 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Accurate Decision Trees with Bandit Feedback via Quantized Gradient Descent
Feb 15, 2021

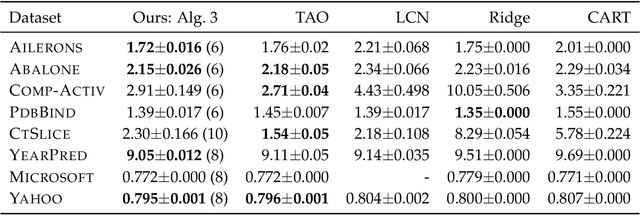
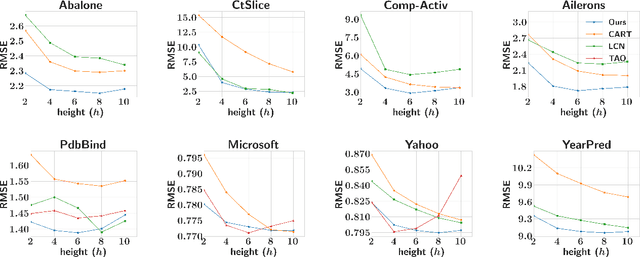
Decision trees provide a rich family of highly non-linear but efficient models, due to which they continue to be the go-to family of predictive models by practitioners across domains. But learning trees is a challenging problem due to their highly discrete and non-differentiable decision boundaries. The state-of-the-art techniques use greedy methods that exploit the discrete tree structure but are tailored to specific problem settings (say, categorical vs real-valued predictions). In this work, we propose a reformulation of the tree learning problem that provides better conditioned gradients, and leverages successful deep network learning techniques like overparameterization and straight-through estimators. Our reformulation admits an efficient and {\em accurate} gradient-based algorithm that allows us to deploy our solution in disparate tree learning settings like supervised batch learning and online bandit feedback based learning. Using extensive validation on standard benchmarks, we observe that in the supervised learning setting, our general method is competitive to, and in some cases more accurate than, existing methods that are designed {\em specifically} for the supervised settings. In contrast, for bandit settings, where most of the existing techniques are not applicable, our models are still accurate and significantly outperform the applicable state-of-the-art methods.
Programming by Rewards
Jul 14, 2020



We formalize and study ``programming by rewards'' (PBR), a new approach for specifying and synthesizing subroutines for optimizing some quantitative metric such as performance, resource utilization, or correctness over a benchmark. A PBR specification consists of (1) input features $x$, and (2) a reward function $r$, modeled as a black-box component (which we can only run), that assigns a reward for each execution. The goal of the synthesizer is to synthesize a "decision function" $f$ which transforms the features to a decision value for the black-box component so as to maximize the expected reward $E[r \circ f (x)]$ for executing decisions $f(x)$ for various values of $x$. We consider a space of decision functions in a DSL of loop-free if-then-else programs, which can branch on linear functions of the input features in a tree-structure and compute a linear function of the inputs in the leaves of the tree. We find that this DSL captures decision functions that are manually written in practice by programmers. Our technical contribution is the use of continuous-optimization techniques to perform synthesis of such decision functions as if-then-else programs. We also show that the framework is theoretically-founded ---in cases when the rewards satisfy nice properties, the synthesized code is optimal in a precise sense. We have leveraged PBR to synthesize non-trivial decision functions related to search and ranking heuristics in the PROSE codebase (an industrial strength program synthesis framework) and achieve competitive results to manually written procedures over multiple man years of tuning. We present empirical evaluation against other baseline techniques over real-world case studies (including PROSE) as well on simple synthetic benchmarks.