 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying Node-based Core Resilience
Jun 21, 2023
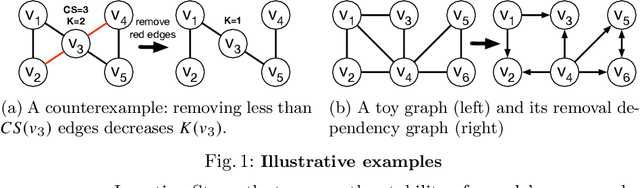
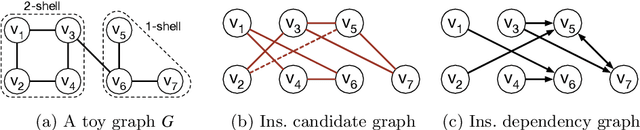
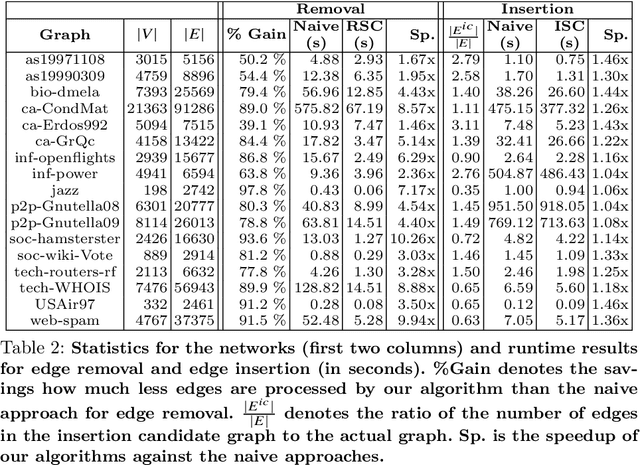
Core decomposition is an efficient building block for various graph analysis tasks such as dense subgraph discovery and identifying influential nodes. One crucial weakness of the core decomposition is its sensitivity to changes in the graph: inserting or removing a few edges can drastically change the core structure of a graph. Hence, it is essential to characterize, quantify, and, if possible, improve the resilience of the core structure of a given graph in global and local levels. Previous works mostly considered the core resilience of the entire graph or important subgraphs in it. In this work, we study node-based core resilience measures upon edge removals and insertions. We first show that a previously proposed measure, Core Strength, does not correctly capture the core resilience of a node upon edge removals. Next, we introduce the concept of dependency graph to capture the impact of neighbor nodes (for edge removal) and probable future neighbor nodes (for edge insertion) on the core number of a given node. Accordingly, we define Removal Strength and Insertion Strength measures to capture the resilience of an individual node upon removing and inserting an edge, respectively. As naive computation of those measures is costly, we provide efficient heuristics built on key observations about the core structure. We consider two key applications, finding critical edges and identifying influential spreaders, to demonstrate the usefulness of our new measures on various real-world networks and against several baselines. We also show that our heuristic algorithms are more efficient than the naive approaches.
On Measuring the Diversity of Organizational Networks
May 14, 2021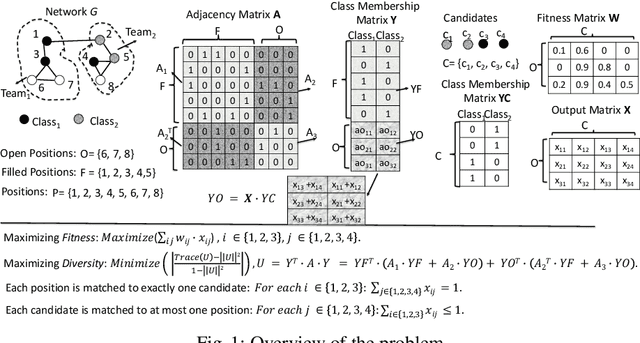
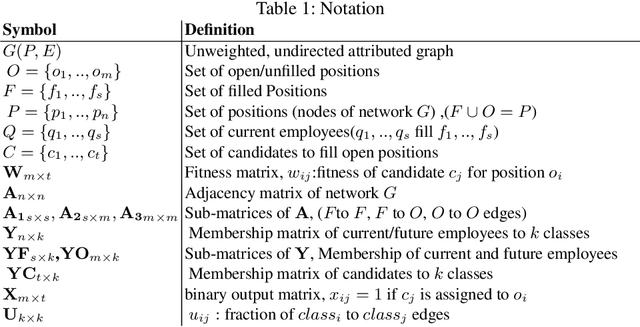
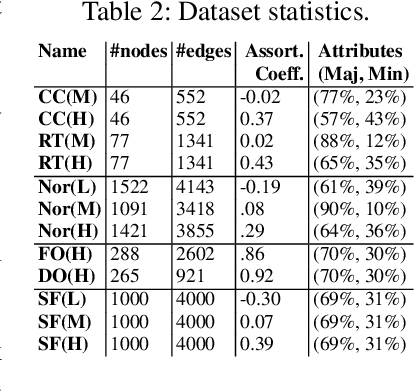

The interaction patterns of employees in social and professional networks play an important role in the success of employees and organizations as a whole. However, in many fields there is a severe under-representation of minority groups; moreover, minority individuals may be segregated from the rest of the network or isolated from one another. While the problem of increasing the representation of minority groups in various fields has been well-studied, diver- sification in terms of numbers alone may not be sufficient: social relationships should also be considered. In this work, we consider the problem of assigning a set of employment candidates to positions in a social network so that diversity and overall fitness are maximized, and propose Fair Employee Assignment (FairEA), a novel algorithm for finding such a matching. The output from FairEA can be used as a benchmark by organizations wishing to evaluate their hiring and assignment practices. On real and synthetic networks, we demonstrate that FairEA does well at finding high-fitness, high-diversity matchings.
An Ultra-Efficient Memristor-Based DNN Framework with Structured Weight Pruning and Quantization Using ADMM
Aug 29, 2019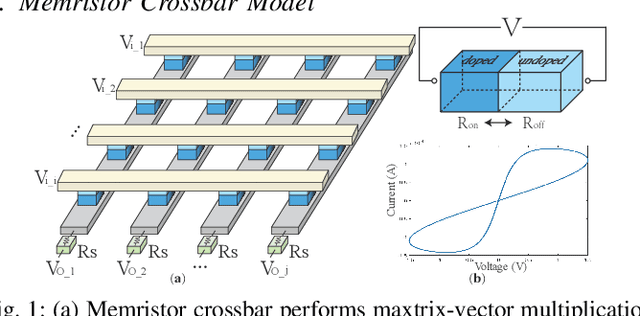
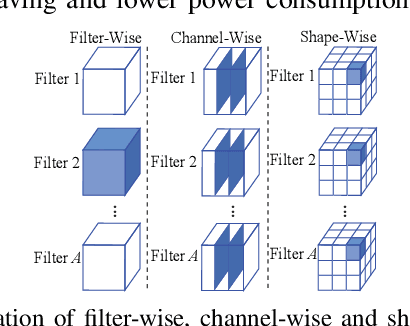
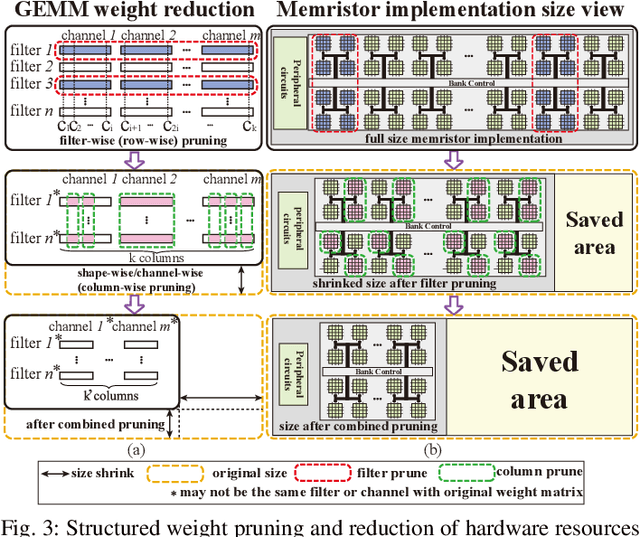
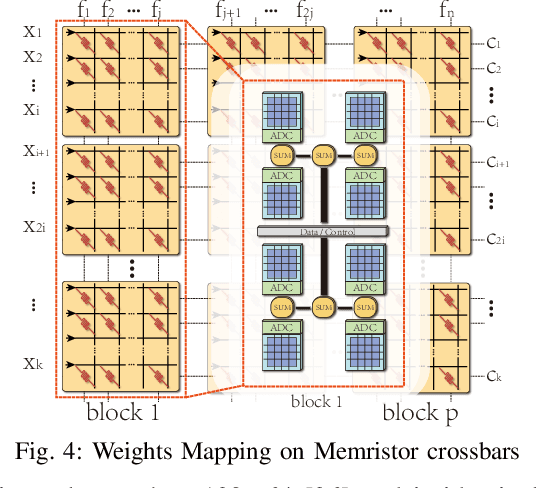
The high computation and memory storage of large deep neural networks (DNNs) models pose intensive challenges to the conventional Von-Neumann architecture, incurring substantial data movements in the memory hierarchy. The memristor crossbar array has emerged as a promising solution to mitigate the challenges and enable low-power acceleration of DNNs. Memristor-based weight pruning and weight quantization have been seperately investigated and proven effectiveness in reducing area and power consumption compared to the original DNN model. However, there has been no systematic investigation of memristor-based neuromorphic computing (NC) systems considering both weight pruning and weight quantization. In this paper, we propose an unified and systematic memristor-based framework considering both structured weight pruning and weight quantization by incorporating alternating direction method of multipliers (ADMM) into DNNs training. We consider hardware constraints such as crossbar blocks pruning, conductance range, and mismatch between weight value and real devices, to achieve high accuracy and low power and small area footprint. Our framework is mainly integrated by three steps, i.e., memristor-based ADMM regularized optimization, masked mapping and retraining. Experimental results show that our proposed framework achieves 29.81X (20.88X) weight compression ratio, with 98.38% (96.96%) and 98.29% (97.47%) power and area reduction on VGG-16 (ResNet-18) network where only have 0.5% (0.76%) accuracy loss, compared to the original DNN models. We share our models at link http://bit.ly/2Jp5LHJ.
Predicting Graph Categories from Structural Properties
May 07, 2018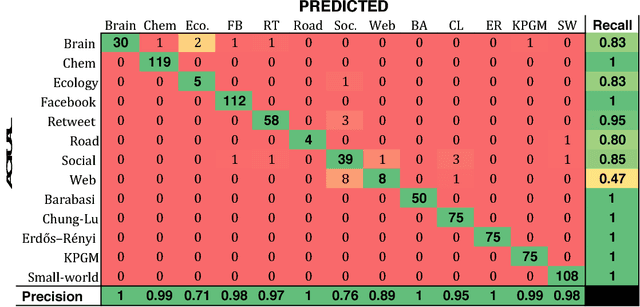
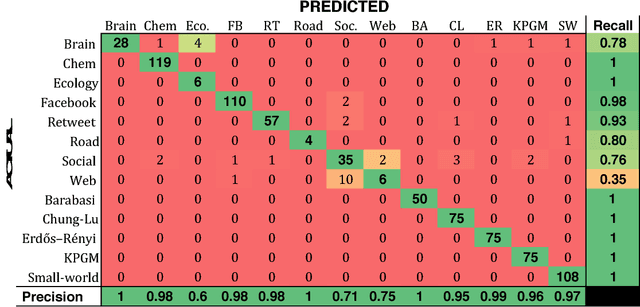
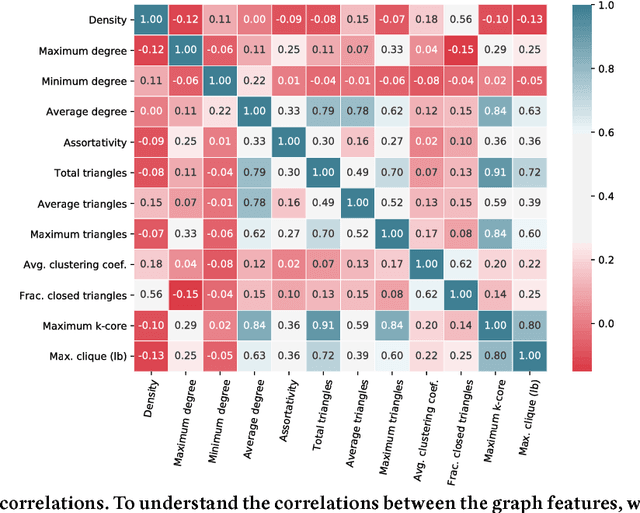
Complex networks are often categorized according to the underlying phenomena that they represent such as molecular interactions, re-tweets, and brain activity. In this work, we investigate the problem of predicting the category (domain) of arbitrary networks. This includes complex networks from different domains as well as synthetically generated graphs from five different network models. A classification accuracy of $96.6\%$ is achieved using a random forest classifier with both real and synthetic networks. This work makes two important findings. First, our results indicate that complex networks from various domains have distinct structural properties that allow us to predict with high accuracy the category of a new previously unseen network. Second, synthetic graphs are trivial to classify as the classification model can predict with near-certainty the network model used to generate it. Overall, the results demonstrate that networks drawn from different domains (and network models) are trivial to distinguish using only a handful of simple structural properties.
Network Classification and Categorization
Sep 13, 2017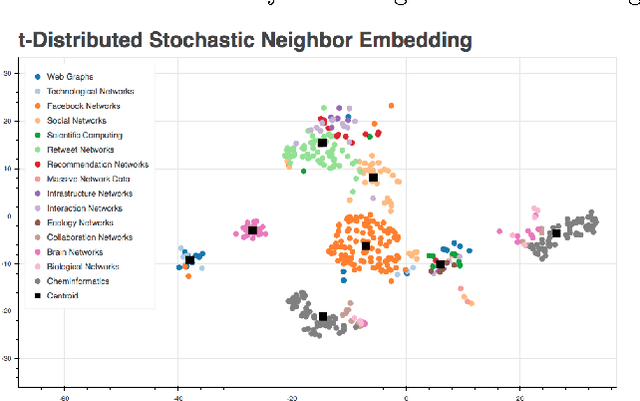
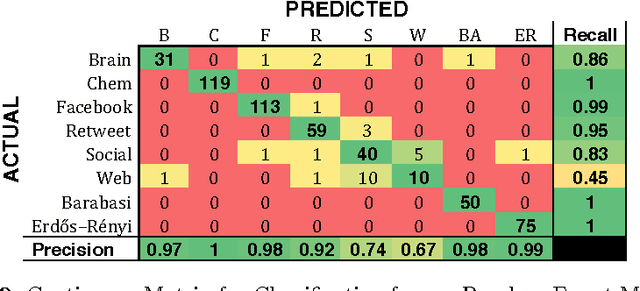
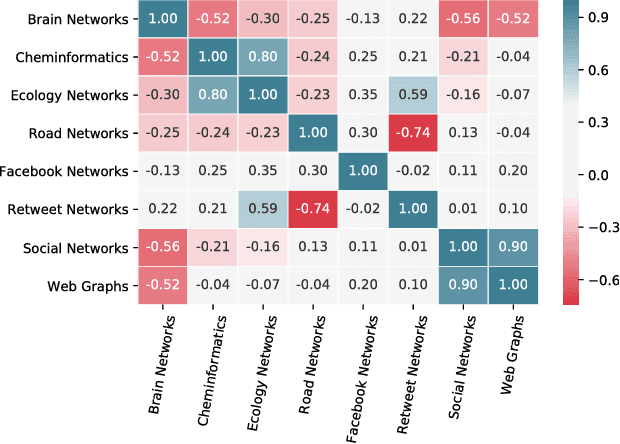
To the best of our knowledge, this paper presents the first large-scale study that tests whether network categories (e.g., social networks vs. web graphs) are distinguishable from one another (using both categories of real-world networks and synthetic graphs). A classification accuracy of $94.2\%$ was achieved using a random forest classifier with both real and synthetic networks. This work makes two important findings. First, real-world networks from various domains have distinct structural properties that allow us to predict with high accuracy the category of an arbitrary network. Second, classifying synthetic networks is trivial as our models can easily distinguish between synthetic graphs and the real-world networks they are supposed to model.
Hidden Community Detection in Social Networks
Feb 24, 2017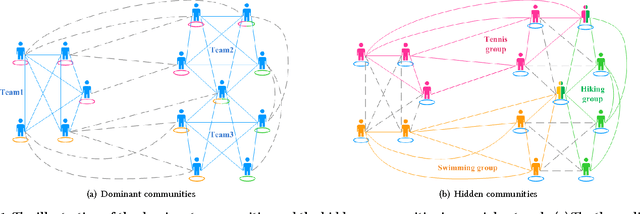
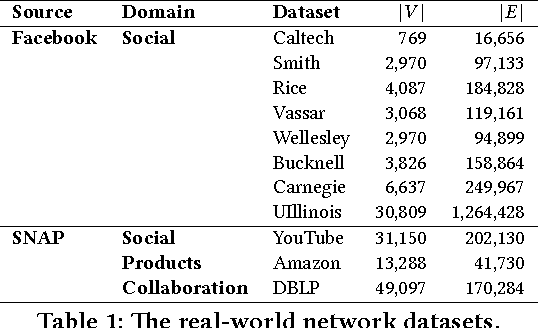
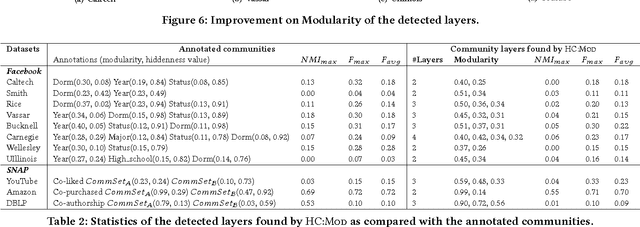
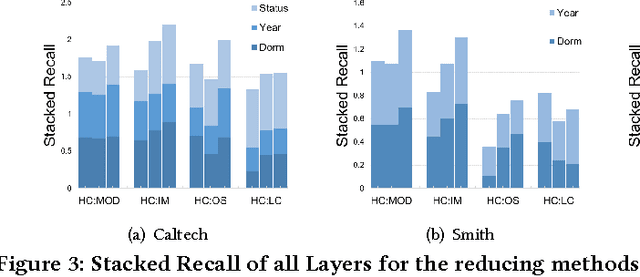
We introduce a new paradigm that is important for community detection in the realm of network analysis. Networks contain a set of strong, dominant communities, which interfere with the detection of weak, natural community structure. When most of the members of the weak communities also belong to stronger communities, they are extremely hard to be uncovered. We call the weak communities the hidden community structure. We present a novel approach called HICODE (HIdden COmmunity DEtection) that identifies the hidden community structure as well as the dominant community structure. By weakening the strength of the dominant structure, one can uncover the hidden structure beneath. Likewise, by reducing the strength of the hidden structure, one can more accurately identify the dominant structure. In this way, HICODE tackles both tasks simultaneously. Extensive experiments on real-world networks demonstrate that HICODE outperforms several state-of-the-art community detection methods in uncovering both the dominant and the hidden structure. In the Facebook university social networks, we find multiple non-redundant sets of communities that are strongly associated with residential hall, year of registration or career position of the faculties or students, while the state-of-the-art algorithms mainly locate the dominant ground truth category. In the Due to the difficulty of labeling all ground truth communities in real-world datasets, HICODE provides a promising approach to pinpoint the existing latent communities and uncover communities for which there is no ground truth. Finding this unknown structure is an extremely important community detection problem.