 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Accurate Decision Trees with Bandit Feedback via Quantized Gradient Descent
Paper and Code


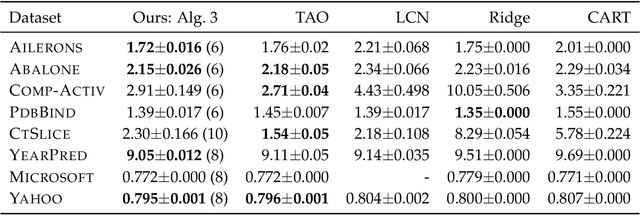
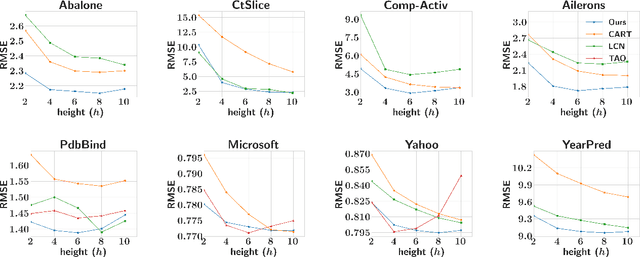
Decision trees provide a rich family of highly non-linear but efficient models, due to which they continue to be the go-to family of predictive models by practitioners across domains. But learning trees is a challenging problem due to their highly discrete and non-differentiable decision boundaries. The state-of-the-art techniques use greedy methods that exploit the discrete tree structure but are tailored to specific problem settings (say, categorical vs real-valued predictions). In this work, we propose a reformulation of the tree learning problem that provides better conditioned gradients, and leverages successful deep network learning techniques like overparameterization and straight-through estimators. Our reformulation admits an efficient and {\em accurate} gradient-based algorithm that allows us to deploy our solution in disparate tree learning settings like supervised batch learning and online bandit feedback based learning. Using extensive validation on standard benchmarks, we observe that in the supervised learning setting, our general method is competitive to, and in some cases more accurate than, existing methods that are designed {\em specifically} for the supervised settings. In contrast, for bandit settings, where most of the existing techniques are not applicable, our models are still accurate and significantly outperform the applicable state-of-the-art methods.