 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHypersim: A Photorealistic Synthetic Dataset for Holistic Indoor Scene Understanding
Paper and Code

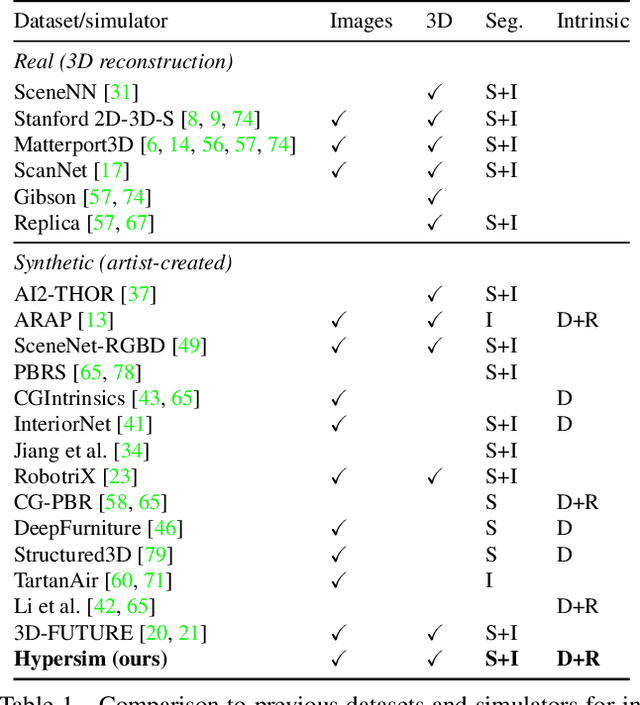
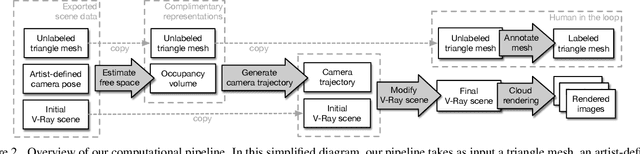

For many fundamental scene understanding tasks, it is difficult or impossible to obtain per-pixel ground truth labels from real images. We address this challenge by introducing Hypersim, a photorealistic synthetic dataset for holistic indoor scene understanding. To create our dataset, we leverage a large repository of synthetic scenes created by professional artists, and we generate 77,400 images of 461 indoor scenes with detailed per-pixel labels and corresponding ground truth geometry. Our dataset: (1) relies exclusively on publicly available 3D assets; (2) includes complete scene geometry, material information, and lighting information for every scene; (3) includes dense per-pixel semantic instance segmentations for every image; and (4) factors every image into diffuse reflectance, diffuse illumination, and a non-diffuse residual term that captures view-dependent lighting effects. Together, these features make our dataset well-suited for geometric learning problems that require direct 3D supervision, multi-task learning problems that require reasoning jointly over multiple input and output modalities, and inverse rendering problems. We analyze our dataset at the level of scenes, objects, and pixels, and we analyze costs in terms of money, annotation effort, and computation time. Remarkably, we find that it is possible to generate our entire dataset from scratch, for roughly half the cost of training a state-of-the-art natural language processing model. All the code we used to generate our dataset will be made available online.