 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOELA: A Multi-Objective Evolutionary/Learning Design Space Exploration Framework for 3D Heterogeneous Manycore Platforms
Mar 10, 2023



To enable emerging applications such as deep machine learning and graph processing, 3D network-on-chip (NoC) enabled heterogeneous manycore platforms that can integrate many processing elements (PEs) are needed. However, designing such complex systems with multiple objectives can be challenging due to the huge associated design space and long evaluation times. To optimize such systems, we propose a new multi-objective design space exploration framework called MOELA that combines the benefits of evolutionary-based search with a learning-based local search to quickly determine PE and communication link placement to optimize multiple objectives (e.g., latency, throughput, and energy) in 3D NoC enabled heterogeneous manycore systems. Compared to state-of-the-art approaches, MOELA increases the speed of finding solutions by up to 128x, leads to a better Pareto Hypervolume (PHV) by up to 12.14x and improves energy-delay-product (EDP) by up to 7.7% in a 5-objective scenario.
RACE: A Reinforcement Learning Framework for Improved Adaptive Control of NoC Channel Buffers
May 26, 2022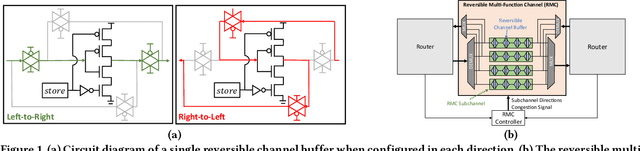


Network-on-chip (NoC) architectures rely on buffers to store flits to cope with contention for router resources during packet switching. Recently, reversible multi-function channel (RMC) buffers have been proposed to simultaneously reduce power and enable adaptive NoC buffering between adjacent routers. While adaptive buffering can improve NoC performance by maximizing buffer utilization, controlling the RMC buffer allocations requires a congestion-aware, scalable, and proactive policy. In this work, we present RACE, a novel reinforcement learning (RL) framework that utilizes better awareness of network congestion and a new reward metric ("falsefulls") to help guide the RL agent towards better RMC buffer control decisions. We show that RACE reduces NoC latency by up to 48.9%, and energy consumption by up to 47.1% against state-of-the-art NoC buffer control policies.
Learning-based Application-Agnostic 3D NoC Design for Heterogeneous Manycore Systems
Oct 20, 2018
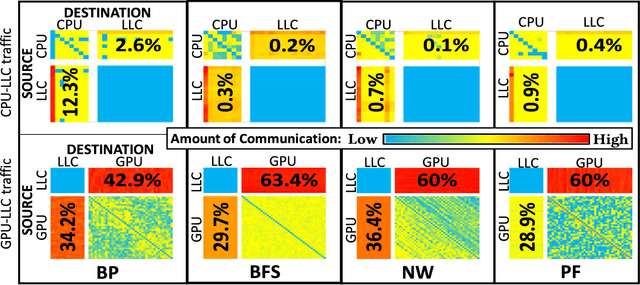
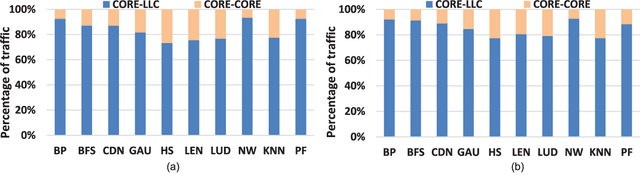
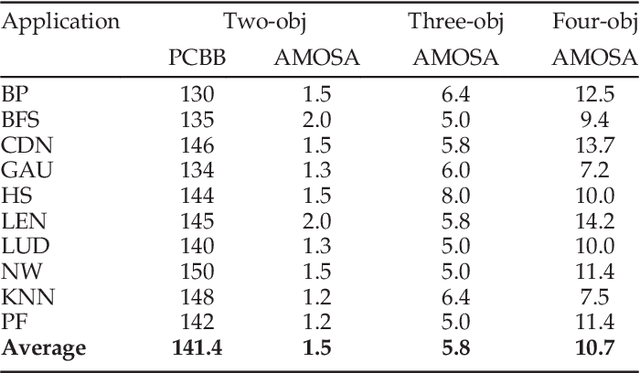
The rising use of deep learning and other big-data algorithms has led to an increasing demand for hardware platforms that are computationally powerful, yet energy-efficient. Due to the amount of data parallelism in these algorithms, high-performance 3D manycore platforms that incorporate both CPUs and GPUs present a promising direction. However, as systems use heterogeneity (e.g., a combination of CPUs, GPUs, and accelerators) to improve performance and efficiency, it becomes more pertinent to address the distinct and likely conflicting communication requirements (e.g., CPU memory access latency or GPU network throughput) that arise from such heterogeneity. Unfortunately, it is difficult to quickly explore the hardware design space and choose appropriate tradeoffs between these heterogeneous requirements. To address these challenges, we propose the design of a 3D Network-on-Chip (NoC) for heterogeneous manycore platforms that considers the appropriate design objectives for a 3D heterogeneous system and explores various tradeoffs using an efficient ML-based multi-objective optimization technique. The proposed design space exploration considers the various requirements of its heterogeneous components and generates a set of 3D NoC architectures that efficiently trades off these design objectives. Our findings show that by jointly considering these requirements (latency, throughput, temperature, and energy), we can achieve 9.6% better Energy-Delay Product on average at nearly iso-temperature conditions when compared to a thermally-optimized design for 3D heterogeneous NoCs. More importantly, our results suggest that our 3D NoCs optimized for a few applications can be generalized for unknown applications as well. Our results show that these generalized 3D NoCs only incur a 1.8% (36-tile system) and 1.1% (64-tile system) average performance loss compared to application-specific NoCs.
Machine Learning and Manycore Systems Design: A Serendipitous Symbiosis
Nov 30, 2017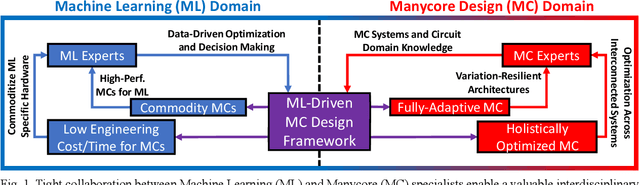

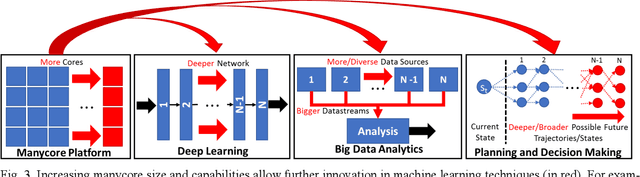
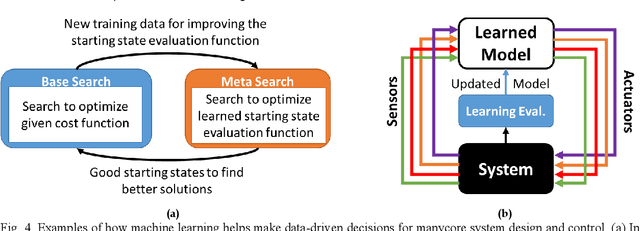
Tight collaboration between experts of machine learning and manycore system design is necessary to create a data-driven manycore design framework that integrates both learning and expert knowledge. Such a framework will be necessary to address the rising complexity of designing large-scale manycore systems and machine learning techniques.