 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Reliable Arithmetic Multipliers Under NBTI Aging and Process Variations
May 18, 2026Hardware aging poses a significant challenge for integrated circuits (ICs), leading to performance degradation and eventual failure. In this work, we focus on the aging of arithmetic multipliers, which are a cornerstone of modern computing systems including in CPUs, GPUs, and FPGAs, as well as AI accelerators like systolic arrays. In particular, AI workloads, which rely predominantly on multiplications, can accelerate Negative Bias Temperature Instability (NBTI) effects in multipliers. This paper presents a novel aging mitigation technique that leverages the signinvariance property of multiplication. By selectively applying 2s complement transformations to inputs, the method redistributes stress across transistors, reducing the effects of NBTI aging. The proposed method is also integrated into systolic arrays, a common AI accelerator, to demonstrate its efficiency in a high-throughput AI accelerator. Experimental evaluations using Cadence tools show better lifetime compared to natural aging (with no mitigation) baseline, while introducing negligible area and delay overheads.
FARe: Fault-Aware GNN Training on ReRAM-based PIM Accelerators
Jan 19, 2024


Resistive random-access memory (ReRAM)-based processing-in-memory (PIM) architecture is an attractive solution for training Graph Neural Networks (GNNs) on edge platforms. However, the immature fabrication process and limited write endurance of ReRAMs make them prone to hardware faults, thereby limiting their widespread adoption for GNN training. Further, the existing fault-tolerant solutions prove inadequate for effectively training GNNs in the presence of faults. In this paper, we propose a fault-aware framework referred to as FARe that mitigates the effect of faults during GNN training. FARe outperforms existing approaches in terms of both accuracy and timing overhead. Experimental results demonstrate that FARe framework can restore GNN test accuracy by 47.6% on faulty ReRAM hardware with a ~1% timing overhead compared to the fault-free counterpart.
Learning-based Application-Agnostic 3D NoC Design for Heterogeneous Manycore Systems
Oct 20, 2018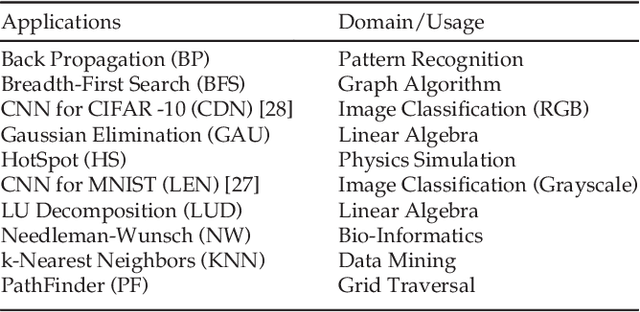
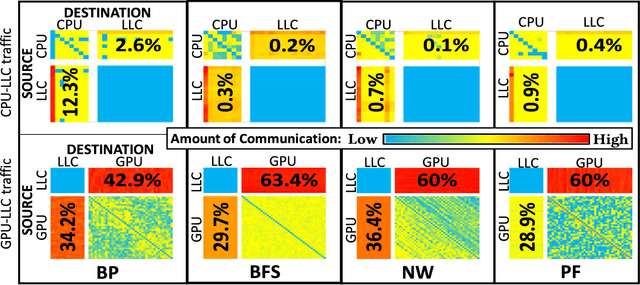
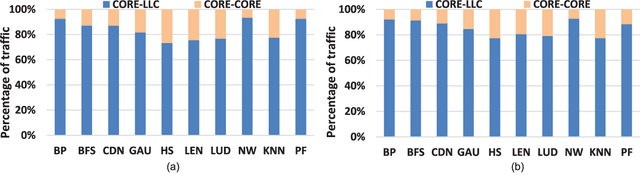
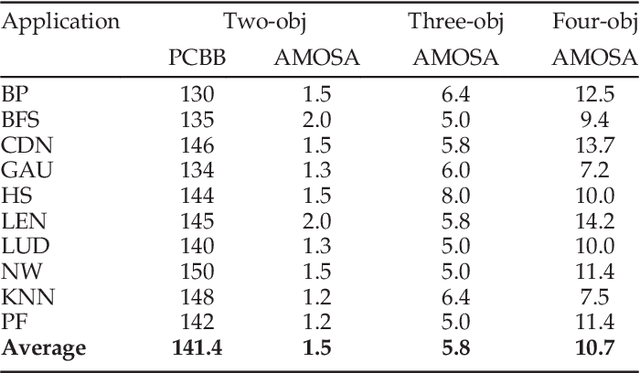
The rising use of deep learning and other big-data algorithms has led to an increasing demand for hardware platforms that are computationally powerful, yet energy-efficient. Due to the amount of data parallelism in these algorithms, high-performance 3D manycore platforms that incorporate both CPUs and GPUs present a promising direction. However, as systems use heterogeneity (e.g., a combination of CPUs, GPUs, and accelerators) to improve performance and efficiency, it becomes more pertinent to address the distinct and likely conflicting communication requirements (e.g., CPU memory access latency or GPU network throughput) that arise from such heterogeneity. Unfortunately, it is difficult to quickly explore the hardware design space and choose appropriate tradeoffs between these heterogeneous requirements. To address these challenges, we propose the design of a 3D Network-on-Chip (NoC) for heterogeneous manycore platforms that considers the appropriate design objectives for a 3D heterogeneous system and explores various tradeoffs using an efficient ML-based multi-objective optimization technique. The proposed design space exploration considers the various requirements of its heterogeneous components and generates a set of 3D NoC architectures that efficiently trades off these design objectives. Our findings show that by jointly considering these requirements (latency, throughput, temperature, and energy), we can achieve 9.6% better Energy-Delay Product on average at nearly iso-temperature conditions when compared to a thermally-optimized design for 3D heterogeneous NoCs. More importantly, our results suggest that our 3D NoCs optimized for a few applications can be generalized for unknown applications as well. Our results show that these generalized 3D NoCs only incur a 1.8% (36-tile system) and 1.1% (64-tile system) average performance loss compared to application-specific NoCs.