 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeurosymbolic Repair for Low-Code Formula Languages
Jul 24, 2022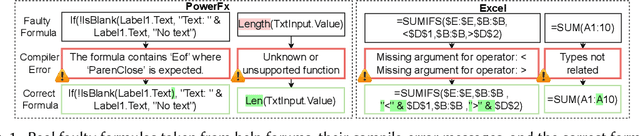
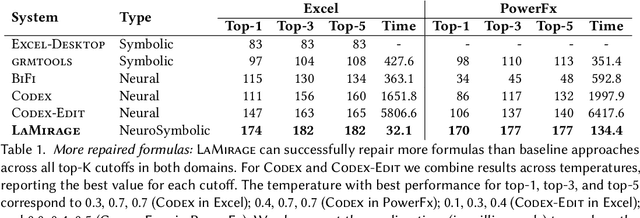

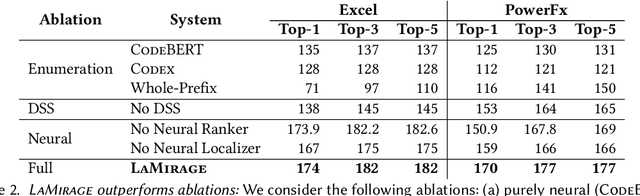
Most users of low-code platforms, such as Excel and PowerApps, write programs in domain-specific formula languages to carry out nontrivial tasks. Often users can write most of the program they want, but introduce small mistakes that yield broken formulas. These mistakes, which can be both syntactic and semantic, are hard for low-code users to identify and fix, even though they can be resolved with just a few edits. We formalize the problem of producing such edits as the last-mile repair problem. To address this problem, we developed LaMirage, a LAst-MIle RepAir-engine GEnerator that combines symbolic and neural techniques to perform last-mile repair in low-code formula languages. LaMirage takes a grammar and a set of domain-specific constraints/rules, which jointly approximate the target language, and uses these to generate a repair engine that can fix formulas in that language. To tackle the challenges of localizing the errors and ranking the candidate repairs, LaMirage leverages neural techniques, whereas it relies on symbolic methods to generate candidate repairs. This combination allows LaMirage to find repairs that satisfy the provided grammar and constraints, and then pick the most natural repair. We compare LaMirage to state-of-the-art neural and symbolic approaches on 400 real Excel and PowerFx formulas, where LaMirage outperforms all baselines. We release these benchmarks to encourage subsequent work in low-code domains.
Context2Name: A Deep Learning-Based Approach to Infer Natural Variable Names from Usage Contexts
Aug 31, 2018

Most of the JavaScript code deployed in the wild has been minified, a process in which identifier names are replaced with short, arbitrary and meaningless names. Minified code occupies less space, but also makes the code extremely difficult to manually inspect and understand. This paper presents Context2Name, a deep learningbased technique that partially reverses the effect of minification by predicting natural identifier names for minified names. The core idea is to predict from the usage context of a variable a name that captures the meaning of the variable. The approach combines a lightweight, token-based static analysis with an auto-encoder neural network that summarizes usage contexts and a recurrent neural network that predict natural names for a given usage context. We evaluate Context2Name with a large corpus of real-world JavaScript code and show that it successfully predicts 47.5% of all minified identifiers while taking only 2.9 milliseconds on average to predict a name. A comparison with the state-of-the-art tools JSNice and JSNaughty shows that our approach performs comparably in terms of accuracy while improving in terms of efficiency. Moreover, Context2Name complements the state-of-the-art by predicting 5.3% additional identifiers that are missed by both existing tools.