification with Independent Foreground and Background Modeling
Aug 23, 2024



We propose a method that robustly exploits background and foreground in visual identification of individual animals. Experiments show that their automatic separation, made easy with methods like Segment Anything, together with independent foreground and background-related modeling, improves results. The two predictions are combined in a principled way, thanks to novel Per-Instance Temperature Scaling that helps the classifier to deal with appearance ambiguities in training and to produce calibrated outputs in the inference phase. For identity prediction from the background, we propose novel spatial and temporal models. On two problems, the relative error w.r.t. the baseline was reduced by 22.3% and 8.8%, respectively. For cases where objects appear in new locations, an example of background drift, accuracy doubles.
Lifting 2D Object Locations to 3D by Discounting LiDAR Outliers across Objects and Views
Oct 09, 2021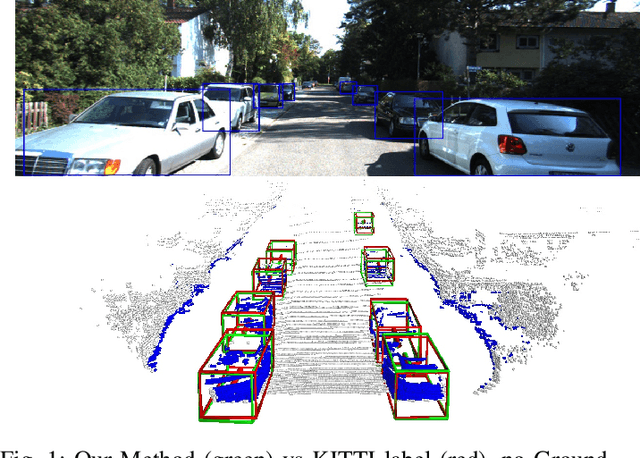
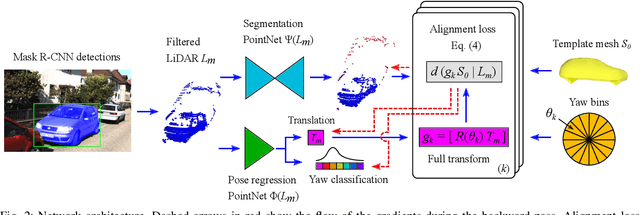


We present a system for automatic converting of 2D mask object predictions and raw LiDAR point clouds into full 3D bounding boxes of objects. Because the LiDAR point clouds are partial, directly fitting bounding boxes to the point clouds is meaningless. Instead, we suggest that obtaining good results requires sharing information between \emph{all} objects in the dataset jointly, over multiple frames. We then make three improvements to the baseline. First, we address ambiguities in predicting the object rotations via direct optimization in this space while still backpropagating rotation prediction through the model. Second, we explicitly model outliers and task the network with learning their typical patterns, thus better discounting them. Third, we enforce temporal consistency when video data is available. With these contributions, our method significantly outperforms previous work despite the fact that those methods use significantly more complex pipelines, 3D models and additional human-annotated external sources of prior information.
Real Time Monocular Vehicle Velocity Estimation using Synthetic Data
Sep 16, 2021


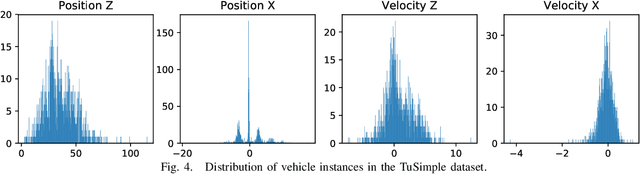
Vision is one of the primary sensing modalities in autonomous driving. In this paper we look at the problem of estimating the velocity of road vehicles from a camera mounted on a moving car. Contrary to prior methods that train end-to-end deep networks that estimate the vehicles' velocity from the video pixels, we propose a two-step approach where first an off-the-shelf tracker is used to extract vehicle bounding boxes and then a small neural network is used to regress the vehicle velocity from the tracked bounding boxes. Surprisingly, we find that this still achieves state-of-the-art estimation performance with the significant benefit of separating perception from dynamics estimation via a clean, interpretable and verifiable interface which allows us distill the statistics which are crucial for velocity estimation. We show that the latter can be used to easily generate synthetic training data in the space of bounding boxes and use this to improve the performance of our method further.
Calibrating Self-supervised Monocular Depth Estimation
Sep 16, 2020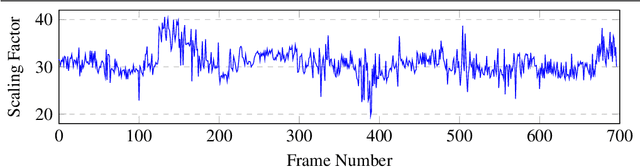

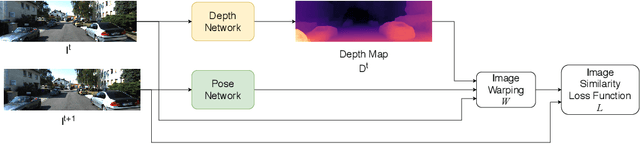
In the recent years, many methods demonstrated the ability of neural networks tolearn depth and pose changes in a sequence of images, using only self-supervision as thetraining signal. Whilst the networks achieve good performance, the often over-lookeddetail is that due to the inherent ambiguity of monocular vision they predict depth up to aunknown scaling factor. The scaling factor is then typically obtained from the LiDARground truth at test time, which severely limits practical applications of these methods.In this paper, we show that incorporating prior information about the camera configu-ration and the environment, we can remove the scale ambiguity and predict depth directly,still using the self-supervised formulation and not relying on any additional sensors.
Monocular Depth Estimation with Self-supervised Instance Adaptation
Apr 13, 2020
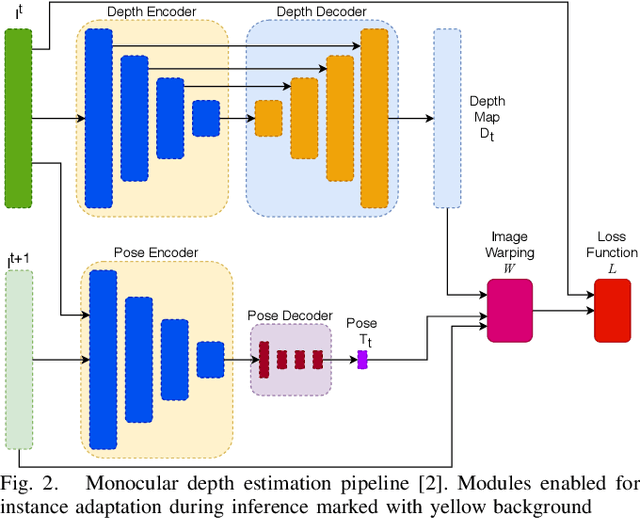
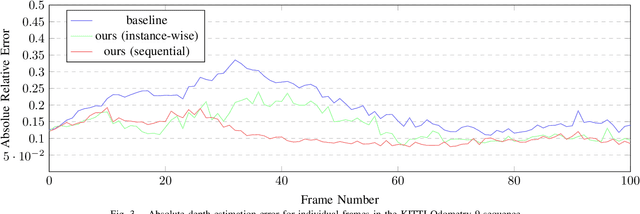
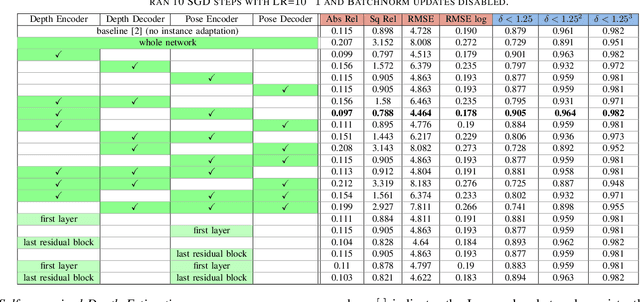
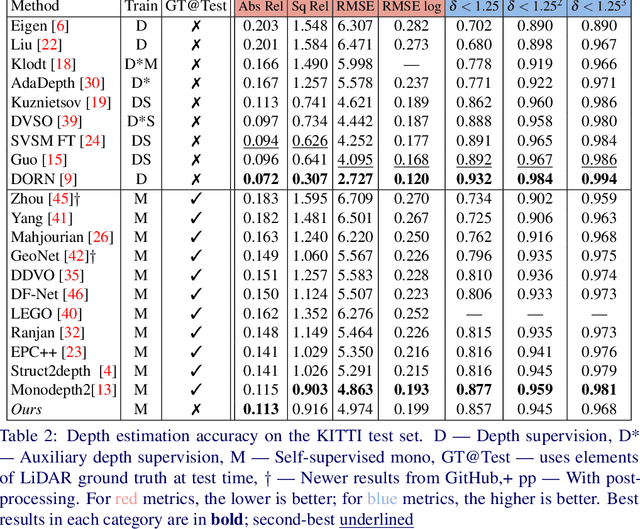
Recent advances in self-supervised learning havedemonstrated that it is possible to learn accurate monoculardepth reconstruction from raw video data, without using any 3Dground truth for supervision. However, in robotics applications,multiple views of a scene may or may not be available, depend-ing on the actions of the robot, switching between monocularand multi-view reconstruction. To address this mixed setting,we proposed a new approach that extends any off-the-shelfself-supervised monocular depth reconstruction system to usemore than one image at test time. Our method builds on astandard prior learned to perform monocular reconstruction,but uses self-supervision at test time to further improve thereconstruction accuracy when multiple images are available.When used to update the correct components of the model, thisapproach is highly-effective. On the standard KITTI bench-mark, our self-supervised method consistently outperformsall the previous methods with an average 25% reduction inabsolute error for the three common setups (monocular, stereoand monocular+stereo), and comes very close in accuracy whencompared to the fully-supervised state-of-the-art methods.
COCO-Text: Dataset and Benchmark for Text Detection and Recognition in Natural Images
Jun 19, 2016

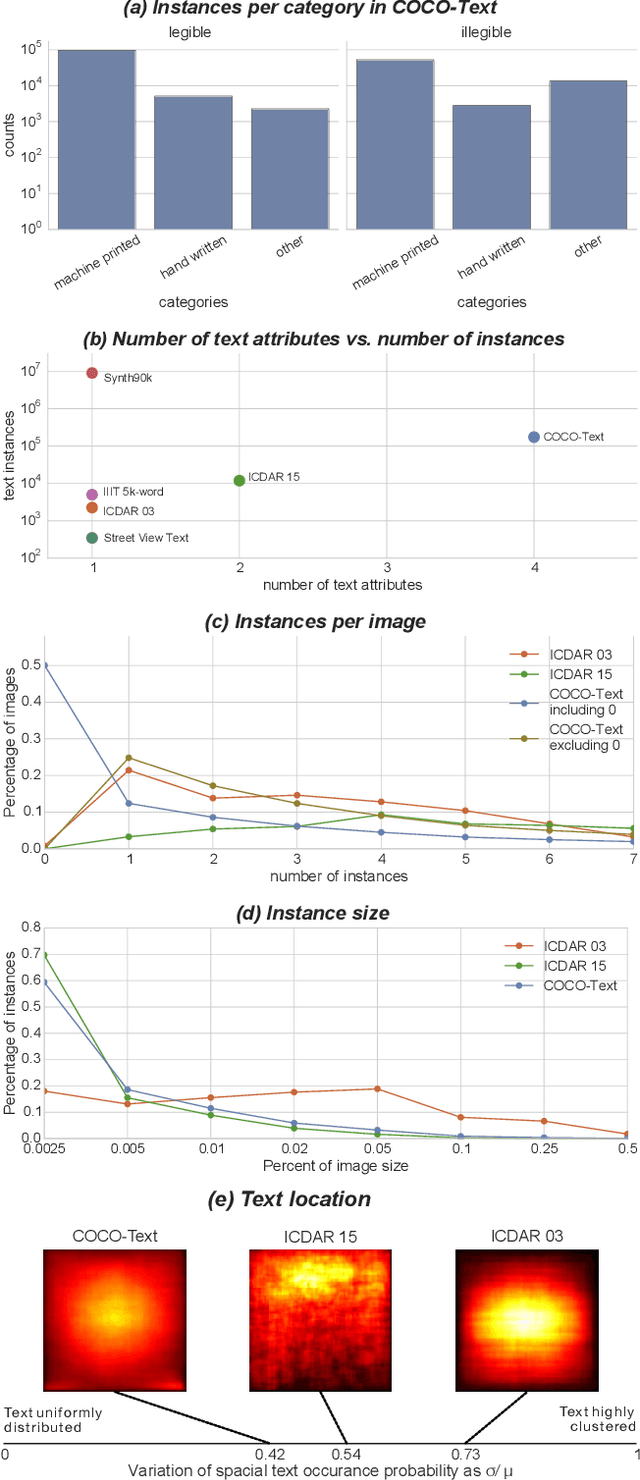
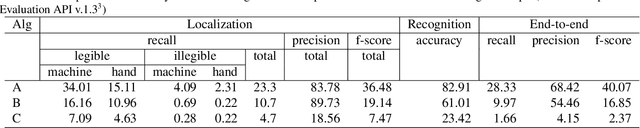
This paper describes the COCO-Text dataset. In recent years large-scale datasets like SUN and Imagenet drove the advancement of scene understanding and object recognition. The goal of COCO-Text is to advance state-of-the-art in text detection and recognition in natural images. The dataset is based on the MS COCO dataset, which contains images of complex everyday scenes. The images were not collected with text in mind and thus contain a broad variety of text instances. To reflect the diversity of text in natural scenes, we annotate text with (a) location in terms of a bounding box, (b) fine-grained classification into machine printed text and handwritten text, (c) classification into legible and illegible text, (d) script of the text and (e) transcriptions of legible text. The dataset contains over 173k text annotations in over 63k images. We provide a statistical analysis of the accuracy of our annotations. In addition, we present an analysis of three leading state-of-the-art photo Optical Character Recognition (OCR) approaches on our dataset. While scene text detection and recognition enjoys strong advances in recent years, we identify significant shortcomings motivating future work.