 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-based Real Estate Price Estimation
Oct 03, 2018



Since the advent of online real estate database companies like Zillow, Trulia and Redfin, the problem of automatic estimation of market values for houses has received considerable attention. Several real estate websites provide such estimates using a proprietary formula. Although these estimates are often close to the actual sale prices, in some cases they are highly inaccurate. One of the key factors that affects the value of a house is its interior and exterior appearance, which is not considered in calculating automatic value estimates. In this paper, we evaluate the impact of visual characteristics of a house on its market value. Using deep convolutional neural networks on a large dataset of photos of home interiors and exteriors, we develop a method for estimating the luxury level of real estate photos. We also develop a novel framework for automated value assessment using the above photos in addition to home characteristics including size, offered price and number of bedrooms. Finally, by applying our proposed method for price estimation to a new dataset of real estate photos and metadata, we show that it outperforms Zillow's estimates.
COCO-Text: Dataset and Benchmark for Text Detection and Recognition in Natural Images
Jun 19, 2016

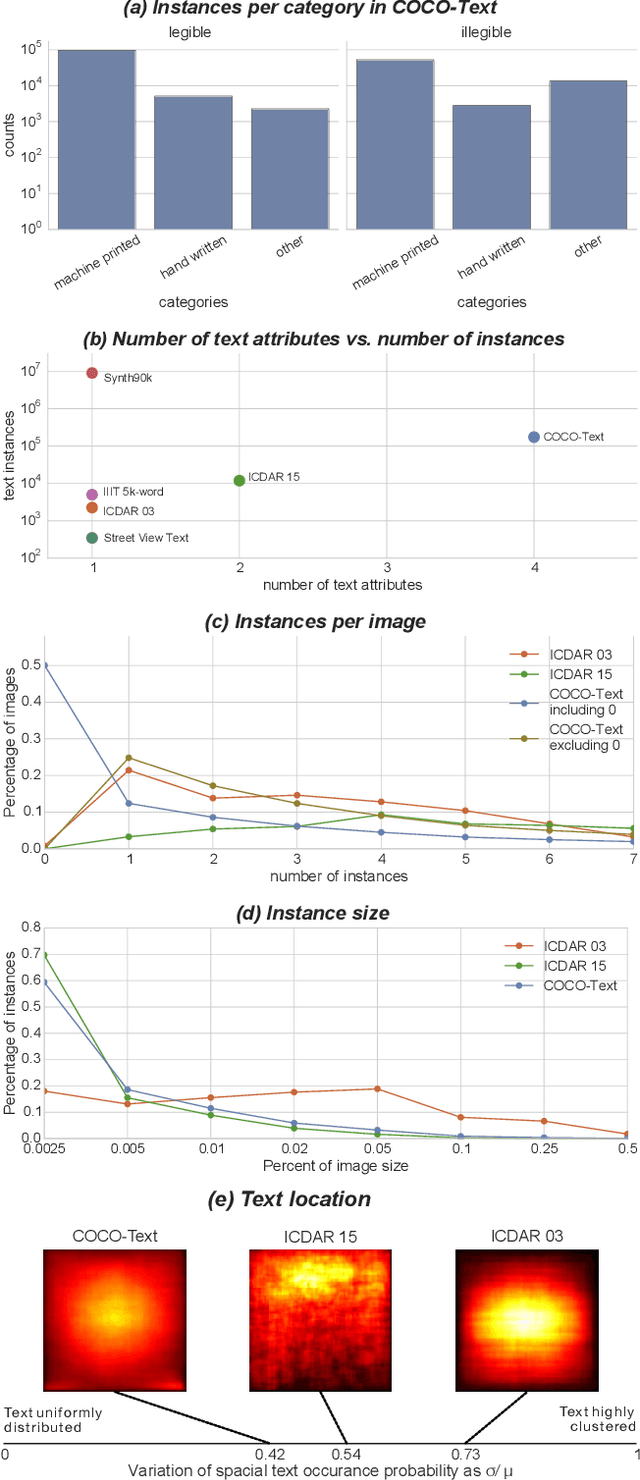
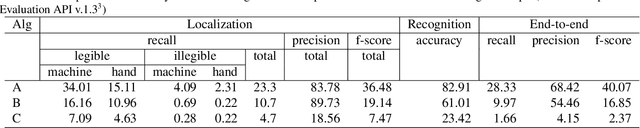
This paper describes the COCO-Text dataset. In recent years large-scale datasets like SUN and Imagenet drove the advancement of scene understanding and object recognition. The goal of COCO-Text is to advance state-of-the-art in text detection and recognition in natural images. The dataset is based on the MS COCO dataset, which contains images of complex everyday scenes. The images were not collected with text in mind and thus contain a broad variety of text instances. To reflect the diversity of text in natural scenes, we annotate text with (a) location in terms of a bounding box, (b) fine-grained classification into machine printed text and handwritten text, (c) classification into legible and illegible text, (d) script of the text and (e) transcriptions of legible text. The dataset contains over 173k text annotations in over 63k images. We provide a statistical analysis of the accuracy of our annotations. In addition, we present an analysis of three leading state-of-the-art photo Optical Character Recognition (OCR) approaches on our dataset. While scene text detection and recognition enjoys strong advances in recent years, we identify significant shortcomings motivating future work.