 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding and Modeling Job Marketplace with Pretrained Language Models
Aug 08, 2024Job marketplace is a heterogeneous graph composed of interactions among members (job-seekers), companies, and jobs. Understanding and modeling job marketplace can benefit both job seekers and employers, ultimately contributing to the greater good of the society. However, existing graph neural network (GNN)-based methods have shallow understandings of the associated textual features and heterogeneous relations. To address the above challenges, we propose PLM4Job, a job marketplace foundation model that tightly couples pretrained language models (PLM) with job market graph, aiming to fully utilize the pretrained knowledge and reasoning ability to model member/job textual features as well as various member-job relations simultaneously. In the pretraining phase, we propose a heterogeneous ego-graph-based prompting strategy to model and aggregate member/job textual features based on the topological structure around the target member/job node, where entity type embeddings and graph positional embeddings are introduced accordingly to model different entities and their heterogeneous relations. Meanwhile, a proximity-aware attention alignment strategy is designed to dynamically adjust the attention of the PLM on ego-graph node tokens in the prompt, such that the attention can be better aligned with job marketplace semantics. Extensive experiments at LinkedIn demonstrate the effectiveness of PLM4Job.
Learning to Retrieve for Job Matching
Feb 21, 2024



Web-scale search systems typically tackle the scalability challenge with a two-step paradigm: retrieval and ranking. The retrieval step, also known as candidate selection, often involves extracting standardized entities, creating an inverted index, and performing term matching for retrieval. Such traditional methods require manual and time-consuming development of query models. In this paper, we discuss applying learning-to-retrieve technology to enhance LinkedIns job search and recommendation systems. In the realm of promoted jobs, the key objective is to improve the quality of applicants, thereby delivering value to recruiter customers. To achieve this, we leverage confirmed hire data to construct a graph that evaluates a seeker's qualification for a job, and utilize learned links for retrieval. Our learned model is easy to explain, debug, and adjust. On the other hand, the focus for organic jobs is to optimize seeker engagement. We accomplished this by training embeddings for personalized retrieval, fortified by a set of rules derived from the categorization of member feedback. In addition to a solution based on a conventional inverted index, we developed an on-GPU solution capable of supporting both KNN and term matching efficiently.
LLM-Enhanced User-Item Interactions: Leveraging Edge Information for Optimized Recommendations
Feb 14, 2024



The extraordinary performance of large language models has not only reshaped the research landscape in the field of NLP but has also demonstrated its exceptional applicative potential in various domains. However, the potential of these models in mining relationships from graph data remains under-explored. Graph neural networks, as a popular research area in recent years, have numerous studies on relationship mining. Yet, current cutting-edge research in graph neural networks has not been effectively integrated with large language models, leading to limited efficiency and capability in graph relationship mining tasks. A primary challenge is the inability of LLMs to deeply exploit the edge information in graphs, which is critical for understanding complex node relationships. This gap limits the potential of LLMs to extract meaningful insights from graph structures, limiting their applicability in more complex graph-based analysis. We focus on how to utilize existing LLMs for mining and understanding relationships in graph data, applying these techniques to recommendation tasks. We propose an innovative framework that combines the strong contextual representation capabilities of LLMs with the relationship extraction and analysis functions of GNNs for mining relationships in graph data. Specifically, we design a new prompt construction framework that integrates relational information of graph data into natural language expressions, aiding LLMs in more intuitively grasping the connectivity information within graph data. Additionally, we introduce graph relationship understanding and analysis functions into LLMs to enhance their focus on connectivity information in graph data. Our evaluation on real-world datasets demonstrates the framework's ability to understand connectivity information in graph data.
Collaborative Large Language Model for Recommender Systems
Nov 08, 2023



Recently, there is a growing interest in developing next-generation recommender systems (RSs) based on pretrained large language models (LLMs), fully utilizing their encoded knowledge and reasoning ability. However, the semantic gap between natural language and recommendation tasks is still not well addressed, leading to multiple issues such as spuriously-correlated user/item descriptors, ineffective language modeling on user/item contents, and inefficient recommendations via auto-regression, etc. In this paper, we propose CLLM4Rec, the first generative RS that tightly integrates the LLM paradigm and ID paradigm of RS, aiming to address the above challenges simultaneously. We first extend the vocabulary of pretrained LLMs with user/item ID tokens to faithfully model the user/item collaborative and content semantics. Accordingly, in the pretraining stage, a novel soft+hard prompting strategy is proposed to effectively learn user/item collaborative/content token embeddings via language modeling on RS-specific corpora established from user-item interactions and user/item features, where each document is split into a prompt consisting of heterogeneous soft (user/item) tokens and hard (vocab) tokens and a main text consisting of homogeneous item tokens or vocab tokens that facilitates stable and effective language modeling. In addition, a novel mutual regularization strategy is introduced to encourage the CLLM4Rec to capture recommendation-oriented information from user/item contents. Finally, we propose a novel recommendation-oriented finetuning strategy for CLLM4Rec, where an item prediction head with multinomial likelihood is added to the pretrained CLLM4Rec backbone to predict hold-out items based on the soft+hard prompts established from masked user-item interaction history, where recommendations of multiple items can be generated efficiently.
Path-Specific Counterfactual Fairness for Recommender Systems
Jun 05, 2023Recommender systems (RSs) have become an indispensable part of online platforms. With the growing concerns of algorithmic fairness, RSs are not only expected to deliver high-quality personalized content, but are also demanded not to discriminate against users based on their demographic information. However, existing RSs could capture undesirable correlations between sensitive features and observed user behaviors, leading to biased recommendations. Most fair RSs tackle this problem by completely blocking the influences of sensitive features on recommendations. But since sensitive features may also affect user interests in a fair manner (e.g., race on culture-based preferences), indiscriminately eliminating all the influences of sensitive features inevitably degenerate the recommendations quality and necessary diversities. To address this challenge, we propose a path-specific fair RS (PSF-RS) for recommendations. Specifically, we summarize all fair and unfair correlations between sensitive features and observed ratings into two latent proxy mediators, where the concept of path-specific bias (PS-Bias) is defined based on path-specific counterfactual inference. Inspired by Pearl's minimal change principle, we address the PS-Bias by minimally transforming the biased factual world into a hypothetically fair world, where a fair RS model can be learned accordingly by solving a constrained optimization problem. For the technical part, we propose a feasible implementation of PSF-RS, i.e., PSF-VAE, with weakly-supervised variational inference, which robustly infers the latent mediators such that unfairness can be mitigated while necessary recommendation diversities can be maximally preserved simultaneously. Experiments conducted on semi-simulated and real-world datasets demonstrate the effectiveness of PSF-RS.
Revenue, Relevance, Arbitrage and More: Joint Optimization Framework for Search Experiences in Two-Sided Marketplaces
May 15, 2019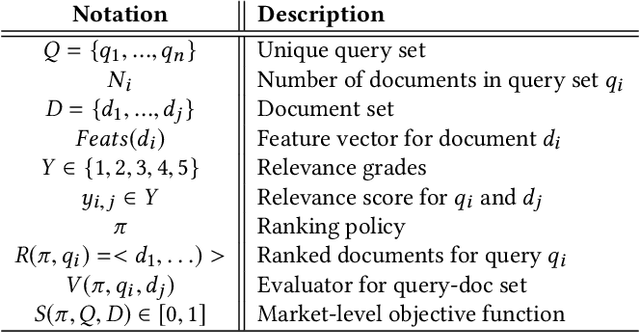
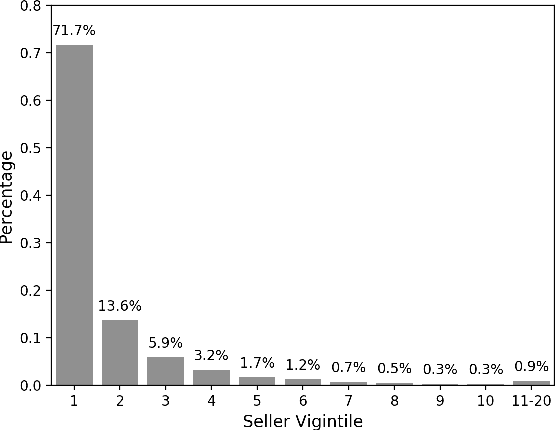
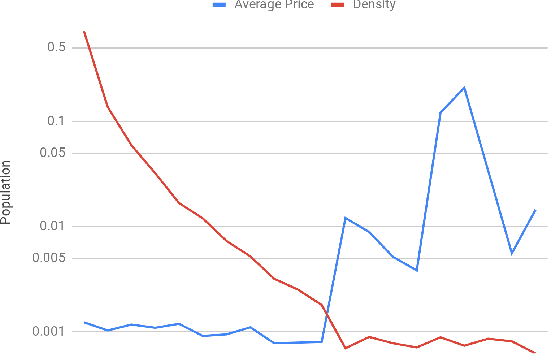
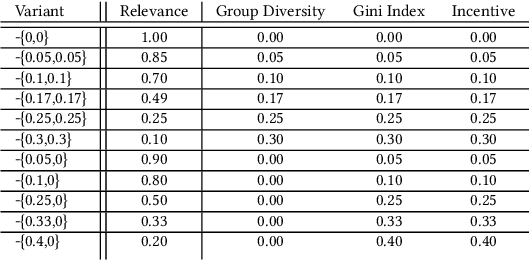
Two-sided marketplaces such as eBay, Etsy and Taobao have two distinct groups of customers: buyers who use the platform to seek the most relevant and interesting item to purchase and sellers who view the same platform as a tool to reach out to their audience and grow their business. Additionally, platforms have their own objectives ranging from growing both buyer and seller user bases to revenue maximization. It is not difficult to see that it would be challenging to obtain a globally favorable outcome for all parties. Taking the search experience as an example, any interventions are likely to impact either buyers or sellers unfairly to course correct for a greater perceived need. In this paper, we address how a company-aligned search experience can be provided with competing business metrics that E-commerce companies typically tackle. As far as we know, this is a pioneering work to consider multiple different aspects of business indicators in two-sided marketplaces to optimize a search experience. We demonstrate that many problems are difficult or impossible to decompose down to credit assigned scores on individual documents, rendering traditional methods inadequate. Instead, we express market-level metrics as constraints and discuss to what degree multiple potentially conflicting metrics can be tuned to business needs. We further explore the use of policy learners in the form of Evolutionary Strategies to jointly optimize both group-level and market-level metrics simultaneously, side-stepping traditional cascading methods and manual interventions. We empirically evaluate the effectiveness of the proposed method on Etsy data and demonstrate its potential with insights.
Learning Item-Interaction Embeddings for User Recommendations
Dec 11, 2018
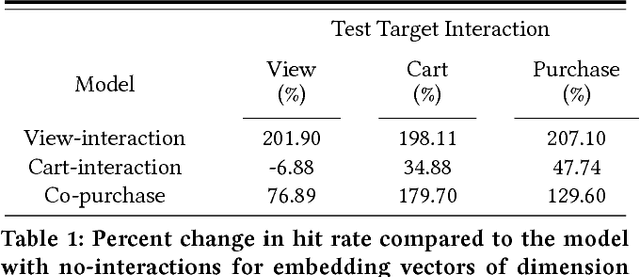
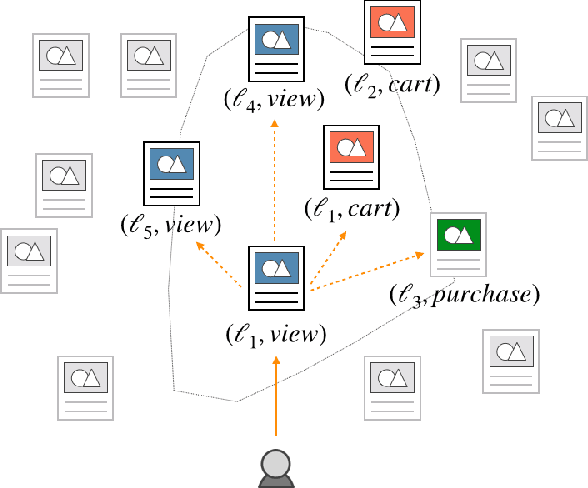
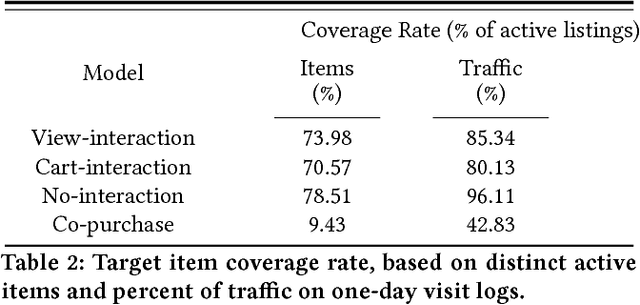
Industry-scale recommendation systems have become a cornerstone of the e-commerce shopping experience. For Etsy, an online marketplace with over 50 million handmade and vintage items, users come to rely on personalized recommendations to surface relevant items from its massive inventory. One hallmark of Etsy's shopping experience is the multitude of ways in which a user can interact with an item they are interested in: they can view it, favorite it, add it to a collection, add it to cart, purchase it, etc. We hypothesize that the different ways in which a user interacts with an item indicates different kinds of intent. Consequently, a user's recommendations should be based not only on the item from their past activity, but also the way in which they interacted with that item. In this paper, we propose a novel method for learning interaction-based item embeddings that encode the co-occurrence patterns of not only the item itself, but also the interaction type. The learned embeddings give us a convenient way of approximating the likelihood that one item-interaction pair would co-occur with another by way of a simple inner product. Because of its computational efficiency, our model lends itself naturally as a candidate set selection method, and we evaluate it as such in an industry-scale recommendation system that serves live traffic on Etsy.com. Our experiments reveal that taking interaction type into account shows promising results in improving the accuracy of modeling user shopping behavior.
On Sampling Strategies for Neural Network-based Collaborative Filtering
Jun 23, 2017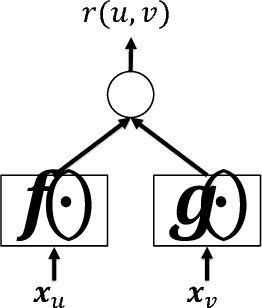
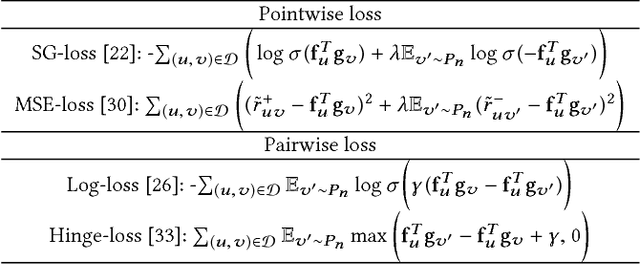
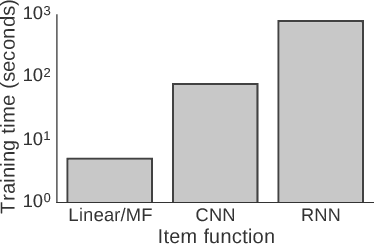

Recent advances in neural networks have inspired people to design hybrid recommendation algorithms that can incorporate both (1) user-item interaction information and (2) content information including image, audio, and text. Despite their promising results, neural network-based recommendation algorithms pose extensive computational costs, making it challenging to scale and improve upon. In this paper, we propose a general neural network-based recommendation framework, which subsumes several existing state-of-the-art recommendation algorithms, and address the efficiency issue by investigating sampling strategies in the stochastic gradient descent training for the framework. We tackle this issue by first establishing a connection between the loss functions and the user-item interaction bipartite graph, where the loss function terms are defined on links while major computation burdens are located at nodes. We call this type of loss functions "graph-based" loss functions, for which varied mini-batch sampling strategies can have different computational costs. Based on the insight, three novel sampling strategies are proposed, which can significantly improve the training efficiency of the proposed framework (up to $\times 30$ times speedup in our experiments), as well as improving the recommendation performance. Theoretical analysis is also provided for both the computational cost and the convergence. We believe the study of sampling strategies have further implications on general graph-based loss functions, and would also enable more research under the neural network-based recommendation framework.
Joint Text Embedding for Personalized Content-based Recommendation
Jun 23, 2017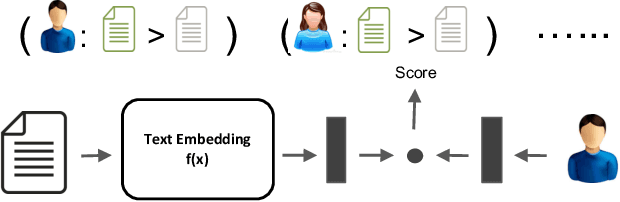
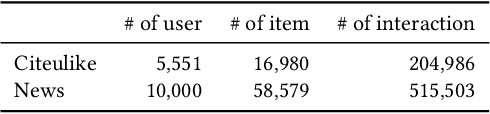


Learning a good representation of text is key to many recommendation applications. Examples include news recommendation where texts to be recommended are constantly published everyday. However, most existing recommendation techniques, such as matrix factorization based methods, mainly rely on interaction histories to learn representations of items. While latent factors of items can be learned effectively from user interaction data, in many cases, such data is not available, especially for newly emerged items. In this work, we aim to address the problem of personalized recommendation for completely new items with text information available. We cast the problem as a personalized text ranking problem and propose a general framework that combines text embedding with personalized recommendation. Users and textual content are embedded into latent feature space. The text embedding function can be learned end-to-end by predicting user interactions with items. To alleviate sparsity in interaction data, and leverage large amount of text data with little or no user interactions, we further propose a joint text embedding model that incorporates unsupervised text embedding with a combination module. Experimental results show that our model can significantly improve the effectiveness of recommendation systems on real-world datasets.
An Unbiased Data Collection and Content Exploitation/Exploration Strategy for Personalization
Apr 12, 2016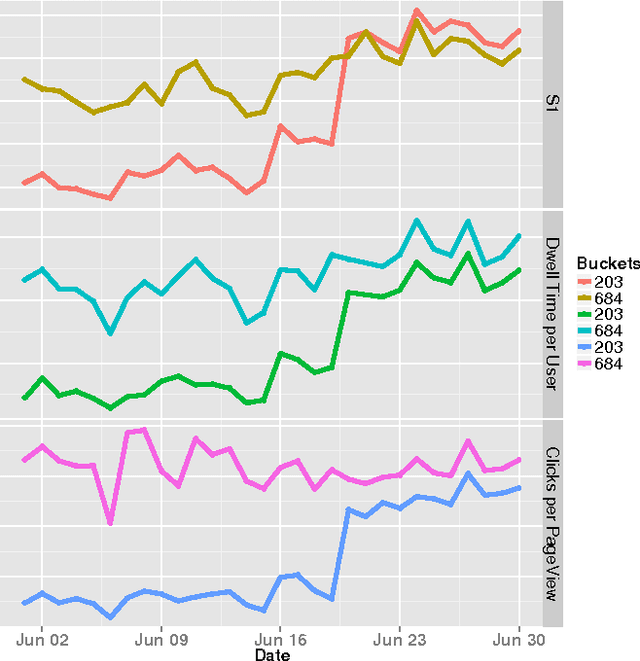
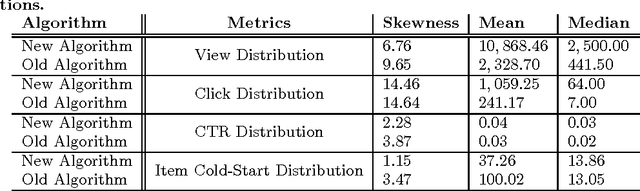
One of missions for personalization systems and recommender systems is to show content items according to users' personal interests. In order to achieve such goal, these systems are learning user interests over time and trying to present content items tailoring to user profiles. Recommending items according to users' preferences has been investigated extensively in the past few years, mainly thanks for the popularity of Netflix competition. In a real setting, users may be attracted by a subset of those items and interact with them, only leaving partial feedbacks to the system to learn in the next cycle, which leads to significant biases into systems and hence results in a situation where user engagement metrics cannot be improved over time. The problem is not just for one component of the system. The data collected from users is usually used in many different tasks, including learning ranking functions, building user profiles and constructing content classifiers. Once the data is biased, all these downstream use cases would be impacted as well. Therefore, it would be beneficial to gather unbiased data through user interactions. Traditionally, unbiased data collection is done through showing items uniformly sampling from the content pool. However, this simple scheme is not feasible as it risks user engagement metrics and it takes long time to gather user feedbacks. In this paper, we introduce a user-friendly unbiased data collection framework, by utilizing methods developed in the exploitation and exploration literature. We discuss how the framework is different from normal multi-armed bandit problems and why such method is needed. We layout a novel Thompson sampling for Bernoulli ranked-list to effectively balance user experiences and data collection. The proposed method is validated from a real bucket test and we show strong results comparing to old algorithms