 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepair Is Nearly Generation: Multilingual Program Repair with LLMs
Aug 24, 2022
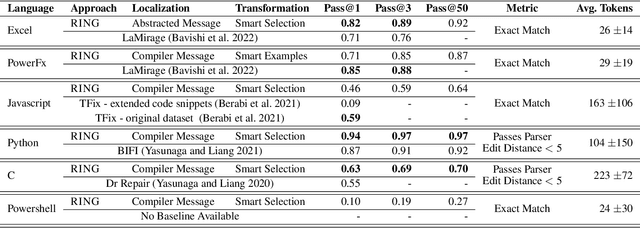

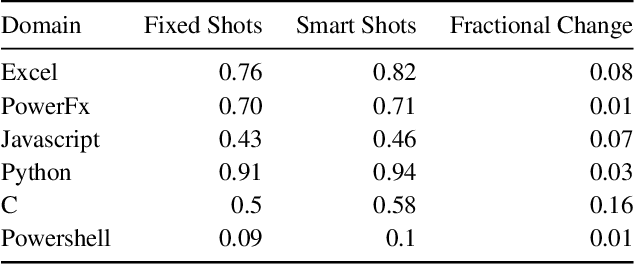
Most programmers make mistakes when writing code. Some of these mistakes are small and require few edits to the original program - a class of errors recently termed last mile mistakes. These errors break the flow for experienced developers and can stump novice programmers. Existing automated repair techniques targeting this class of errors are domain-specific and do not easily carry over to new domains. Transferring symbolic approaches requires substantial engineering and neural approaches require data and retraining. We introduce RING, a multilingual repair engine powered by a large language model trained on code (LLMC) such as Codex. Such a multilingual engine enables a flipped model for programming assistance, one where the programmer writes code and the AI assistance suggests fixes, compared to traditional code suggestion technology. Taking inspiration from the way programmers manually fix bugs, we show that a prompt-based strategy that conceptualizes repair as localization, transformation, and candidate ranking, can successfully repair programs in multiple domains with minimal effort. We present the first results for such a multilingual repair engine by evaluating on 6 different domains and comparing performance to domain-specific repair engines. We show that RING can outperform domain-specific repair engines in 3 of these domains. We also identify directions for future research using LLMCs for multilingual repair.
Neurosymbolic Repair for Low-Code Formula Languages
Jul 24, 2022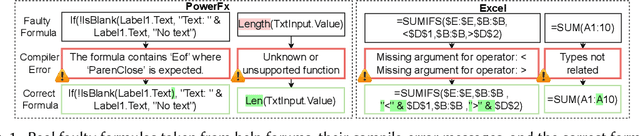
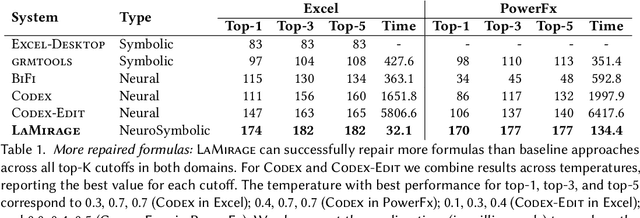

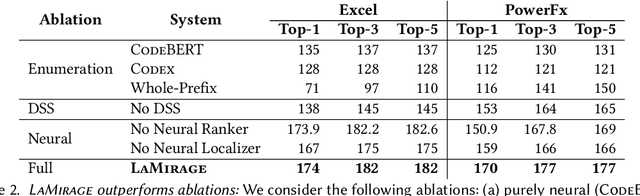
Most users of low-code platforms, such as Excel and PowerApps, write programs in domain-specific formula languages to carry out nontrivial tasks. Often users can write most of the program they want, but introduce small mistakes that yield broken formulas. These mistakes, which can be both syntactic and semantic, are hard for low-code users to identify and fix, even though they can be resolved with just a few edits. We formalize the problem of producing such edits as the last-mile repair problem. To address this problem, we developed LaMirage, a LAst-MIle RepAir-engine GEnerator that combines symbolic and neural techniques to perform last-mile repair in low-code formula languages. LaMirage takes a grammar and a set of domain-specific constraints/rules, which jointly approximate the target language, and uses these to generate a repair engine that can fix formulas in that language. To tackle the challenges of localizing the errors and ranking the candidate repairs, LaMirage leverages neural techniques, whereas it relies on symbolic methods to generate candidate repairs. This combination allows LaMirage to find repairs that satisfy the provided grammar and constraints, and then pick the most natural repair. We compare LaMirage to state-of-the-art neural and symbolic approaches on 400 real Excel and PowerFx formulas, where LaMirage outperforms all baselines. We release these benchmarks to encourage subsequent work in low-code domains.
Programming by Rewards
Jul 14, 2020



We formalize and study ``programming by rewards'' (PBR), a new approach for specifying and synthesizing subroutines for optimizing some quantitative metric such as performance, resource utilization, or correctness over a benchmark. A PBR specification consists of (1) input features $x$, and (2) a reward function $r$, modeled as a black-box component (which we can only run), that assigns a reward for each execution. The goal of the synthesizer is to synthesize a "decision function" $f$ which transforms the features to a decision value for the black-box component so as to maximize the expected reward $E[r \circ f (x)]$ for executing decisions $f(x)$ for various values of $x$. We consider a space of decision functions in a DSL of loop-free if-then-else programs, which can branch on linear functions of the input features in a tree-structure and compute a linear function of the inputs in the leaves of the tree. We find that this DSL captures decision functions that are manually written in practice by programmers. Our technical contribution is the use of continuous-optimization techniques to perform synthesis of such decision functions as if-then-else programs. We also show that the framework is theoretically-founded ---in cases when the rewards satisfy nice properties, the synthesized code is optimal in a precise sense. We have leveraged PBR to synthesize non-trivial decision functions related to search and ranking heuristics in the PROSE codebase (an industrial strength program synthesis framework) and achieve competitive results to manually written procedures over multiple man years of tuning. We present empirical evaluation against other baseline techniques over real-world case studies (including PROSE) as well on simple synthetic benchmarks.