 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen AI Eats Itself: On the Caveats of Data Pollution in the Era of Generative AI
Paper and Code
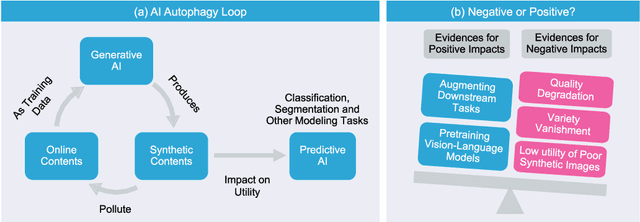
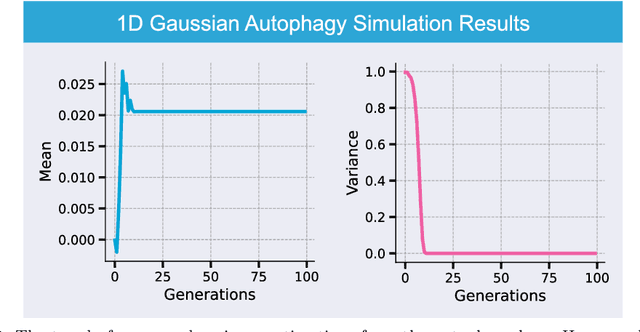
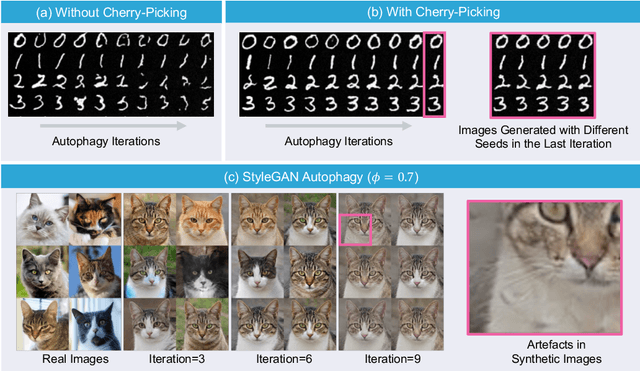

Generative artificial intelligence (AI) technologies and large models are producing realistic outputs across various domains, such as images, text, speech, and music. Creating these advanced generative models requires significant resources, particularly large and high-quality datasets. To minimize training expenses, many algorithm developers use data created by the models themselves as a cost-effective training solution. However, not all synthetic data effectively improve model performance, necessitating a strategic balance in the use of real versus synthetic data to optimize outcomes. Currently, the previously well-controlled integration of real and synthetic data is becoming uncontrollable. The widespread and unregulated dissemination of synthetic data online leads to the contamination of datasets traditionally compiled through web scraping, now mixed with unlabeled synthetic data. This trend portends a future where generative AI systems may increasingly rely blindly on consuming self-generated data, raising concerns about model performance and ethical issues. What will happen if generative AI continuously consumes itself without discernment? What measures can we take to mitigate the potential adverse effects? There is a significant gap in the scientific literature regarding the impact of synthetic data use in generative AI, particularly in terms of the fusion of multimodal information. To address this research gap, this review investigates the consequences of integrating synthetic data blindly on training generative AI on both image and text modalities and explores strategies to mitigate these effects. The goal is to offer a comprehensive view of synthetic data's role, advocating for a balanced approach to its use and exploring practices that promote the sustainable development of generative AI technologies in the era of large models.