 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTracing Influence at Scale: A Contrastive Learning Approach to Linking Public Comments and Regulator Responses
Nov 24, 2023U.S. Federal Regulators receive over one million comment letters each year from businesses, interest groups, and members of the public, all advocating for changes to proposed regulations. These comments are believed to have wide-ranging impacts on public policy. However, measuring the impact of specific comments is challenging because regulators are required to respond to comments but they do not have to specify which comments they are addressing. In this paper, we propose a simple yet effective solution to this problem by using an iterative contrastive method to train a neural model aiming for matching text from public comments to responses written by regulators. We demonstrate that our proposal substantially outperforms a set of selected text-matching baselines on a human-annotated test set. Furthermore, it delivers performance comparable to the most advanced gigantic language model (i.e., GPT-4), and is more cost-effective when handling comments and regulator responses matching in larger scale.
Improving Context Modeling in Neural Topic Segmentation
Oct 07, 2020
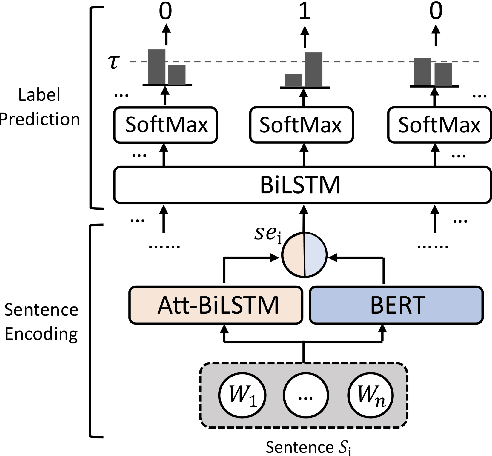
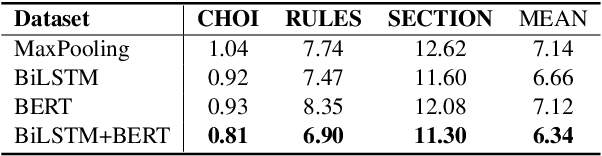
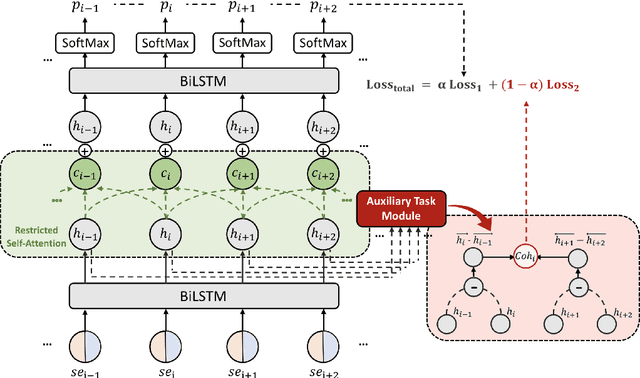
Topic segmentation is critical in key NLP tasks and recent works favor highly effective neural supervised approaches. However, current neural solutions are arguably limited in how they model context. In this paper, we enhance a segmenter based on a hierarchical attention BiLSTM network to better model context, by adding a coherence-related auxiliary task and restricted self-attention. Our optimized segmenter outperforms SOTA approaches when trained and tested on three datasets. We also the robustness of our proposed model in domain transfer setting by training a model on a large-scale dataset and testing it on four challenging real-world benchmarks. Furthermore, we apply our proposed strategy to two other languages (German and Chinese), and show its effectiveness in multilingual scenarios.