 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContexts are Never Long Enough: Structured Reasoning for Scalable Question Answering over Long Document Sets
Apr 24, 2026Real-world document question answering is challenging. Analysts must synthesize evidence across multiple documents and different parts of each document. However, any fixed LLM context window can be exceeded as document collections grow. A common workaround is to decompose documents into chunks and assemble answers from chunk-level outputs, but this introduces an aggregation bottleneck: as the number of chunks grows, systems must still combine and reason over an increasingly large body of extracted evidence. We present SLIDERS, a framework for question answering over long document collections through structured reasoning. SLIDERS extracts salient information into a relational database, enabling scalable reasoning over persistent structured state via SQL rather than concatenated text. To make this locally extracted representation globally coherent, SLIDERS introduces a data reconciliation stage that leverages provenance, extraction rationales, and metadata to detect and repair duplicated, inconsistent, and incomplete records. SLIDERS outperforms all baselines on three existing long-context benchmarks, despite all of them fitting within the context window of strong base LLMs, exceeding GPT-4.1 by 6.6 points on average. It also improves over the next best baseline by ~19 and ~32 points on two new benchmarks at 3.9M and 36M tokens, respectively.
LLM-Based Open-Domain Integrated Task and Knowledge Assistants with Programmable Policies
Jul 08, 2024



Programming LLM-based knowledge and task assistants that faithfully conform to developer-provided policies is challenging. These agents must retrieve and provide consistent, accurate, and relevant information to address user's queries and needs. Yet such agents generate unfounded responses ("hallucinate"). Traditional dialogue trees can only handle a limited number of conversation flows, making them inherently brittle. To this end, we present KITA - a programmable framework for creating task-oriented conversational agents that are designed to handle complex user interactions. Unlike LLMs, KITA provides reliable grounded responses, with controllable agent policies through its expressive specification, KITA Worksheet. In contrast to dialog trees, it is resilient to diverse user queries, helpful with knowledge sources, and offers ease of programming policies through its declarative paradigm. Through a real-user study involving 62 participants, we show that KITA beats the GPT-4 with function calling baseline by 26.1, 22.5, and 52.4 points on execution accuracy, dialogue act accuracy, and goal completion rate, respectively. We also release 22 real-user conversations with KITA manually corrected to ensure accuracy.
FLAME: A small language model for spreadsheet formulas
Jan 31, 2023



The widespread use of spreadsheet environments by billions of users presents a unique opportunity for formula-authoring assistance. Although large language models, such as Codex, can assist in general-purpose languages, they are expensive to train and challenging to deploy due to their large model sizes (up to billions of parameters). Moreover, they require hundreds of gigabytes of training data. We present FLAME, a T5-based model trained on Excel formulas that leverages domain insights to achieve competitive performance with a substantially smaller model (60M parameters) and two orders of magnitude less training data. We curate a training dataset using sketch deduplication, introduce an Excel-specific formula tokenizer for our model, and use domain-specific versions of masked span prediction and noisy auto-encoding as pretraining objectives. We evaluate FLAME on formula repair, formula auto-completion, and a novel task called syntax reconstruction. FLAME (60M) can outperform much larger models, such as Codex-Davinci (175B), Codex-Cushman (12B), and CodeT5 (220M), in 6 out of 10 settings.
Repair Is Nearly Generation: Multilingual Program Repair with LLMs
Aug 24, 2022
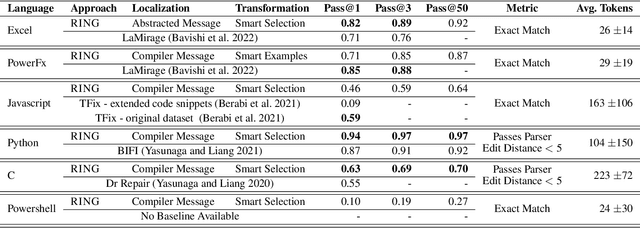

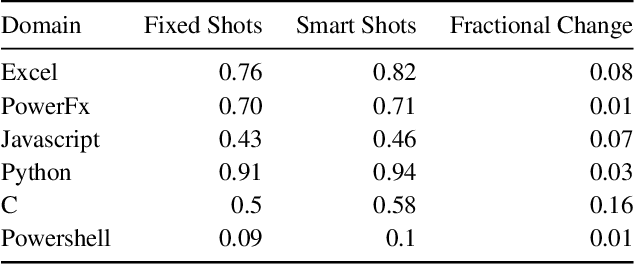
Most programmers make mistakes when writing code. Some of these mistakes are small and require few edits to the original program - a class of errors recently termed last mile mistakes. These errors break the flow for experienced developers and can stump novice programmers. Existing automated repair techniques targeting this class of errors are domain-specific and do not easily carry over to new domains. Transferring symbolic approaches requires substantial engineering and neural approaches require data and retraining. We introduce RING, a multilingual repair engine powered by a large language model trained on code (LLMC) such as Codex. Such a multilingual engine enables a flipped model for programming assistance, one where the programmer writes code and the AI assistance suggests fixes, compared to traditional code suggestion technology. Taking inspiration from the way programmers manually fix bugs, we show that a prompt-based strategy that conceptualizes repair as localization, transformation, and candidate ranking, can successfully repair programs in multiple domains with minimal effort. We present the first results for such a multilingual repair engine by evaluating on 6 different domains and comparing performance to domain-specific repair engines. We show that RING can outperform domain-specific repair engines in 3 of these domains. We also identify directions for future research using LLMCs for multilingual repair.
Neurosymbolic Repair for Low-Code Formula Languages
Jul 24, 2022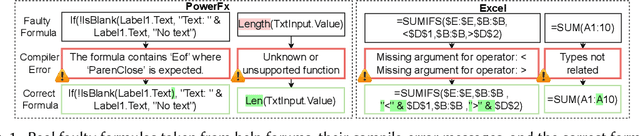
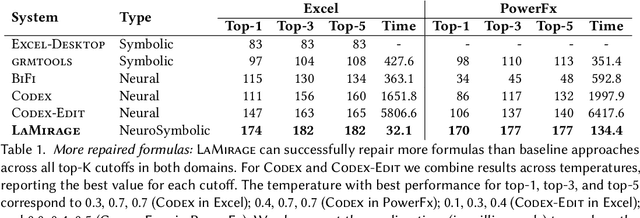

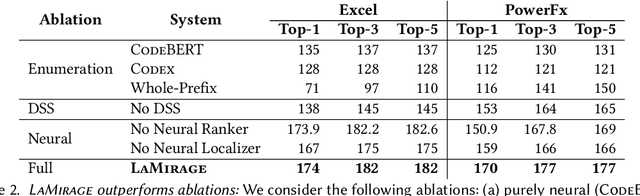
Most users of low-code platforms, such as Excel and PowerApps, write programs in domain-specific formula languages to carry out nontrivial tasks. Often users can write most of the program they want, but introduce small mistakes that yield broken formulas. These mistakes, which can be both syntactic and semantic, are hard for low-code users to identify and fix, even though they can be resolved with just a few edits. We formalize the problem of producing such edits as the last-mile repair problem. To address this problem, we developed LaMirage, a LAst-MIle RepAir-engine GEnerator that combines symbolic and neural techniques to perform last-mile repair in low-code formula languages. LaMirage takes a grammar and a set of domain-specific constraints/rules, which jointly approximate the target language, and uses these to generate a repair engine that can fix formulas in that language. To tackle the challenges of localizing the errors and ranking the candidate repairs, LaMirage leverages neural techniques, whereas it relies on symbolic methods to generate candidate repairs. This combination allows LaMirage to find repairs that satisfy the provided grammar and constraints, and then pick the most natural repair. We compare LaMirage to state-of-the-art neural and symbolic approaches on 400 real Excel and PowerFx formulas, where LaMirage outperforms all baselines. We release these benchmarks to encourage subsequent work in low-code domains.