 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLifting 2D Object Locations to 3D by Discounting LiDAR Outliers across Objects and Views
Paper and Code
Oct 09, 2021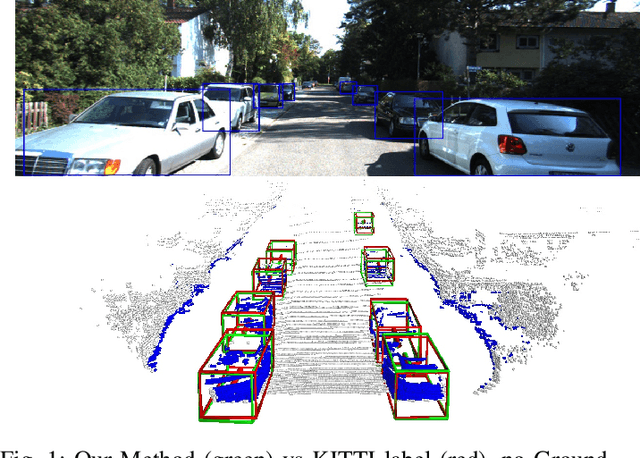
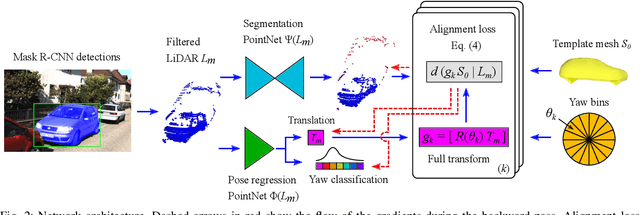


We present a system for automatic converting of 2D mask object predictions and raw LiDAR point clouds into full 3D bounding boxes of objects. Because the LiDAR point clouds are partial, directly fitting bounding boxes to the point clouds is meaningless. Instead, we suggest that obtaining good results requires sharing information between \emph{all} objects in the dataset jointly, over multiple frames. We then make three improvements to the baseline. First, we address ambiguities in predicting the object rotations via direct optimization in this space while still backpropagating rotation prediction through the model. Second, we explicitly model outliers and task the network with learning their typical patterns, thus better discounting them. Third, we enforce temporal consistency when video data is available. With these contributions, our method significantly outperforms previous work despite the fact that those methods use significantly more complex pipelines, 3D models and additional human-annotated external sources of prior information.