 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Graph Categories from Structural Properties
May 07, 2018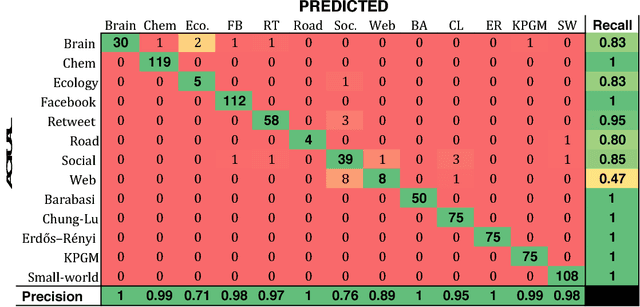
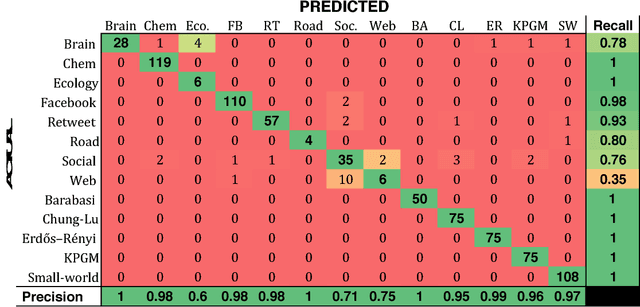
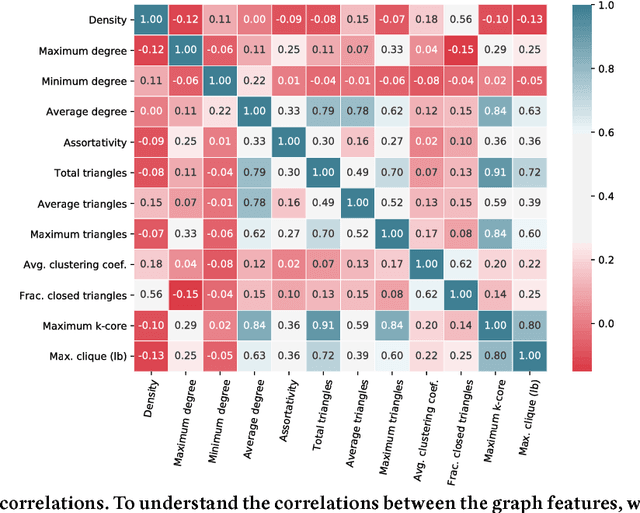
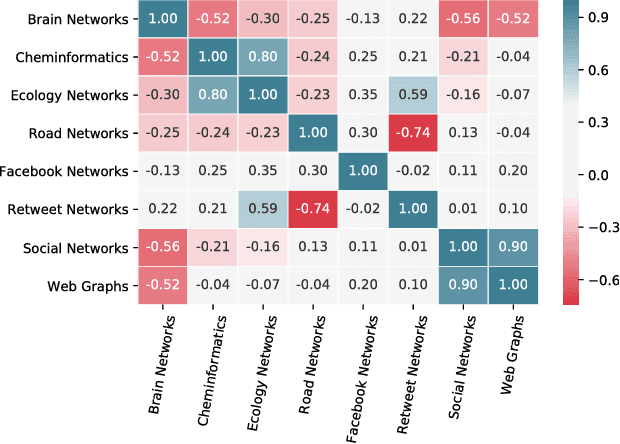
Complex networks are often categorized according to the underlying phenomena that they represent such as molecular interactions, re-tweets, and brain activity. In this work, we investigate the problem of predicting the category (domain) of arbitrary networks. This includes complex networks from different domains as well as synthetically generated graphs from five different network models. A classification accuracy of $96.6\%$ is achieved using a random forest classifier with both real and synthetic networks. This work makes two important findings. First, our results indicate that complex networks from various domains have distinct structural properties that allow us to predict with high accuracy the category of a new previously unseen network. Second, synthetic graphs are trivial to classify as the classification model can predict with near-certainty the network model used to generate it. Overall, the results demonstrate that networks drawn from different domains (and network models) are trivial to distinguish using only a handful of simple structural properties.
Network Classification and Categorization
Sep 13, 2017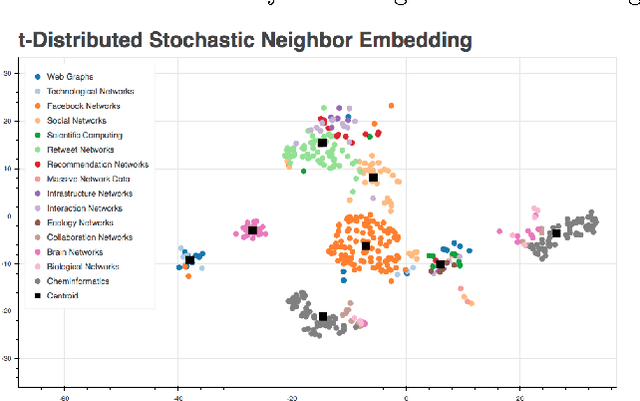
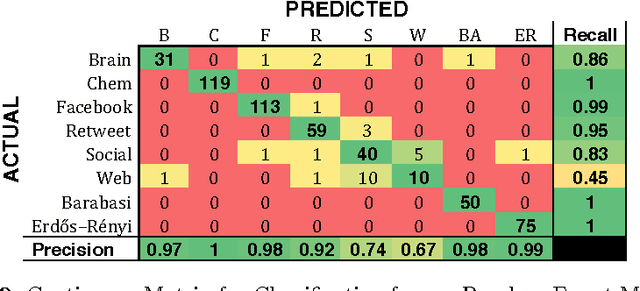
To the best of our knowledge, this paper presents the first large-scale study that tests whether network categories (e.g., social networks vs. web graphs) are distinguishable from one another (using both categories of real-world networks and synthetic graphs). A classification accuracy of $94.2\%$ was achieved using a random forest classifier with both real and synthetic networks. This work makes two important findings. First, real-world networks from various domains have distinct structural properties that allow us to predict with high accuracy the category of an arbitrary network. Second, classifying synthetic networks is trivial as our models can easily distinguish between synthetic graphs and the real-world networks they are supposed to model.