 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Scale Retrieval for the LinkedIn Feed using Causal Language Models
Oct 16, 2025


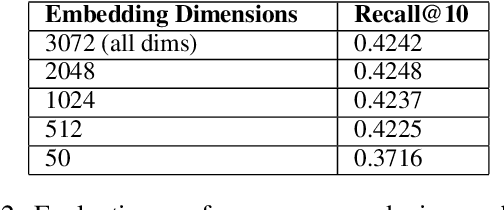
In large scale recommendation systems like the LinkedIn Feed, the retrieval stage is critical for narrowing hundreds of millions of potential candidates to a manageable subset for ranking. LinkedIn's Feed serves suggested content from outside of the member's network (based on the member's topical interests), where 2000 candidates are retrieved from a pool of hundreds of millions candidate with a latency budget of a few milliseconds and inbound QPS of several thousand per second. This paper presents a novel retrieval approach that fine-tunes a large causal language model (Meta's LLaMA 3) as a dual encoder to generate high quality embeddings for both users (members) and content (items), using only textual input. We describe the end to end pipeline, including prompt design for embedding generation, techniques for fine-tuning at LinkedIn's scale, and infrastructure for low latency, cost effective online serving. We share our findings on how quantizing numerical features in the prompt enables the information to get properly encoded in the embedding, facilitating greater alignment between the retrieval and ranking layer. The system was evaluated using offline metrics and an online A/B test, which showed substantial improvements in member engagement. We observed significant gains among newer members, who often lack strong network connections, indicating that high-quality suggested content aids retention. This work demonstrates how generative language models can be effectively adapted for real time, high throughput retrieval in industrial applications.
Trading off Relevance and Revenue in the Jobs Marketplace: Estimation, Optimization and Auction Design
Apr 04, 2025


We study the problem of position allocation in job marketplaces, where the platform determines the ranking of the jobs for each seeker. The design of ranking mechanisms is critical to marketplace efficiency, as it influences both short-term revenue from promoted job placements and long-term health through sustained seeker engagement. Our analysis focuses on the tradeoff between revenue and relevance, as well as the innovations in job auction design. We demonstrated two ways to improve relevance with minimal impact on revenue: incorporating the seekers preferences and applying position-aware auctions.
Efficient AI in Practice: Training and Deployment of Efficient LLMs for Industry Applications
Feb 20, 2025Large language models (LLMs) have demonstrated remarkable performance across a wide range of industrial applications, from search and recommendations to generative tasks. Although scaling laws indicate that larger models generally yield better generalization and performance, their substantial computational requirements often render them impractical for many real-world scenarios at scale. In this paper, we present methods and insights for training small language models (SLMs) that deliver high performance and efficiency in deployment. We focus on two key techniques: (1) knowledge distillation and (2) model compression via quantization and pruning. These approaches enable SLMs to retain much of the quality of their larger counterparts while significantly reducing training, serving costs, and latency. We detail the impact of these techniques on a variety of use cases at a large professional social network platform and share deployment lessons - including hardware optimization strategies that enhance speed and throughput for both predictive and reasoning-based applications.
360Brew: A Decoder-only Foundation Model for Personalized Ranking and Recommendation
Jan 27, 2025



Ranking and recommendation systems are the foundation for numerous online experiences, ranging from search results to personalized content delivery. These systems have evolved into complex, multilayered architectures that leverage vast datasets and often incorporate thousands of predictive models. The maintenance and enhancement of these models is a labor intensive process that requires extensive feature engineering. This approach not only exacerbates technical debt but also hampers innovation in extending these systems to emerging problem domains. In this report, we present our research to address these challenges by utilizing a large foundation model with a textual interface for ranking and recommendation tasks. We illustrate several key advantages of our approach: (1) a single model can manage multiple predictive tasks involved in ranking and recommendation, (2) decoder models with textual interface due to their comprehension of reasoning capabilities, can generalize to new recommendation surfaces and out-of-domain problems, and (3) by employing natural language interfaces for task definitions and verbalizing member behaviors and their social connections, we eliminate the need for feature engineering and the maintenance of complex directed acyclic graphs of model dependencies. We introduce our research pre-production model, 360Brew V1.0, a 150B parameter, decoder-only model that has been trained and fine-tuned on LinkedIn's data and tasks. This model is capable of solving over 30 predictive tasks across various segments of the LinkedIn platform, achieving performance levels comparable to or exceeding those of current production systems based on offline metrics, without task-specific fine-tuning. Notably, each of these tasks is conventionally addressed by dedicated models that have been developed and maintained over multiple years by teams of a similar or larger size than our own.
Understanding and Modeling Job Marketplace with Pretrained Language Models
Aug 08, 2024Job marketplace is a heterogeneous graph composed of interactions among members (job-seekers), companies, and jobs. Understanding and modeling job marketplace can benefit both job seekers and employers, ultimately contributing to the greater good of the society. However, existing graph neural network (GNN)-based methods have shallow understandings of the associated textual features and heterogeneous relations. To address the above challenges, we propose PLM4Job, a job marketplace foundation model that tightly couples pretrained language models (PLM) with job market graph, aiming to fully utilize the pretrained knowledge and reasoning ability to model member/job textual features as well as various member-job relations simultaneously. In the pretraining phase, we propose a heterogeneous ego-graph-based prompting strategy to model and aggregate member/job textual features based on the topological structure around the target member/job node, where entity type embeddings and graph positional embeddings are introduced accordingly to model different entities and their heterogeneous relations. Meanwhile, a proximity-aware attention alignment strategy is designed to dynamically adjust the attention of the PLM on ego-graph node tokens in the prompt, such that the attention can be better aligned with job marketplace semantics. Extensive experiments at LinkedIn demonstrate the effectiveness of PLM4Job.
Learning to Retrieve for Job Matching
Feb 21, 2024



Web-scale search systems typically tackle the scalability challenge with a two-step paradigm: retrieval and ranking. The retrieval step, also known as candidate selection, often involves extracting standardized entities, creating an inverted index, and performing term matching for retrieval. Such traditional methods require manual and time-consuming development of query models. In this paper, we discuss applying learning-to-retrieve technology to enhance LinkedIns job search and recommendation systems. In the realm of promoted jobs, the key objective is to improve the quality of applicants, thereby delivering value to recruiter customers. To achieve this, we leverage confirmed hire data to construct a graph that evaluates a seeker's qualification for a job, and utilize learned links for retrieval. Our learned model is easy to explain, debug, and adjust. On the other hand, the focus for organic jobs is to optimize seeker engagement. We accomplished this by training embeddings for personalized retrieval, fortified by a set of rules derived from the categorization of member feedback. In addition to a solution based on a conventional inverted index, we developed an on-GPU solution capable of supporting both KNN and term matching efficiently.